01 머신러닝
머신러닝은 일반적으로 애플리케이션을 수정하지 않고도 데이터를 기반으로 패턴을 학습하고 결과를 예측하는 알고리즘 기법을 통칭한다.
02 넘파이
Numerical Python을 의미하는 넘파이는 파이썬에서 선형대수 기반의 프로그램을 쉽게 만들 수 있도록 지원하는 대표적인 패키지다. 대량 데이터의 배열 연산이 가능하고, 빠른 연산 속도를 보장한다.
넘파이 array() 함수는 파이썬의 리스트와 같은 다양한 이자를 입력 받아 ndarray로 변환하는 기능을 수행한다. ndarray 배열의 shape 변수는 ndarray의 크기, 즉 행과 열 수를 튜플 형태로 지니며, ndarray 배열의 차원까지 알 수 있다.
np.array() : ndarray 로 변환하는 기능
import numpy as np
array = np.array([1,2,3])
array2 = np.array([[1,2,3],
[2,3,4]])
#array 의 형태 : (3,) --> 1차원 (행만 존재)
#array2 의 형태 : (2,3) --> 2차원 (2행 3열)ndarray 내의 데이터 타입은 같은 데이터 타입만 가능하다.
.ndim : 차원 추출
print('array2 : {:0}차원'.format(array2.ndim)).astype('type') : 타입 변경
np.arrange() : range()와 유사한 기능
np.zeros(), np.ones() : 0과 1로 채움
sequence_array = np.arange(10)
print(sequence_array)
zero_array = np.zeros((3,2), dtype = 'int32')
print(zero_array)
one_array = np.ones((2,3), dtype = 'int32)
print(one_array).reshape() : 차원과 크기를 변경
array1 = np.arrange(10)
#(-1,5)는 자동으로 2차원 (2,5)로 변환, 총 데이터는 10개
array2 = array1.reshape(-1,5)
#(5,-1)은 자동으로 2차원 (5,2)로 변환, 총 데이터는 10개
array3 = array1.reshape(5,-1).reshape(-1,1) 은 2차원으로의 변환을 뜻함
2-1 넘파이의 indexing
-
특정한 데이터 추출 : 원하는 위치의 인덱스 값을 지정하여 해당 위치의 데이터 반환
-
슬라이싱(Slicing) : 연속된 인덱스상의 ndarray 추출
array1 = np.arrange(start =1, stop = 10)
array3 = array1[1:-1]
print(array3)
>>>[2,3,4,5,6,7,8,9]- 펜시 인덱싱(Fancy Indexing) : 일정한 인덱싱 집합을 리스트 또는 ndarray형태로 지정해 해당 위치에 있는 데이터의 ndarray를 반환
- 불린 인덱싱(Boolean Indexing) : 특정 조건에 해당하는지 여부인 True/False 값 인덱싱 집합을 기반으로 True에 해당하는 인덱스 위치에 있는 데이터의 ndarray 반환
array1d = np.arrange(start =1, stop = 10)
array3 = array1d[array1d >5]
print(array3)
>>>[6,7,8,9]2-2 행렬의 정렬 - sort(), argsort()
np.sort() : 오름차순으로 정렬
내림차순으로 정렬하기 위해서는 np.sort()[::-1]과 같이 사용한다.
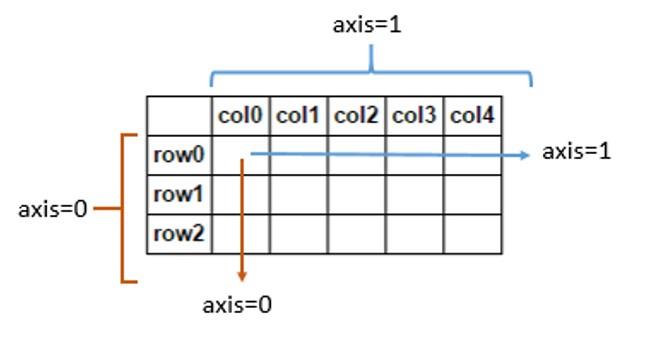
row방향 정렬 위해서는 np.sort(array, axis=0)
column방향 정렬 위해서는 np.sort(array, axis =1)
array2d = np.array([[8,12]
[7,1]])
sort_array2d_axis0 = np.sort(array2d, axis=0)
sort_array2d_axis1 = np.sort(array2d, axis=1)
>>>[[7 1]
[8 12]]
>>>[[8 12]
[1 7]]np.argsort() : 정렬 행렬의 원본 행렬 index를 추출
org_array = np.array([3,1,9,5])
sort_indices = np.argsort(org_array)
print(sort_indices)
>>>[1,0,3,2]03 데이터 핸들링 - 판다스
판다스는 2차원 데이터 핸들링을 가능하게 해준다. 리스트, 컬렉션, 넘파이 등의 내부 데이터 뿐만 아니라 csv 등의 파일을 쉽게 DataFrame으로 변경하여 데이터의 가공/분석을 편리하게 수행할 수 있게 만들어 준다.
판다스의 핵심 개체는 DataFrame이다. 행과 열로 이루어진 2차원 데이터를 담는 데이터 구조체를 DataFrame이라고 한다. Series와 DataFrame은 둘다 Index를 key값을 가지고 있다. 이 둘의 차이점은, Series는 칼럼이 하나뿐인 데이터 구조체이고, DataFrame은 칼럼이 여러개인 데이터 구조체라는 것이다.
pd.read_csv() : csv 파일 포맷 변환을 위한 API
df = pd.read_csv('경로').shape : 데이터프레임의 크기 (행,열)
.info() : 전체 행 열의 개수, 칼럼별 데이터 타입, non-null의 개수, 전체 칼럽 타입 요약 등이 포함되어있다.
.describe() : count, mean, std, min, 25%, 50%, 75%, max등이 포함되어있다.
.value_counts() : 해당 칼럽값의 유형과 건수를 확인가능하다.
df.value_counts()3-1 DataFrame의 칼럼 데이터 세트 생성과 수정
df.drop(axis = 0, inplace = False)
drop() 메서드에 axis = 1을 입력하면 열방향으로 드롭을 수행하겠다는 의미이다. labels에 원하는 칼럼 명을 입력하고 axis =1 을 입력하면 지정된 칼럽을 드롭한다.
axis = 0 으로 설정하고 행을 삭제하는 경우는 이상치 데이터를 삭제하는 경우에 주로 사용된다.
Inplace = False의 경우 기존 원본 데이터는 건들지 않는 것을 의미하고, Inplace = True의 경우 원본 데이터까지 변경함을 의미한다.
df['칼럼명'].min(), df['칼럼명'].max(), df['칼럼명'].sum() : 최소값, 최대값, 총합을 추출한다.
3-2 DataFrame 셀렉션 및 필터링
DataFrame의 [ ] 연산자
- 바로뒤의 [ ]연산자는 넘파이의 [ ]나 Series의 [ ]와는 다르다.
- DataFrame 바로 뒤의 [ ] 내 입력 값은 칼럼명을 지정해 칼럼 지정 연산에 사용하거나 불린 인덱스 용도로만 사용해야한다.
- DataFrame[0:2]와 같은 슬라이싱 연산으로 데이터 추출하는 방법은 사용하지 않는 게 좋습니다.
DataFrame의 iloc[ ] 연산자
iloc[ ] 는 위치 기반 인덱싱만 허용하기 때문에 행과 열 값으로 integer또는 integer형의 슬라이싱, 팬시 리스트 값을 입력해줘야 한다. 불린 인덱싱 제공하지 않는다.
#첫 번째 행 첫 번째 열 데이터 추출
df.iloc[0,0]
#인덱싱이 아닌 명칭을 입력하면 오류 발생
df.iloc[0, 'name'] --> 오류 발생DataFrame의 loc[ ] 연산자
loc[ ]는 명칭 기반으로 데이터를 추출하다. 따라서 행 위치에는 DataFrame의 index값을, 열 위치에는 "칼럼 명"을 입력해준다.
df.loc[1, 'name']불린 인덱싱 : df[조건식]
예를들어,
df = pd.read_csv('경로')
age_over_60 = df[df['age'] >60][['name','age']].head()
print(age_over_60)- and 조건 : &
- or 조건 : |
- Not 조건 : ~
3-3 정렬, Aggregation함수, GroupBy 적용
.sort_values(by = , ascending = True, inplace = False) : by에 따라 정렬하기
df_sorted = df.sort_values(by = ['name'] , ascending = True, Inplace = False)ascending = True : 오름차순으로 정렬
ascending = False : 내림차순으로 정렬
.groupby('칼럼 명') : 입력한 칼럼명을 기준으로 groupby된 DataFrame Groupby 객체를 반환한다.
df_group = df.group_by('col_name').count()3-4 결손 데이터 처리
칼럼에 값이 없는 NULL 형태의 처리
기본적으로 머신러닝 알고리즘은 NaN값을 처리하지 않으므로 다른 값으로 대체해야한다.
NaN값은 평균, 분산, 총합 등의 함수 연산 시 제외된다.
.isna() : NaN의 확인 여부
df.isna().sum()
#각 칼럼별로 NaN의 총합을 보여준다..fillna() : 결손 데이터 대체하기
df['col_name'] = df['col_name'].fillna('hi')3-5 apply lambda 식으로 데이터 가공
lambda x : x2 에서 :로 입력인자와 반환될 입력 인자의 계산식을 분리한다. :의 왼편이 입력인자, 오른편이 반환 값을 의미한다.
a=[1,2,3]
squares = map(lambda x : x**2, a)
list(squares)
>>>[1,4,9].apply(lambda x : x 계산식)
df['name_len'] = df['name'].apply(lambda x : len(x))
df[['name','name_len']].head()
#df['name']이 x에 들어갈 입력인자