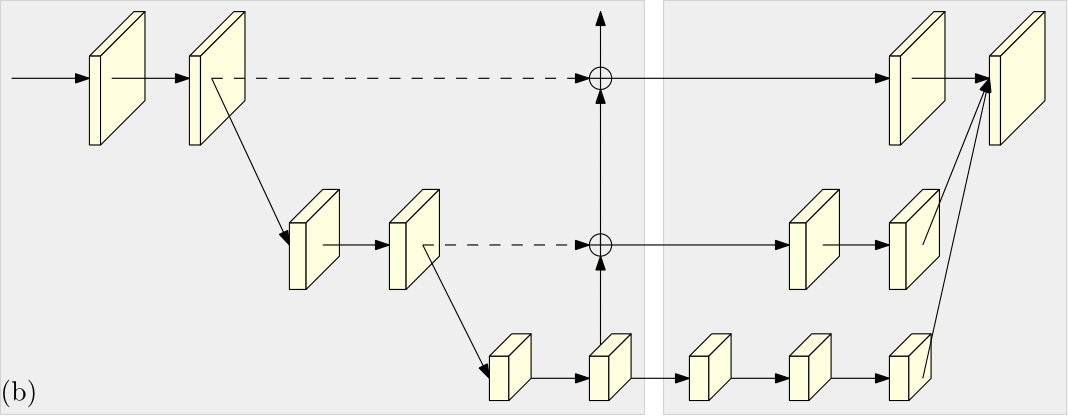
HRNet-Human-Pose-Estimation 관련 논문을 읽고 구현되어있는 코드 (출처 : github HRNet human pose estimation )를 참고하며 전체적인 흐름을 나 나름대로 정리한 글이다.
많이 부족한 티가 날 예정! 틀린 부분이 있을 수 있다ㅠㅠ
Directory
directory는
${POSE_ROOT}
├── data
├── experiments
├── lib
├── log
├── models
├── output
├── tools
├── README.md
└── requirements.txt으로 총 7개로 구성되어 있다.
1. experimants dir
먼저 experiments directory 안에는 2개의 dataset에 관련된 arguments들이 작성된 파일들을 지니고 있다.

보통 이 파일은 config뒤에 붙여져있는 파일의 주소값을 가르킨다.
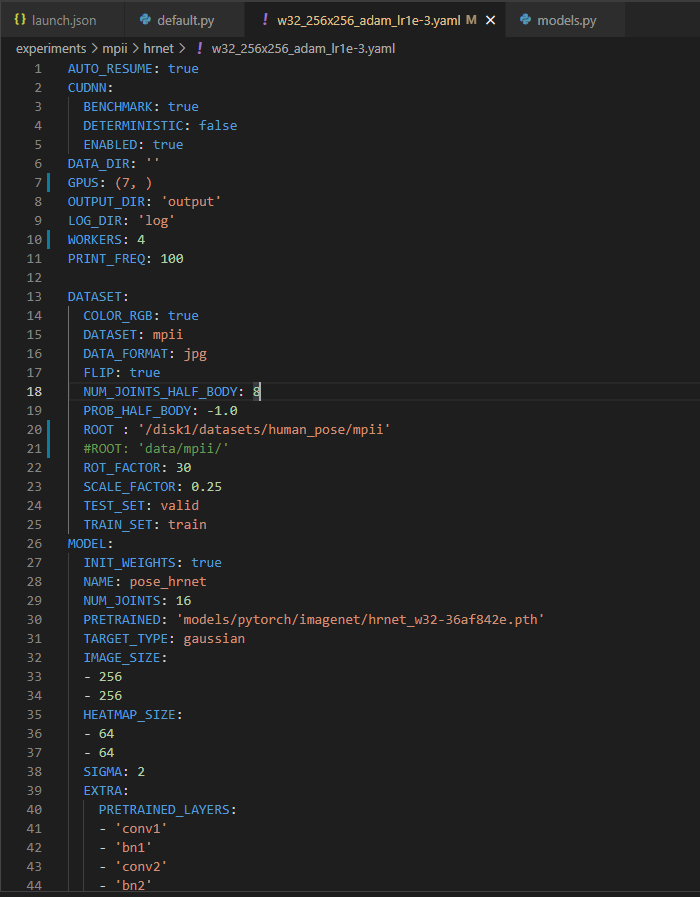
보통 이 파일에서 config의 default값 (config/default.py) 을 덮어주는 args 역할을 해주는데, dictionary 형태이며 보이는 거와 같이 GPUS, dataset의 root 등을 바꿀 수 있다.
2. lib dir
lib directory에는 다음과 같이 구성이 되어있다.
${POSE_ROOT}
├── lib
├── config
├── core
├── dataset
├── models
├── nms
├── utils
└── Makefile2-1 config dir
config directory 안에는 3개의 python file이 저장되어 있다.
${POSE_ROOT}
├── lib
├── config
├── __init__.py
├── default.py
└── models.pyinit.py
# ------------------------------------------------------------------------------
# Copyright (c) Microsoft
# Licensed under the MIT License.
# Written by Bin Xiao (Bin.Xiao@microsoft.com)
# ------------------------------------------------------------------------------
from .default import _C as cfg
from .default import update_config
from .models import MODEL_EXTRAS
아래 사용될 함수들을 정의해준다.
default.py
default.py 는 yacs.config의 CfgNode를 CN으로 불러와 사용하는데,
yacs 모듈은 링크에서 확인 할 수 있듯, 하이퍼 파라미터와 모델을 학습하는데 필요한 파라미터들을 정의하는데 사용된다고 한다.
YACS was created as a lightweight library to define and manage system configurations, such as those commonly found in software designed for scientific experimentation. These "configurations" typically cover concepts like hyperparameters used in training a machine learning model or configurable model hyperparameters, such as the depth of a convolutional neural network.
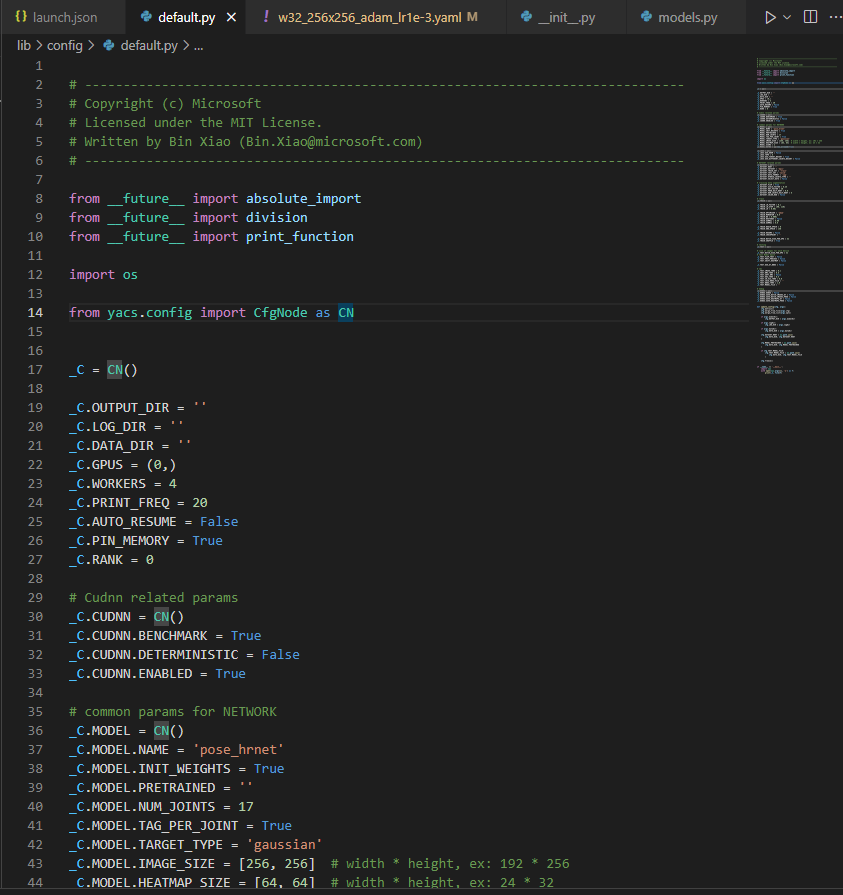
위 그림에서 확인 할 수 있듯, experiments/coco/hrnet/w32_256x192_adam_lr1e-3.yaml 에서 덮어씌우기 이전에 하이퍼파라미터들의 default값이 저장되어 있음을 확인할 수 있다.
또한, 이 파일에는 update_config(cfg,args) 함수가 정의 되어 있는데,

이는 python tools/train.py --cfg experiments/coco/hrnet/w32_256x192_adam_lr1e-3.yaml 에서 불러오는 arguments들을 어떻게 덮어 씌울 것인지에 대한 함수이다.
뒤에서도 보겠지만, train.py 함수에 있는 parse_args()를 불러와 args 들을 설정해주면, main 함수에서 update_config을 통해 default값들을 args로 덮어 씌우는 단계를 거치게 된다.
train.py
models.py
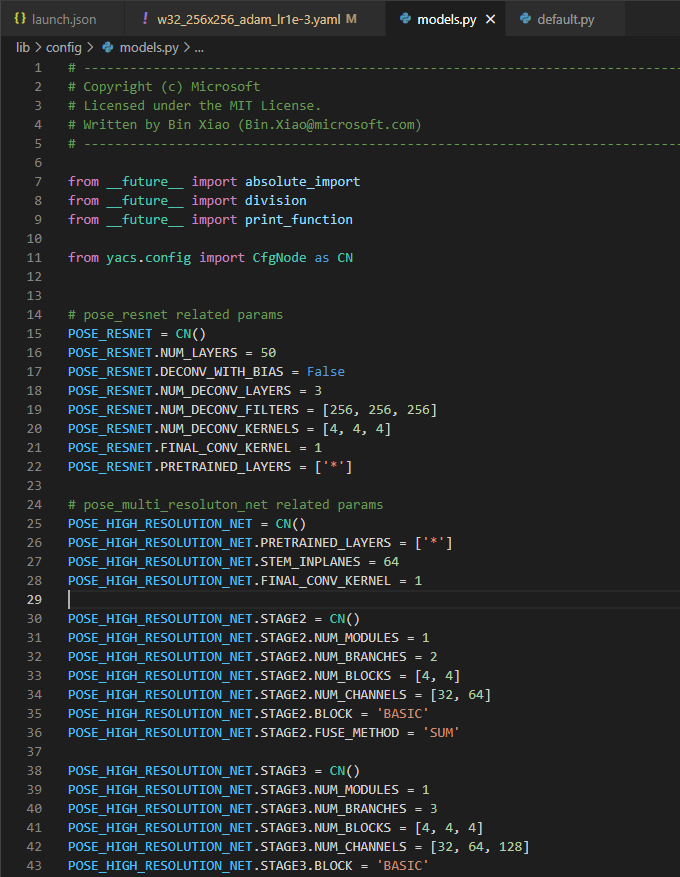
models.py file은 pose_resnet과 pose_multi_resolution_net에 관련된 파라미터들을 설정해준다.
마찬가지로, yacs.config import CfgNode as CN을 통해 구현해준다.
2-2 core dir
core dir 안에는 다음과 같이 4개의 python file이 있다.
${POSE_ROOT}
├── lib
├── core
├── evaluate.py
├── function.py
├── inference.py
└── loss.pyevaluate.py 부터 살펴보자
evaluate.py
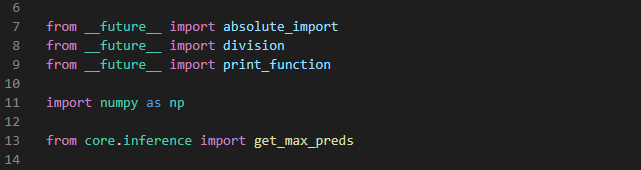
import 된 함수들을 보면, core directory안에있는 inference python file에서 정의된 get_max_preds 함수를 불러온 것을 볼 수 있다.
잠시 inference file에 들어가 get_max_preds 함수가 정의된 형태를 살펴보면, 다음과 같다.
(batch_heatmap을 인자로 받아오는 형태로 정의되어있다)
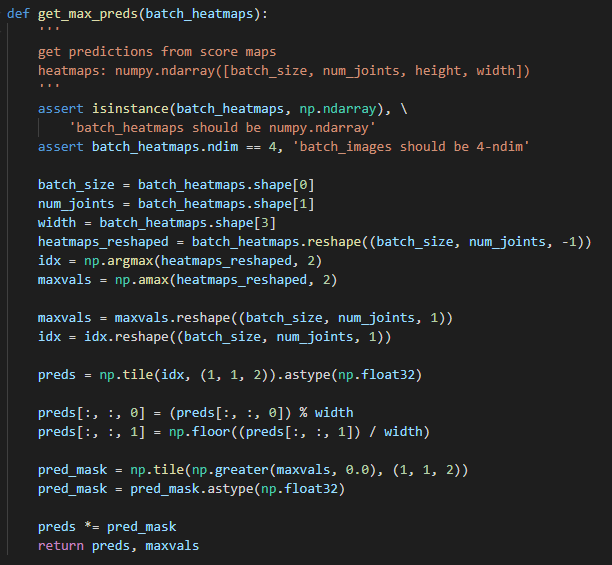
get predictions from score maps
heatmaps: numpy.ndarray([batch_size, num_joints, height, width])다음과 같은 설명을 보면, score maps로부터 예측값을 얻는 것이다. 즉 여러 예측값 중 max 예측값을 얻는 역할을 해준다.
그리고 heatmap의 형태는 numpy.ndarry 형태로, batch_size, joint의 num, height, weight로 구성 되어있다.
assert 함수?
assert 조건, '메시지'
'메시지'는 생략할 수 있다.
assert isinstance(batch_heatmaps, np.ndarray), \ # batch_heatmap이 np.ndarry 인지
'batch_heatmaps should be numpy.ndarray'
assert batch_heatmaps.ndim == 4, 'batch_images should be 4-ndim' # batch_heatmaps.ndim 이 4차원인지먼저 확인 과정을 거치는 것을 알 수 있다.
위에서 언급했다시피 heatmap의 구성은 batch_size, joint의 num, height, weight 순으로 구성 되어있으므로, 각 변수 이름에 heatmap의 각 index에 맞게 정의해준다.
batch_size = batch_heatmaps.shape[0]
num_joints = batch_heatmaps.shape[1]
width = batch_heatmaps.shape[3]heatmap를 (batch_size, num_joints, -1) 로 reshape하는 과정을 거친다.
idx 변수에는 reshaped된 heatmap의 큰 값 index를 받고
maxvals 에는 큰 값의 value를 저장한다.
heatmaps_reshaped = batch_heatmaps.reshape((batch_size, num_joints, -1))
idx = np.argmax(heatmaps_reshaped, 2) # 뒤 2 인자는 axis를 뜻한다
maxvals = np.amax(heatmaps_reshaped, 2)reshape 함수?
reshape함수는 np.reshape(변경할 배열, 차원) 또는 배열.reshape(차원)으로 사용 할 수 있으며, 현재의 배열의 차원(1차원,2차원,3차원)을 변경하여 행렬을 반환하거나 하는 경우에 많이 이용되는 함수이다.
#1차원에서 3차원으로 reshape a = np.arange(1,9) b = a.reshape(2,2,2) b >>> array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])reshape에서 -1의 의미
: 행(row)의 위치에 -1을 넣고 열의 값을 지정해주면 변환될 배열의 행의 수는 알아서 지정이 된다는 소리다.
argmax, amax 함수?
argmax는 가장 큰 값의 index를 반환
amax는 가장 큰 값을 반환
둘다 두번째 인자로 axis인자를 받는데, 어떤 dimension을 기준으로 max 값을 찾을지에 대한 정보를 지닌다.
np.tile 함수?
a = np.array([0, 1, 2]) np.tile(a, 2) # shape=(6,) # array([0, 1, 2, 0, 1, 2]) np.tile(a, (1, 2)) # shape=(1, 6) # array([[0, 1, 2, 0, 1, 2]]) np.tile(a, (2, 1)) # shape=(2, 3) # array([[0, 1, 2], # [0, 1, 2]])
다시 evaluate.py 로 돌아와서 코드를 보자.
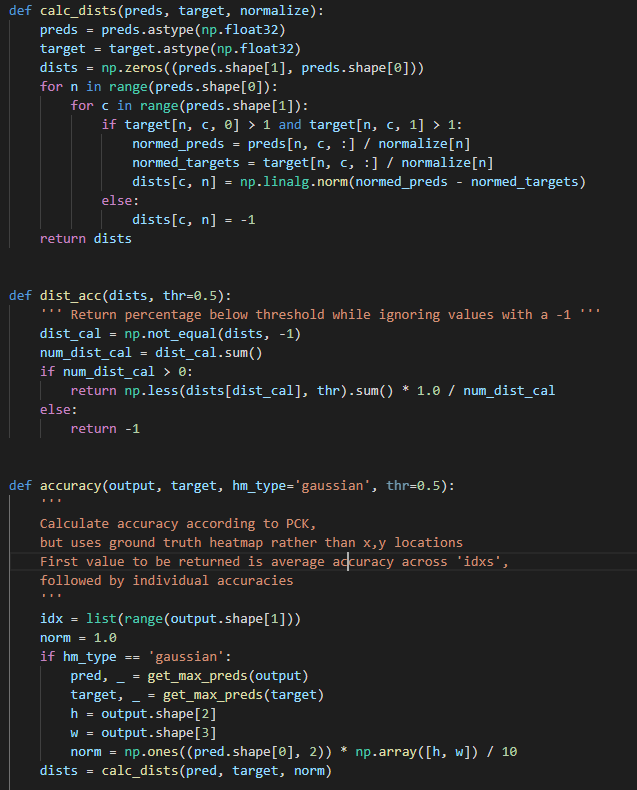
calc_dist 함수에서는 prediction과 target값 사이 거리를 계산하고 계산된 distance(dist) 를 return해준다.
dist_acc에서는 받아온 dist값이 -1이 아닐때 True boolean값을 dist_cal 변수에 담고, 총 True가 몇개인지 num_dist_cal에 담는다. 그리고 sum 이 0보다 큰 경우, 0.5와 dists 안에 있는 -1 이 아닌 값들과 비교하여 작은 0.5가 더 크면 False를, 작으면 True를 반환하여 True의 값을 세어 num_dist_cal로 나누어주어 percentage를 계산한다.
accuracy 함수에서는 output과 target, hm_type = 'gaussian', thr = 0.5를 받아 PCK 를 통해 accuracy를 계산한다.
✔ np.array가 담겨진 변수에 .sum()을 하게 되면 True 값의 개수를 저장한다.
np.not_equal 함수?
np.not_equal(x_1,x_2)x_1 과 x_2가 같지 않을때 False boolean을 return한다.
np.less 함수?
np.less([1, 2], [2, 2]) array([ True, False])각 index 별로 앞 index 값이 더 작으면 True, 크면 False를 np.array 형태로 return 한다.
evaluate.py에서는 Accuracy를 PCK를 통해 계산하는 python file이라고 요약하면 좋을 것 같다!
inference.py
inference.py 안에는 위에서 본 get_max_preds 와 get_final_preds 함수가 정의 되어 있다.
마찬가지로 import 된 함수와 모듈들을 살펴보면, utils directory 에 있는 transforms.py 안에 정의된 transform_preds 함수를 불러온 것을 확인 할 수 있다. 먼저 transform_preds를 살펴보자.
from __future__ import absolute_import # 미래 python에서 받아오기
from __future__ import division
from __future__ import print_function
import math
import numpy as np
from utils.transforms import transform_preds
transforms.py 안 transform_preds 함수
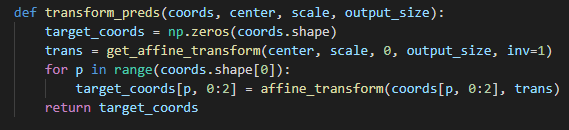
function.py
function.py 에서는 후에 실행할
python tools/train.py \
--cfg experiments/coco/hrnet/w32_256x192_adam_lr1e-3.yaml \train.py 에서 부를 train 함수가 정의 되어 있다. 또한 validate 함수도 정의 되어있다.
train 함수는 train_loader로부터 이미지를 batch size 만큼 가져와 input, target 값으로 받아오고 이를 .cuda()를 통해 gpu로 올려준다.
2-3 models dir
pose_hrnet.py
pose_hrnet.py는 실제로 hrnet에서 사용하고 있는 모델을 구현한 python file이다.
모델의 전체적인 구조를 알고 싶다면 이 파일을 확인해야할 것! 좀 세세하게 분석하기로 했다.
전체 코드는 HRNet모델전체코드 에 따로 게시글로 올려두었다.
python file에 정의된 class 가 4개인데, BasicBlock, BottleNeck, HighResolutionModule, PoseHighResolutionNet 이 있다.
BasicBlock과 BottleNeck은 block의 형태를 정의해주고, PoseHighResolutionNet은 최종 모델 구조이며 HighResolutionModule class를 사용한다.
# code block 1 - import
import는 특별할 거 없이 torch와 os 등을 받아준다.
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import logging
import torch
import torch.nn as nn# code block 2 - 3x3 conv layer
kernel_size가 3인 convolutional layer를 일일이 작성하는 것을 방지하기 위해 편의를 위해 정의해주는 함수
in_plane, out_plane을 인자로 받으면 (input channel와 output channel) 인자값을 기반으로 kernel size가 3인 convolutional layer가 return 값으로 생성된다.
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)# code block 3 - BasicBlock & BottleNeck
BasicBlock은 ResNet 논문에서도 알 수 있듯, skip connection을 이용하여 residual 값을 마지막에 더해주는 구조로,
3x3 conv layer → batch normalization → relu → 3x3 conv layer → batch normalization ( → residual 차원이 같이 않다면 downsample) → (forward과정을 거친) out + residual
과정을 거친다.
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
Bottleneck은 ResNet논문에서 언급하듯, 좀 더 깊은 layer에 적용되는 block으로 basicblock과 비슷하게 skip connection을 통해 residual을 더해주지만, basicblock과는 다르게 1x1 → 3x3 → 1x1 kernel size를 가진 conv layer를 거친다.
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1,
bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion,
momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out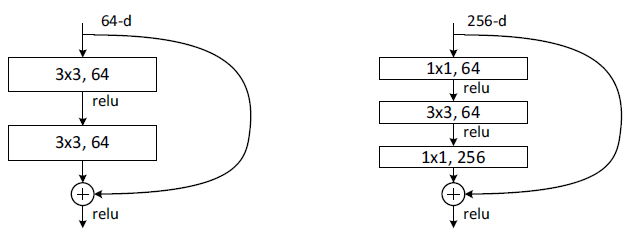
# code block 4 - HighRevolutionModule
class 를 정의 할때 인자로 num_brancehs, blocks, num_blocks, num_inchannels, num_channels, fuse_method, multi_scale_output = True 를 받아 온다.
class HighResolutionModule(nn.Module):
def __init__(self, num_branches, blocks, num_blocks, num_inchannels,
num_channels, fuse_method, multi_scale_output=True):
super(HighResolutionModule, self).__init__()
self._check_branches(
num_branches, blocks, num_blocks, num_inchannels, num_channels)
self.num_inchannels = num_inchannels
self.fuse_method = fuse_method
self.num_branches = num_branches
self.multi_scale_output = multi_scale_output
self.branches = self._make_branches(
num_branches, blocks, num_blocks, num_channels)
self.fuse_layers = self._make_fuse_layers()
self.relu = nn.ReLU(True)
정의할 함수로는, check_branches, make_one_branch, make_branches, make_fuse_layers, get_num_inchannels 등이 있다.
간략하게 각 함수들을 요약해보면,
- check branches : branches 생성에 error없는지 확인하는 역할을 한다.
인자로는, num_branches (branch 개수), block(basic/bottleneck 중 택일),
num_blocks (block의 개수), num_inchannels, num_channels(output channel 수)
experiments/mpii/hrnet/w32_256x256_adam_lr1e-3.yaml 파일을 확인해보면, stage3에서는 각 인자값이 다음과 같음을 확인 할 수 있다.
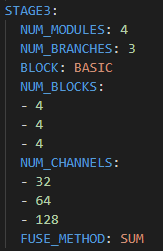
-
make_one_branch & make_branches :
make_branches 에서는 make_one_branch를 불러와 사용한다. branch를 생성하는 역할을 한다. -
make_fuse_layers :
branch의 개수가 1이 아닌 경우에 branch들을 합쳐주는 역할을 한다. -
get_num_inchannels :
num_inchannel을 return 해주는 역할을 한다.
# code block 4-1 - def _check_branches
위에서 간략하게 언급했듯, 받을 인자로는 num_branches (branch 개수), block(basic/bottleneck 중 택일),
num_blocks (block의 개수), num_inchannels, num_channels(output channel 수) 등이 있다.
만약 num_branches가 num_block의 길이, num_channel의 길이, num_inchannel의 길이와 같지 않다면 error msg를 띄울 수 있게 설정해 놓았다
def _check_branches(self, num_branches, blocks, num_blocks,
num_inchannels, num_channels):
if num_branches != len(num_blocks):
error_msg = 'NUM_BRANCHES({}) <> NUM_BLOCKS({})'.format(
num_branches, len(num_blocks))
logger.error(error_msg)
raise ValueError(error_msg)
if num_branches != len(num_channels):
error_msg = 'NUM_BRANCHES({}) <> NUM_CHANNELS({})'.format(
num_branches, len(num_channels))
logger.error(error_msg)
raise ValueError(error_msg)
if num_branches != len(num_inchannels):
error_msg = 'NUM_BRANCHES({}) <> NUM_INCHANNELS({})'.format(
num_branches, len(num_inchannels))
logger.error(error_msg)
raise ValueError(error_msg)실제로 확인해보면,
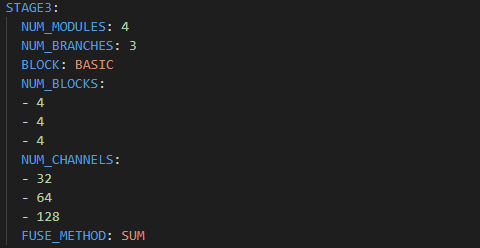
num branches 가 3일때, len(num blocks) 도 3, len(num channels & in channel) 도 3 인 것을 확인 할 수 있다.
# code block 4-2 - def _make_one_branch & _make_branches
먼저 make_branches들을 살펴보면, 다음과 같다.
def _make_branches(self, num_branches, block, num_blocks, num_channels):
branches = []
for i in range(num_branches):
branches.append(
self._make_one_branch(i, block, num_blocks, num_channels)
)
return nn.ModuleList(branches)branch의 index : 0부터 num_branches로, 총 branches의 개수를 의미한다. 따라서 branch 개수만큼 make_one_branch를 불러오게 되어 총 num_branch 개수만큼 branch를 생성하는 것을 알 수 있다.
block : basic block인지 bottleneck인지에 대한 정보를 받아온다.
num_blocks : block의 개수
num_channel : 채널의 개수
make_branches 함수는 하나의 branch를 만들 때마다 branches라는 빈 리스트에 append(추가) 하는 코드 구조를 지니고 있다.
---
이제 make_one_branch 구조를 자세히 살펴보자.
stride가 1이 아닌 경우 또는 각 branch의 num_inchannel 과 num_channels * block.expansion (basic block 경우 1, bottleneck인경우 4) 이 다른경우, downsample 과정을 거치게 된다.
downsample 과정은 in channel이 각 branch의 in channel, out channel이 각 branch의 num_channel * expansion이고, kernel_size는 1x1인 convolutional layer를 거치고, batchnorm layer를 거치게 된다.
---
빈 리스트 layers를 정의해주고 리스트 안에 하나의 block을 추가해준다(append).
다
def _make_one_branch(self, branch_index, block, num_blocks, num_channels,
stride=1):
downsample = None
if stride != 1 or \
self.num_inchannels[branch_index] != num_channels[branch_index] * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(
self.num_inchannels[branch_index],
num_channels[branch_index] * block.expansion,
kernel_size=1, stride=stride, bias=False
),
nn.BatchNorm2d(
num_channels[branch_index] * block.expansion,
momentum=BN_MOMENTUM
),
)
layers = []
layers.append(
block(
self.num_inchannels[branch_index],
num_channels[branch_index],
stride,
downsample
)
)
self.num_inchannels[branch_index] = \
num_channels[branch_index] * block.expansion
for i in range(1, num_blocks[branch_index]):
layers.append(
block(
self.num_inchannels[branch_index],
num_channels[branch_index]
)
)
return nn.Sequential(*layers)따라서 stage 3를 예시로 들어보면,
num_branches가 3개이므로, 3번의 make_one_branch 를 실행하는 loop를 돌게 된다.
첫번째 두번째 세번째 branch 안에는 각각 4개의 block이 있다.


즉, 각 stage당 branch 개수 만큼 branch를 형성하고 각 branch에는 block의 개수만큼 block이 형성된다.
# code block 4-3 - def _make_fuse_layers
make_fuse_layers의 전체 코드는 다음과 같다.
def _make_fuse_layers(self):
if self.num_branches == 1:
return None
num_branches = self.num_branches
num_inchannels = self.num_inchannels
fuse_layers = []
for i in range(num_branches if self.multi_scale_output else 1):
fuse_layer = []
for j in range(num_branches):
if j > i:
fuse_layer.append(
nn.Sequential(
nn.Conv2d(
num_inchannels[j],
num_inchannels[i],
1, 1, 0, bias=False
),
nn.BatchNorm2d(num_inchannels[i]),
nn.Upsample(scale_factor=2**(j-i), mode='nearest')
)
)
elif j == i:
fuse_layer.append(None)
else:
conv3x3s = []
for k in range(i-j):
if k == i - j - 1:
num_outchannels_conv3x3 = num_inchannels[i]
conv3x3s.append(
nn.Sequential(
nn.Conv2d(
num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False
),
nn.BatchNorm2d(num_outchannels_conv3x3)
)
)
else:
num_outchannels_conv3x3 = num_inchannels[j]
conv3x3s.append(
nn.Sequential(
nn.Conv2d(
num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False
),
nn.BatchNorm2d(num_outchannels_conv3x3),
nn.ReLU(True)
)
)
fuse_layer.append(nn.Sequential(*conv3x3s))
fuse_layers.append(nn.ModuleList(fuse_layer))
return nn.ModuleList(fuse_layers)
---
하나하나 쪼개어 분석해보자.
def _make_fuse_layers(self):
if self.num_branches == 1:
return None
num_branches = self.num_branches
num_inchannels = self.num_inchannels
fuse_layers = []num_branches가 1개 이면 None을 return 한다.
그리고 빈 리스트 fuse_layers 를 정의한다.
---
for i in range(num_branches if self.multi_scale_output else 1):
fuse_layer = []
for j in range(num_branches):이어서 for 문을 살펴보면,
i의 range 범위가 multi_scale_output이 True 일 경우 num_branches 이고, False 일 경우 1이므로, HighResolutionModule에서 multi_scale_output default값이 True 이기 때문에 i 의 range 범위는 0 부터 (num_branches -1) 까지이다.
i의 for문 안에서 fuse_layer 빈 리스트가 정의 되어있으므로, i의 loop을 돌 때마다 빈 리스트로 초기화 된다.
j의 range 범위는 i와 같이 num_branches 이기 때문에 j는 0부터 (num_branches -1) 까지이다.
j 의 값이 i 보다 큰 경우, i와 같은 경우, i 보다 작을 경우로 나뉘는데, j의 값이 i보다 큰 경우부터 살펴보자.
---
num_branches가 3인 경우 (stage 3를 예시로 한다)
1) j의 값이 i보다 큰 경우
▶ (i,j) = (0,1) (0,2) (1,2)
if j > i:
fuse_layer.append(
nn.Sequential(
nn.Conv2d(
num_inchannels[j],
num_inchannels[i],
1, 1, 0, bias=False
),
nn.BatchNorm2d(num_inchannels[i]),
nn.Upsample(scale_factor=2**(j-i), mode='nearest')
)
)빈 리스트인 fuse_layer에 Convlayer → BatchNorm → Upsample 을 담은 Sequential을 추가해준다.
conv layer는 j번째 index의 num_channel 값을 in_channel로하고, i번째 index의 num_channel 값을 out_channel로 하고, stride = 1, kernel_size = 1, padding = 0 인 구조를 지닌다.
nn.Upsample 함수?
scale_factor 인자 : (float or Tuple[float] or Tuple[float, float] or Tuple[float, float, float], optional) – multiplier for spatial size. Has to match input size if it is a tuple.즉, size에 몇을 곱해줄지에 대한 인자
mode (str, optional) 인자 : the upsampling algorithm: one of 'nearest', 'linear', 'bilinear', 'bicubic' and 'trilinear'. Default: 'nearest'
이후j-i ( scale factor ) 만큼 upsample을 해준다.
따라서 하나의 convolution layer와 batchnorm, upsample을 담은 Sequential 을 추가한다.
---
2) j의 값이 i와 같은 경우
▶ (i,j) = (0,0) (1,1) (2,2)
elif j == i:
fuse_layer.append(None)아무것도 list에 append 해주지 않는다.
---
3) j의 값이 i보다 작은 경우
▶ (i,j) = (1,0) (2,0) (2,1)
else:
conv3x3s = []
for k in range(i-j):
if k == i - j - 1:
num_outchannels_conv3x3 = num_inchannels[i]
conv3x3s.append(
nn.Sequential(
nn.Conv2d(
num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False
),
nn.BatchNorm2d(num_outchannels_conv3x3)
)
)다른 경우와 다르게 fuse_layers에 바로 추가하는 것이 아닌 conv3x3s 라는 빈 리스트를 먼저 생성해준다.
for 문의 range는 인자 k 를 0부터 i-j-1 이다.
즉,
(i,j) = (1,0) 일때 i-j-1 = 0,
(i,j) = (2,0) 일때 i-j-1 = 1,
(i,j) = (2,1) 일때 i-j-1 = 0 이다.
else:
num_outchannels_conv3x3 = num_inchannels[j]
conv3x3s.append(
nn.Sequential(
nn.Conv2d(
num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False
),
nn.BatchNorm2d(num_outchannels_conv3x3),
nn.ReLU(True)
)
)
fuse_layer.append(nn.Sequential(*conv3x3s))else문에서는 num_outchannels_conv3x3 변수에 num_inchannel의 j번째 index로 정의하고,
conv3x3s의 빈 리스트에 num_inchannel의 j번째 index 값을 input channel로, num_inchannel의 j번째 index의 값을 output channel로 가지며, kernel_size가 3, stride가 2, padding이 1 인 conv layer와 BN, ReLU를 추가해준다.
else 문이 끝나면 fuse_layer에 conv3x3s를 append 해준다.
---
j에 대한 모든 경우의 수가 끝나면 fuse_layers 에 fuse_layer list를 append 해준다. 그리고 새로운 i에 대해 다시 fuse_layer를 초기화한다.
fuse_layers.append(nn.ModuleList(fuse_layer))
--
i에 대한 모든 경우의 수가 끝나면, fuse_layers를 return 해준다.
return nn.ModuleList(fuse_layers)✔ j와 i의 for문에서 정의 그리고 초기화되는 리스트에 대해 주의해야한다 !!
# code block 4-4 - def forward
forward를 해주기 위한 함수로, 전체 코드는 다음과 같다.
def forward(self, x):
if self.num_branches == 1:
return [self.branches[0](x[0])]
for i in range(self.num_branches):
x[i] = self.branches[i](x[i])
x_fuse = []
for i in range(len(self.fuse_layers)):
y = x[0] if i == 0 else self.fuse_layers[i][0](x[0])
for j in range(1, self.num_branches):
if i == j:
y = y + x[j]
else:
y = y + self.fuse_layers[i][j](x[j])
x_fuse.append(self.relu(y))
return x_fuse예시 : stage 2
stage 2를 예시로 해보자
def forward() 를 보면, num_branches이 2이기 때문에 if 문을 통과하고
def forward(self, x):
if self.num_branches == 1: # num_branches이 2이기 때문에 if 문을 통과
return [self.branches[0](x[0])] # self.branches = self._make_branches(
# num_branches, blocks, num_blocks, num_channels)
첫번째 i의 for 문 2번 시행하게 된다.
for i in range(self.num_branches): # num_branches =2, 2번의 for loop
x[i] = self.branches[i](x[i])
x_fuse = []
for i in range(len(self.fuse_layers)):
y = x[0] if i == 0 else self.fuse_layers[i][0](x[0])
for j in range(1, self.num_branches):
if i == j:
y = y + x[j]
else:
y = y + self.fuse_layers[i][j](x[j])
x_fuse.append(self.relu(y))
return x_fuse첫번째 i의 for 문 안에서 transition1을 통과한 첫번째 x[0] 와 x[1]를 서로다른 branch에 통과시키는데, x[0]은 branch[0]에, x[1]은 branch[1]에 통과시키고 각각을 자기자신으로 다시 정의해준다.
두번째 i의 for 문은 fuse_layers 의 길이만큼 for loop을 시행한다.
case 1) i = 0
y = x[0]로 정의해주고
branch의 길이만큼 j for loop을 시행해준다(즉 2번)
case 1-1) i = 0, j = 0
i 와 j가 둘다 0으로 같을 때, y를 y + x[0]로 재 정의 해준다. 즉 y = 2x[0]가 된다.
case 1-2) i = 0, j = 1
i와 j가 다를 때,
y를 y + self.fuse_layers[0][1](x[1]) 로 재정의한다.
즉 case 1-2)를 예시로 하자면,
Sequential(
(0): Sequential(
(0): Conv2d(256, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)를 통과한 x[1]은,
(1): Sequential(
(0): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=2.0, mode=nearest)
)위와 같은 (self.fuse_layers[0][1]) fuse_layer를 통과하게 된다.
이후 x_fuse에 y를 relu 함수에 통과시킨 결과 값을 append해준다.
---
case 2) i = 1
y를 self.fuse_layers[1][0](x[0]) 으로 정의하고,
여기서 self.fuse_layers[1][0]은 다음과 같다.
Sequential(
(0): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)j의 for loop에서
case 2-1) i = 1, j = 0
i와 j가 다를 때, y를 y + x[0] 으로 재 정의 해준다.
case 2-2) i = 1, j = 1
i 와 j가 둘다 1로 같을 때, y를 y + self.fuse_layers[1][1](x[1]) (none) 으로 재정의한다.
y를 y + self.fuse_layers[1][1](x[1]) 로 재정의 해준다.
self.fuse_layers[1][1]은 다음과 같다.
(0): Sequential(
(0): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)전체 코드는 HRNet 모듈 에서 알 수 있듯,
stage2의 fuse_layer는 다음과 같다.
(fuse_layers): ModuleList(
(0): ModuleList(
(0): None
(1): Sequential(
(0): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=2.0, mode=nearest)
)
)
(1): ModuleList(
(0): Sequential(
(0): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): None
)
)stage2의 branch들
HighResolutionModule(
(branches): ModuleList(
(0): Sequential(
(0): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)최종적으로...
transition1[0]을 통과한 x[0]는 다음 layers들을 통과한다.
#transition1[0]
Sequential(
(0): Conv2d(256, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
# 1번째 branch
(branches): ModuleList(
(0): Sequential(
(0): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
그 이후, for문을 통해 2배의 x[0]와 self.fuse_layers[0][1]를 통과한 x[1]을 합쳐준다. (둘 다 output channel이 32)
# x[1]이 통과한 self.fuse_layer
(1): Sequential(
(0): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=2.0, mode=nearest)
)즉, y = 2x[0] + self.fuse_layers[0][1](x[1]) 가 되고, y는 relu 함수를 통과하게 된다.
그리고 그 결과값을 x_fuse에 append 해준다.
---
그리고 transition1[1]을 통과한 x[1]는 다음 layers들을 통과한다.
# transition1[1]
Sequential(
(0): Sequential(
(0): Conv2d(256, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
# 2번째 branch
(1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)그 이후, for문을 통해 x[1] 과 2배의 (self.fuse_layers[1][0]를 통과한 x[0])을 합쳐준다. (둘 다 output channel이 64)
# x[0]가 통과한 self.fuse_layers[1][0]
(1): ModuleList(
(0): Sequential(
(0): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)즉, y = x[1] + 2(self.fuse_layers[1][0](x[0])) 가 되고, y는 relu 함수를 통과하게 된다.
그리고 그 결과값을 다시한번 x_fuse에 append 해준다.
따라서 두개의 transition과 branch를 통과한 것을 fuse해준 결과를 x_fuse에 넣는다.
이것이 self.stage2(x_list)의 결과!!
