HigherHRNet 논문 을 참고하여 작성하였다.
Abstract
기존 Bottom Up 의 어려운 점은 scale variation을 해결하지 못하여 small person의 pose Acc가 낮다는 점이었다. 이를 해결할, 본 논문에서는 HigherHRNet, 새로운 bottom-up human pose estimation method을 제공한다.
High-resolution feature pyramid를 이용하여 scale-aware representation들을 학습하고, training 동안 multi-resolution supervision을 사용하고, 추론을 위해 multi resolution aggregation을 한다. 이를 통해 scale variation 문제를 해결할 수 있게 되고 small person에 대해 keypoints들을 더 정확하게 위치 시킬 수 있다.
HigherHRNet의 feature pyramid는 HRNet의 featuremap output과 transposed convolution을 통해 얻은 upsampled higher-resolution outputs 들로 구성이 되어있다.
Introduction
2D human pose estimation은 keypoints (eg, 발목, 손목 등) 위치를 예측하는데 목적을 두고 있는데, 2가지의 method으로 구성되어있다.
Top down과 Bottom up 2가지 방법이 존재하며, top down의 경우는 human을 먼저 인식하고 keypoints들을 찾는 반면, bottom up 방식은 keypoints들을 먼저 인식 한 후 개인으로 group을 하는 방식이다.
Top down 방식은 모든 사람들을 normalize를 통해 같은 scale로 변환이 가능하나, 사람을 detect하는데에 많은 의존이 존재하며 (예를들어, 애초에 사람을 인식하지 못하면 keypoint 찾는게 아예 불가능하다) 개인에 대해 human pose를 예측하기 때문에 conputationally intensive하고 end-to-end system 방법을 사용하지 못한다.
그러나 Bottom up 방식은 먼저 keypoint들의 위치를 인식하고 이후에 person을 grouping하는 단계를 거친다. 이 method는 효율성도 높고 빠른 속도를 가지고 있으며 real-time pose estimation을 예측하는데도 유용하지만, scale variation에 취약하여, small person pose estimation 에서는 top down보다 매우 낮은 Acc를 보이고 있다.
Small person pose estimation에는 어려움이 2가지 존재한다.
1) Large person 정확도의 변화 없이 small person pose estimation의 성능 높이기
2) Small person의 높은 성능을 가진 keypoint 위치 예측에 필요한 high-resolution heatmap 생성하기
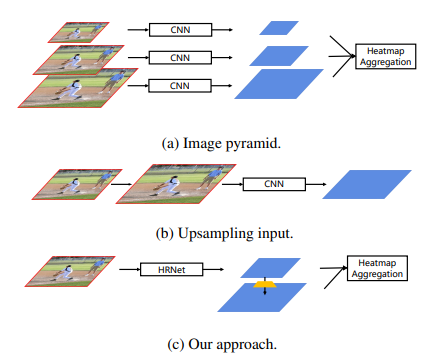
이전 bottom up method의 경우 keypoint들을 grouping하는 데에만 신경쓰고 keypoint heatmap을 예측하는데 input 이미지 해상도의 1/4 이 되는 single resolution featuremap만 사용하였다. 따라서 scale variation을 배제한 것이 한계점이었다. (a)
Feature pyramid는 scale variation을 해결하는데에 사용되는데, 또 다른 문제점이 존재한다. 보통 high-resolution heatmap을 생성하기 위해 input resolution을 증가시키는데, 이를 증가시키면 small person pose estimation의 성능은 높아지나, large person의 성능은 낮아진다. 따라서 더 정확하고 scale-aware한 heatmap이 필요하다.
HigherHRNet
본 논문에서는 scale aware Higher Resolution Network (HigherHRNet)으로 위와 같은 문제점을 해결하고자한다. HigherHRNet은 새로운 high-resolution feature pyramid module을 통해서 high-resolution heatmap을 생성한다.
다른 기존의 feature pyramid처럼 1/32 resolution으로 시작하여 bilinear upsmapling과 leateral connection을 통해 점진적으로 feature map resolution을 1/4로 증가시키는 것과 달리 higher-resolution feature pyramid의 경우 1/4 resolution 으로 시작하여 (backbone에서 가장 높은 resolution) deconvolution으로 인해 더 높은 해상도 feature map을 생성한다. (c)
효율성을 위하여 high-resolution feature pyramid을 HRNet의 1/4 resolution path에 위치 시킨다. HigherHRNet을 scale variation에 대응하기 위해서 다양한 해상도의 학습 타겟 배정을 위해 Multi-Resolution Supervision strategy를 해당 feature pyramid level에 사용한다.
최종적으로, simple Multi-Resolution Heatmap Aggregation strategy를 추론 과정에 사용하여 scale-aware high-resolution heatmap을 생성한다.
주로 large person의 성능 감소 없이 medium person에서 좋은 성능이 나왔다.
Summarize
• We attempt to address the scale variation challenge,
which is rarely studied before in bottom-up multiperson pose estimation.
• We propose a HigherHRNet that generates high-resolution feature pyramid with multi-resolution supervision in the training stage and multi-resolution heatmap aggregation in the inference stage to predict scale-aware high-resolution heatmaps that are beneficial for small persons.
• We demonstrate the effectiveness of our HigherHRNet on the challenging COCO dataset. Our model outperforms all other bottom-up methods. We especially observe a large gain for medium persons.
• We achieve a new state-of-the-art result on the CrowdPose dataset, suggesting bottom-up methods are more robust to the crowded scene over top-down methods.
Related works
Feature pyramid
Pyramidal representation은 scale variation을 해결하는데에 많이 사용되는 방식이다. 본 논문에서는 high-resolution feature pyramid를 사용한다.
High-resolution feature pyramid는 pyramid를 서로 다른 방향으로 연장하여, 1/4 resolution feature로부터 시작하여 높은 해상도 feature를 지닌 pyramid를 생성한다.
High resolution feature maps
High resolution feature maps를 생성하는 4가지 절차가 있다.
(1) context 정보를 encoding을 통해 얻고, high resolution feature를 decoding 과정에서 복구한다.
Decoder는 주로 bilinear upsample operations와, 같은 해상도를 가진 encoder feature들로부터 얻은 skip-connection로 구성되어 있다.
(2) Feature map 해상도를 보존하기 위해서 몇몇개의 stride convolutions과 max pooling을 제거하는 Dilated convolution이 사용된다.
(3) Deconvolution은 network의 마지막에 사용되는데, feature map의 해상도를 효율적으로 높여주는 역할을 한다.
(4) HRNet의 사용
HRNet에서 낮은 해상도는 맥락 관련 정보 (contextual info from low resolution) 를, 높은 해상도는 공간적 정보를 (high resolution branches preserve spatial information)를 보존한다.
branches사이 Multi scale fusions은 high resolution feature maps를 생성하는데 도움을 준다.
본논문은 HRNet을 base network으로 사용하여 high-quality feature map을 생성한다. 그리고 heatmap 예측을 위해 Deconvolution module을 추가하여 higher resolution feature maps를 생성한다.
Higher-Resolution Network
HigherHRNet
HigherHRNet은 HRNet을 backbone으로 사용한다. HRNet은 stage1부터 high-resolution branch로 시작한다. 그리고 이어 따라오는 stage에서는 가장 낮은 resolution의 1/2에 해당하는 resolution를 가진 새로운 branch들을 기존 branch에 parallel하게 추가한다.
더 많은 stage를 가진 network로써, 더 다양한 resolutions를 지닐 것이고, 이전 stage의 resolution은 나중의 stage에 보존된다.
Structure
Network는 resolution을 1/4로 줄이는 stride가 2인 3x3 로 시작한다.
stage1은 4개의 residual units를 지니고, 각각의 unit은 width 가 64인 bottleneck으로 구성되어 있다.
이어서 feature map을 C로 줄여주는 1개의 3x3 convolution 이 덧붙여진다.
stage2,3,4 는 각각 1,4,3개의 multi-resolution blocks들을 포함한다.
4개의 resolution의 width는 각각 C, 2C, 4C, 8C 이다.
multi resolution block에 있는 각각의 branch들은 4개의 residual units를 가지고 있으며, 각각의 unit들은 2개의 3x3 convolution을 지닌다.
본논문은 HRNet을 기반으로 하며, 1x1 convolution을 추가해 heatmap을 예측한다. 본 논문은 예측에 가장 높은 해상도만 사용한다. (input 이미지의 1/4)
HigherHRNet
Heatmap의 해상도는 small person의 keypoints들을 예측하는데 매우 중요하다. Gaussian kernel을 사용하여 ground truth를 생성하는데, 이는 small person 예측에 혼동을 주어 이를 해결하는 방법이 필요하다.
따라서 다양한 해상도에서 높은 해상도로 heatmap을 예측하는 방법을 터득하는데, input 이미지의 1/4에 해당하는 resolution은 충분히 높지 않은 해상도이기 때문에 이를 해결하기 위해 Deconvolution 방식이 필요하다.
따라서 본 논문은 다음과 같이 HRNet + deconvolution module 을 사용한다.
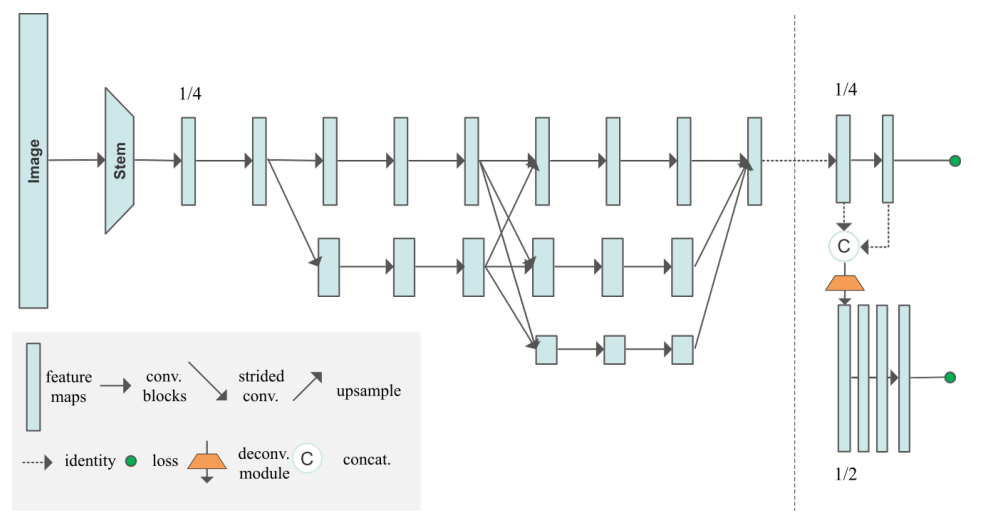
Deconvolution module은 input으로 both features, HRNet으로부터 예측된 heatmap을 받으며, input feature map의 resolution의 2배에 해당되는 새로운 feature map을 생성한다.
2개의 resolution을 가진 feature pyramid는 (1) Deconvolution module과 (2) HRNet으로부터 얻은 feature map 으로 얻어진다.
1x1 extra convolution을 추가함으로써 deconvolution moduel은 heatmap을 예측한다.
Multi-resolutions supervision으로 서로 다른 해상도를 가진 heatmap predictors를 학습하고, 이를 사용하여 추론 과정에 있어, heatmap aggregation strategy를 사용한다.
일반적으로 small person을 많이 포함한 dataset일수록 예측에 높은 해상도의 feature map을 요구한다.
더 높은 해상도가 요구된다면 더 많은 deconvolution module이 추가 될 수 있지만, 본 몬문은 single deconvolution module이 가장 좋은 성능을 보였기에 하나만 사용하기로 한다.
Grouping
keypoint grouping으로 associative embdding을 사용하기로 한다.
Deconvolution Module
본논문은 input feature maps의 해상도 2배가량 되는 높은 질의 feature map을 생성하는 simple Deconvolution moduel을 사용한다.
4x4 deconvolution 과 input feature map을 upsample하는 것을 학습하기 위해 BatchNorm, ReLU 함수를 사용한다.
Deconvolution module의 input으로 feature map과 HRNet이나, 이전의 deconvolution module로부터 나온 heatmap을 concate한 것을 받는다. 그리고 deconvolution module의 output feature maps은 또한번 multi-scalce fusion에서 heatmap을 예측하는데 사용된다.
Multi-Resolution Supervision
final loss heatmap : resolution 마다 MSE를 계산하고 이후에 total loss는 이들의 합으로 정의한다.
Heatmap Aggregation for Inference
Inference과정에서 heatmap aggreagation strategy를 사용한다. heatmap 예측 결과를 모두 upsample하기 위해 Bilinear interpolation을 사용하고, 모든 scale로 부터 얻은 heatmap의 평균치를 내어 final 예측에 사용한다.
Heatmap Aggregation을 사용하는 이유는 scale-aware pose estimation을 가능하게 하기 위해서이다.
Bottom up에서 heatmap의 다양한 scale은 keypoint capture를 더 잘하게끔한다. 에를들어 small person의 keypoint가 낮은 해상도 heatmap에서 누락됐다면, 이는 높은 해상도 heatmap에서 복구가 가능하다. 따라서 다양한 해상도에서 예측된 heatmap을 평균하는 것은 HigherHRNet을 scale-aware pose estimator로 만드는 주요 역할이다.
