LiteHRNet 논문을 바탕으로 정리한 글이다.
LiteHRNet 코드 코드는 본 github 을 참고하였다.
1 Abstract
본 논문에서는 효율적인 high-resolution network, LiteHRNet을 제공한다. Shuffle block을 HRNet에 적용하여 좋은 성능을 내고자한다.
본 논문에서는 lightweigt unit을 소개하고자 한다. 이 unit은 conditional channel weighting으로, shuffle block에 있는 cost가 높은 pointwise(1x1) convolution을 대체한다. Channel weighting의 복잡도는 Channel의 개수와 비례하고 pointwise convolution에 대한 quadraic time complexity보다 낮다.
본 논문은 모든 채널과 multiple resolution에 대해 weight을 학습한다. 이 weight들은 채널과 resolution 간의 정보 교환의 다리 역할을 해준다.
2 Introduction
모델의 효율성을 높이기 위해 본 논문은 computation-limited resources 환경 아래서 효율적인 high-resolution 모델을 제공한다.
현존하는 효율적인 network는 2가지 존재한다
1) classification에서 사용되는 network를 가져다 적용하기
2) encoder와 decoder 또는 multi branch 구조로 공간 정보 loss 를 조정하기
본 논문은 ShuffleNet에서 shuffle block과 high-resolution 디자인 HRNet을 합쳐서 naive lightweight network 를 제공한다. 이 조합은 SuffleNet, MobileNet, Small HRNet보다 좋은 성능을 보여준다.
더 높은 효율성을 가지기 위해 본 논문은 efficient unit, conditional channel weighting을 제안한다. 이 unit은 채널간 정보를 교환해주며 shuffle block안 pointwise 1x1 convoluton을 대체한다. Channel weighting의 복잡도는 Channel의 개수와 비례하고 pointwise convolution에 대한 quadraic time 복잡도보다 낮다. 예를들어 multi-resolution feature 64x64x40 과 32x32x80에 대해, conditional channel weighting unit은 shuffle block의 전체 계산량을 80%나 감소시킨다.
2-1 weights
본논문에서 제공하는 scheme에서 기존의 weight과는 달리, input map에서 conditioning이 이루어지고, lightweight unit을 통해 channel에서 계산된다. 따라서 weight은 전체 channel map의 정보를 지니고 있으며, channel weighting을 통해 정보를 교환하는 다리 역할을 가진다.
또한 weight을 HRNet의 parallel multi-resolution channel map으로부터 계산하기 때문에 weight들은 더 많은 정보를 지니고 강화된다.
이 모든 것을 가진 network를 LiteHRNet 이라고 부른다.
정리하자면,
- Naive Lite-HRNet = Shuffle block + HRNet
- Lite-HRNet = 위 + conditional channel weighting unit
Lite-HRNet이 훨씬 좋은 성능을 보이는 이유는 계산 복잡도의 감소 역할이 conditional channel weighting scheme에서 나오는 정보 교환의 loss보다 중요하기 때문이다.
3 Related Work
3-1 Efficient blocks for classification
Group convolution 과 depthwise convolutions에서 채널간 정보는 막혀있다. 이를 해결하기 위해 pointwise convolutions이 사용되는데, 계산량이 많아 이를 해결하기 위해서 channel shuffling으로 1x1 convolution들을 grouping해주거나 interleaving 방법을 사용한다.
본 논문의 해결책은 다음 문장과 같다.
Our proposed solution is a lightweight manner performing information exchange across channels to replace costly 1×1 convolutions.
3-2 Mediating spatial information loss
계산 복잡도는 spatial resolution과 깊은 상관성을 지닌다. Spatial resolution을 줄이면서 spatial 정보 loss를 조정하는 것 또한 효율성을 높이는데 사용된다. 그리고 Encoder와 Decoder로 spatial resolution을 극복하는데 사용된다.
본 논문은 HRNet의 전체 process 안에서 high-resolution을 유지하는 high resolution pattern을 사용한다.
4 Approach
4-1 Naive Lite-HRNet
Shuffle blocks
ShuffleNet V2 에 있는 shuffle block은 먼저 channel을 두 부분으로 나눈다. 그 중 하나는 1x1, 3x3, 1x1 convolution을 지나고 이를 지난 output은 다른 부분과 concatenate된다. 그리고 concatenate된 채널들은 shuffle된다.
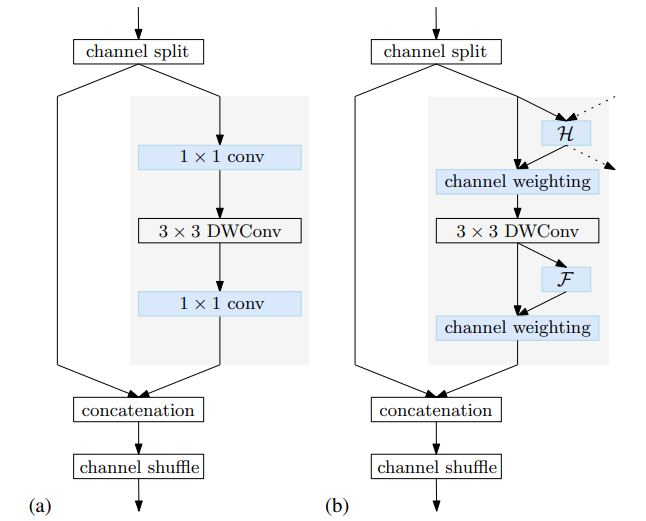
(a) 는 Shuffle Block (b) 는 본논문에서 사용하는 Conditional Channel weighting block
HRNet
HRNet에 대한 설명은 HRNet논문 정리 다음을 참고하면 된다. 본 논문에서는 Small HRNet design을 사용하는데, 기존 HRNet보다 더 적은 layer와 적은 width 를 가진 형태를 지닌다.
간단하게 구조를 설명하자면, Small HRNet의 stem은 2개의 stride가 2인 3x3 convolution을 가진다. Main body의 각 stage는 residual block을 지니고 하나의 multi-resolution fusion을 가진다.
다음은 Small HRNet의 구조이다.
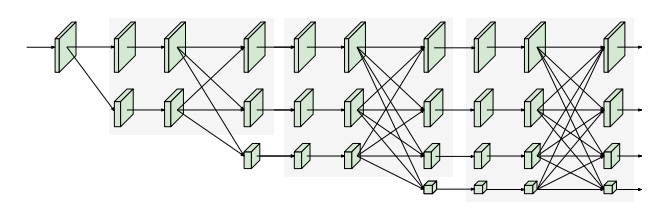
Simple combination
Small HRNet의 stem은 2개의 3x3 convolutions (stride =2)로 구성되어 있고 main body의 각 stage는 residual blocks와 1개의 multi-reoslution fusion으로 구성되어있다.
본 논문은 Small HRNet의 두번째 3x3 convolution을 shuffle block으로 바꾸고 2개의 3x3 convolution으로 구성되어있던 residual blocks을 전부 대체한다.
Multi-resolution fusion에 있던 normal convolutions들은 separable convolution으로 바뀌어 이는 naive Lite-HRNet이 된다.
4-2 Lite-HRNet
1x1 convolution 은 costly하다
각 위치에 대해 matrix-vector multiplication을 하는 1x1 convolution 식은 다음과 같다.
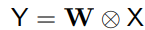
여기서 X와 Y는 input과 output map이고 W는 1x1 convolutional kernel이다. 이는 채널간 정보 교환의 주요 역할을 맡고있다.
1x1 convolution은 time complextity가 quadratic하다. O(C²) 로 표현되는데 여기서 C는 channel의 개수이다. 3x3 depthwise convolution은 1차 시간 복잡도를 가지며 (= O(9C)) 1x1 보다 낮음을 알 수 있다.
Conditional channel weighting
본 논문은 s stage마다 s개의 branch를 가진 naive Lite-HRNet에서 1x1 convolution을 대신해 element-wise weighting operation을 사용한다. 다음 식은 element-wise weighting operation이다.
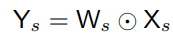
Ws는 weight map이고 Ws x Hs x Cs 의 3d tensor 값을 가지며, element wise muliplication을 통해 식이 구현된다.
복잡도는 O(C) linear하며 1x1 convolution보다 훨씬 낮다.
본논문은 모든 해상도에 대해서 각 해상도마다 채널을 통해 weight을 구하는데, 이 구해진 weight들은 채널과 해상도간 정보 교환에 많은 역할을 한다.
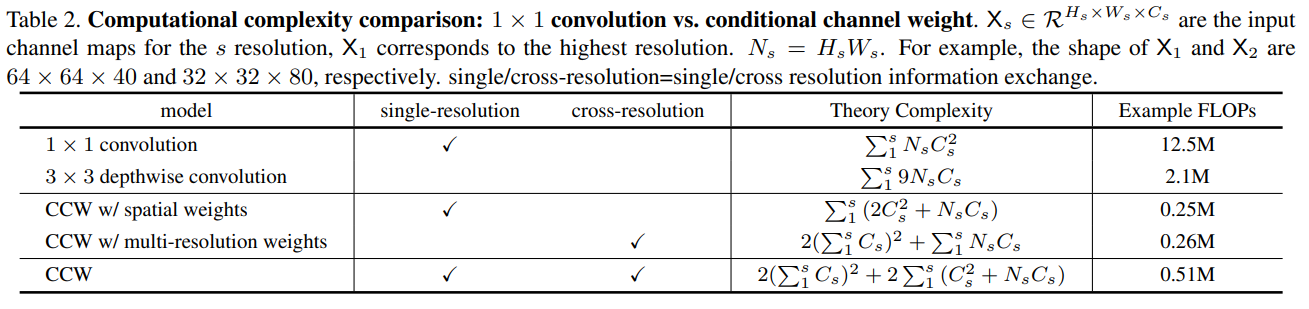
위 표는 computational complexity를 비교한 표이다.
Cross-resolution weight computation
s stage, s 개의 parallel resolution에 대해 s 개의 weight map이 존재한다 (W1, W2, ... , Ws) . 본 논문은 lightweight 함수 Hs()을 통해서 해상도마다 모든 채널에 대해 s 개의 weight map을 구한다.
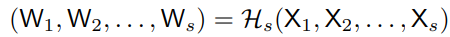
여기서 (X1, X2, ... , Xs) 는 s개의 resolution에 대한 input map이다. X1은 가장 높은 해상도에 해당하고 Xs는 s번째로 높은 해상도에 해당된다.
light weight 함수
본 논문은 다음과 같이 lightweight 함수 Hs()를 구현한다.
AAP(adaptive average pooling) 를 {X1, X2, . . . , Xs−1}: X1' = AAP(X1), X2' = AAP(X2), . . . , X's−1 = AAP(Xs−1) 에 사용하여 어떠한 input size를 받아도 Ws x Hs output size를 추출한다.
이후 1x1 convolution, ReLU, 1x1 convolution, sigmoid를 통해서 {X'1, X'2, ... , X's-1}와 Xs를 concatenate 하여 s partition에 해당하는 weight maps {W'1, W'2, ... , W's} (각 resolution에 대한 weight)를 생성한다.
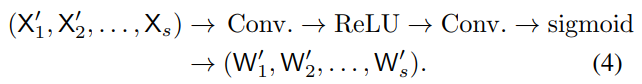
Here, the weights at each position for each resolution depend on the channel feature at the same position from the average-pooled multi-resolution channel maps. This is why we call the scheme as cross-resolution weight computation.
Weight maps {W'1, W'2, ... , W's} 은 해당 resolution에 대해 upsamped 되어 {W1, W2, ... , Ws} 을 output값으로 가진다.
Weight maps
Weight map은 결국 채널과 해상도 간에 정보 교환의 다리 역할을 하는 것을 알 수 있다.
각 position i 에 있는 weight vector w_si 는 같은 pooling region에 있는 모든 s개의 resolution과 모든 input 채널에서 정보를 받는다.
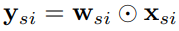
위 w_si weight vector를 통해 각 position에 대한 output channels들은 모든 resolution에 대해 같은 위치에 있는 모든 input channel의 정보를 지니게 된다.
결론적으로, channel weighting scheme은 1x1 convolution과 같이 정보 교환의 역할을 하는 것을 알 수 있다.
한편, Hs() 함수는 작은 resolution에 적용이 되어 계산 복잡도가 매우 낮다. 따라서 1x1 convolution보다 낮은 복잡도를 지닌다.
Spatial weight computation
각 해상도에 대해 spatial positions과 같은 의미를 지닌 spatial weights도 계산한다. 모든 position에 대한 weight vector w_si는 모두 같다.
Single resolution에 있는 input channel의 모든 pixel 값에 따라 weight이 정의된다.
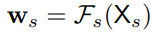
Fs() 함수는 모든 position에 대해 spatial 정보를 gathering 해준다.
Instantiation
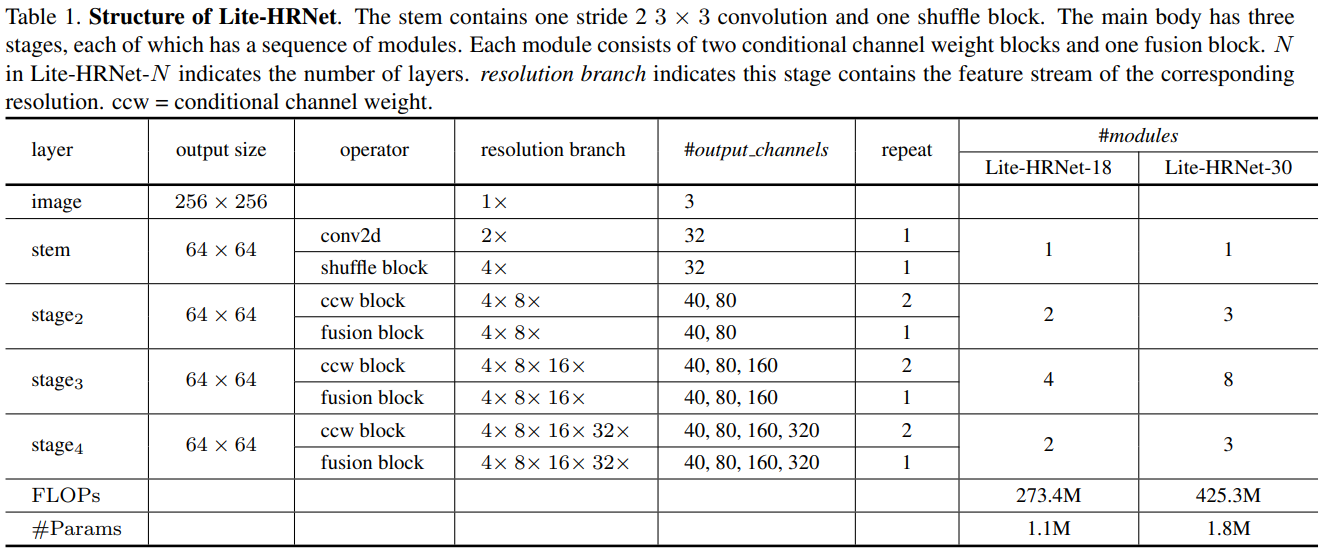
Lite-HRNet은 high-resolution stem을 이어 main body에는 high-resolution을 유지하는 구조를 가진다. Stem에서는 하나의 stride가 2인 3x3 convolution과 shuffle block을 가진다.
Main body는 모듈을 지니는데, 각 모듈들은 2개의 CCW (conditional channel weighting blocks)와 1개의 multi-resolution fusion을 가진다. 각 resolution brnach의 채널 dimension은 C, 2C, 4C, 8C이다.
