
[ HTTP란? ]
하이퍼텍스트를 빠르게 교환하기 위한 프로토콜의 일종으로 서버와 클라이언트 사이에서 어떻게 메시지를 교환할지를 정해놓은 규약이다.
요청(Request)와 응답(Response)로 구성되어있으며 일반적으로 80번 포트를 사용한다.
우리가 사용하는 웹 브라우저에서 인터넷 주소 맨 앞에 들어가있는 http://가 바로 이 프로토콜을 사용해서 정보를 교환하겠다는 표시인 것이다.
[ HTTP 특징 ]
[ 클라이언트 - 서버 구조 ]
클라이언트가 서버에 요청을 보내면 서버는 그에 대한 결과를 응답해주는 단방향 통신이다.
HTTP는 클라이언트에서 서버로 요청하는 단방향 통신이다. 서버는 클라이언트에 요청을 하지 않으며 클라이언트의 요청에 대한 응답만을 할 뿐이다.
클라이언트의 요청에 대한 서버의 응답에는 요청 처리 결과에 따라 응답 코드가 다르게 나온다. 따라서 응답 코드 별로 처리 로직을 만들어 서버의 상황에 대응이 가능하다.
[ Stateless ]
서버는 클라이언트의 상태를 저장하지 않는다.
HTTP 통신에서 서버는 클라이언트의 상태를 저장하지 않는다. 클라이언트의 상태를 저장하지 않는다는것은 클라이언트가 이전에 했던 요청이 무엇인지에 따라 서버 응답이 바뀌지 않는다는 것이다.
Stateless가 중요한 이유는 서버가 확장 가능(Scale-Out)해야하기 때문이다. 보통 대규모 트래픽이 발생하는 서비스에서는 서버가 여러대로 운영되고 있다. 서버가 많아지면 많아질수록 서로 간에 정보를 공유해야되는 비용이 비싸진다.
Stateless하게 사용할 경우 정보 공유가 최소화되어 정보를 공유하기 위한 비용을 최소화 할 수 있다.
Stateful의 한계를 극복하고자 클라이언트는 이전에 자신이 요청한 정보를 저장해놓고 새로운 요청을 보낼따마다 해당 메시지를 함께 보낸다.
[ Connectionless ]
HTTP는 연결 상태를 유지하지 않는 비연결성이다.
HTTP 통신은 연결을 유지하지 않는 것을 기본 동작으로 가진다. 기본 동작으로는 Connection을 유지하지 않지만 별도의 옵션을 두면 일정기간동안 유지하게 할 수도 있긴하다.
Connection을 유지하지 않는 것을 기본 동작으로 가지는 이유는 Connection을 유지하게 되면 지속적으로 서버 리소스가 사용되기 때문이다. 따라서 Connection 유지는 최소화하는 것이 좋다.
[ HTTP 통신 과정 ]
- 웹 브라우저에서 URL(https://www.google.com) 입력
- 브라우저가 URL를 파싱하여 Http Reqeust Message를 만들고, OS에 전송 요청을 의뢰한다.
이떄, Domain으로 요청을 보낼 수 없기 때문에 DNS Lookup를 수행하여 Domain에 해당 되는 IP 주소를 가져온다. - 프로토콜 스택이라는 OS에 내장 된 네트워크 제어용 소프트웨어에 의해 패킷에 담기고, 패킷에 제어 정보를 덧붙여 LAN 어뎁터로 전송한다.
- LAN 어뎁터는 전달받은 패킷을 전기신호로 변환시켜 송출한다.
- 패킷은 스위칭 허브 등을 경유하여 인터넷 접속용 라우터에서 ISP로 전달되고 인터넷으로 이동한다.
- 엑세스 회선에 의해 통신사용 라우터로 운반되고 인터넷의 핵심부로 전달된다. 고속 라우터들 사이로 목적지까지 패킷이 흘러들어가게 된다.
- 핵심부를 통과한 패킷은 목적지의 LAN에 도착하고, 방화벽이 패킷을 검사한후에 캐시 서버로 보내어 웹 서버에 갈 필요가 있는지 확인한다.
- 웹 서버에 도착한 패킷은 프로토콜 스택이 패킷을 추출하여 메시지를 복원하고 웹 서버 애플리케이션에 넘긴다.
- 웹 서버 애플리케이션은 요청에 대한 응답 메시지를 만들어 클라이언트로 전송하고, 이는 전달 된 방식과 동일하다.
[ HTTP 버전별 특징 ]
[ HTTP 0.9 - 원 라인 프로토콜 ]
HTTP 초기 버전에는 버전 번호가 없었다. HTTP/0.9는 이후에 차후 버전과 구별하기 위해 0.9로 불리게 되었다.
HTTP/0.9는 매우 단순하다. 요청은 단일 라인으로 구성되며 리소스에 대한 경로로 가능한 메소드는 GET이 유일하였다.
다음은 HTTP/0.9로 Request / Response하는 예제이다.
[ Request ]
GET /mypage.html[ Response ]
<HTML>
A very simple HTML page
</HTML>위 예제와 같이 Response에 헤더가 없고, HTML 파일만 전송될 수 있었다. 다른 유형의 문서(JSON, XML 등)는 전송될 수 없었고, 상태 혹은 오류코드 또한 포함되지 않았다.
문제가 발생한 경우, 특정 HTML 파일이 사람이 직접 처리할 수 있도록 응답 HTML 내부에 문제에 대한 설명을 포함한다.
[ HTTP 1.0 - 확장성 만들기 ]
HTTP/0.9는 매우 제한적이었으며 브라우저와 서버 모두 좀 더 융통성을 가지도록 빠르게 확장되었다.
- 버전 정보가 Response에 포함되기 시작하였다.
- 상태 코드 라인 또한 응답의 시작 부분에 포함되어, 브라우저가 요청에 대한 성공 여부를 판단할 수 있게되었고, 응답에 대한 후처리를 할수 있게 되었다.
- HTTP 헤더가 Request / Response에 포함되어, 메타 데이터 정보를 송수신할수 있게 되었고 HTML외 다른 파일을 전송할 수 있게 되었다. (Content-Type 덕분에)
다음은 HTTP/1.0으로 Request / Response하는 예제이다.
[ Request ]
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)[ Response ]
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<HTML>
A page with an image
<IMG SRC="/myimage.gif">
</HTML>[ Request(Image) ]
GET /myimage.gif HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)[ Response(Image) ]
200 OK
Date: Tue, 15 Nov 1994 08:12:32 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/gif
(image content)[ HTTP 1.1 - 표준 프로토콜 ]
HTTP의 첫번째 표준 버전인 HTTP/1.1은 HTTP/1.0이 나온지 몇달 안되서 1997년 초에 공개되었다. HTTP/1.0 대비 가장 큰 특징은 다음과 같다.
- 커넥션 유지 (Persistent Connection)
- 호스트 헤더 (Host Header)
- 강력한 인증 절차 (Improved Authentication Procedure)
[ 커넥션 유지 (Persistent Connection) ]
HTTP 프로토콜은 클라이언트 - 서버 간 데이터를 주고 받는 응용 계층의 프로토콜이다.
HTTP를 이용한 데이터 전달은 TCP 세션 기반에서 이루어 진다.
HTTP 1.0와 HTTP 1.1의 차이는 TCP 세션을 지속적으로 유지할수 있느냐? 없느냐에 차이를 둔다.
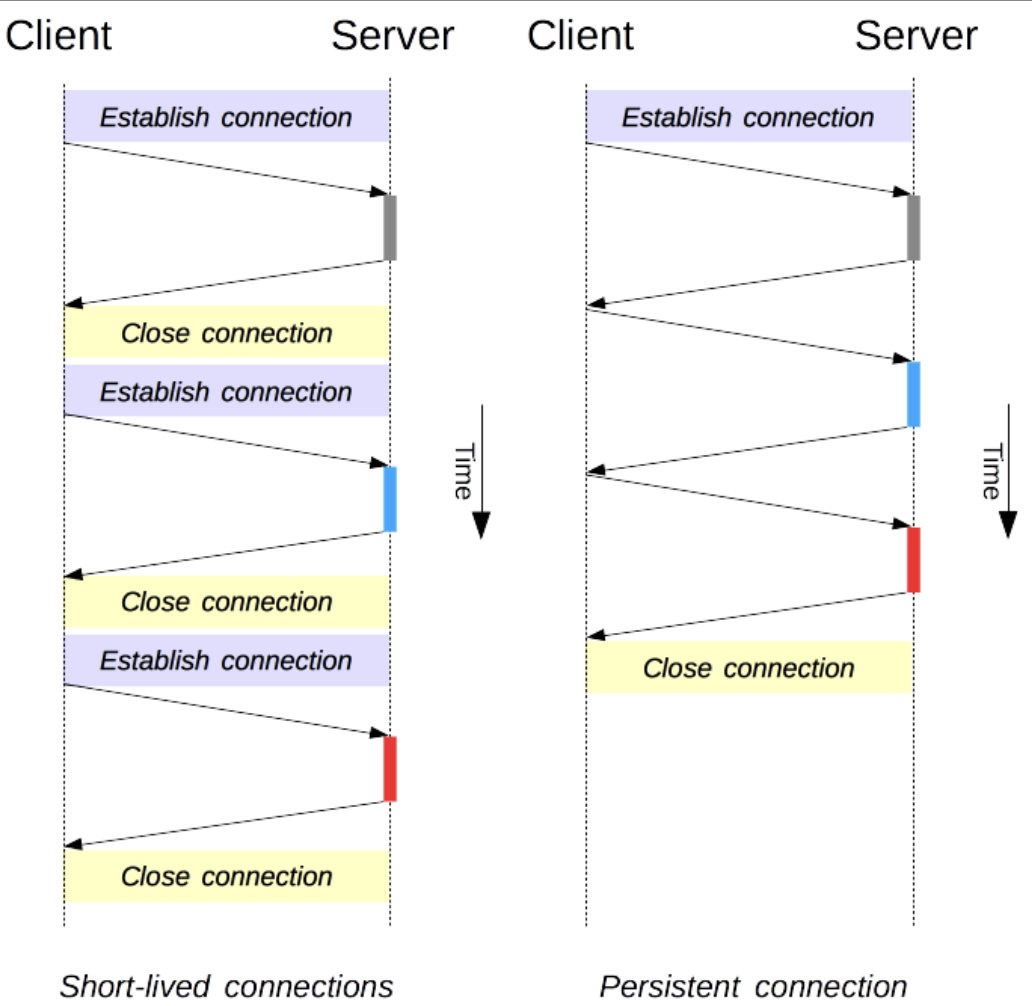
위 그림과 같이 HTTP 1.0은 서버로 요청할때마다 TCP 커넥션(+ 3-Way HandShake)을 맺어야 한다.
(1 GET / 1 Connection)
반면 HTTP 1.1은 Persistent 기능을 이용하여 한개의 TCP 커넥션을 통해 다수의 요청이 가능하다.
(N GET / 1 Connection)
이러한 특성덕분에 서버는 TCP 커넥션 부하를 줄일 수 있고, 클라이언트에게 응답 속도를 높일 수 있다.
단점으로는 유휴 상태일때에도 서버 리소스가 사용되어 효율적이지 않을 수도 있다.
[ 파이프라이닝(Pipelining) ]
Persistent 기능을 통한 커넥션 유지와 함께 HTTP 1.1에서 지원되는 기능이 하나 더 있다.
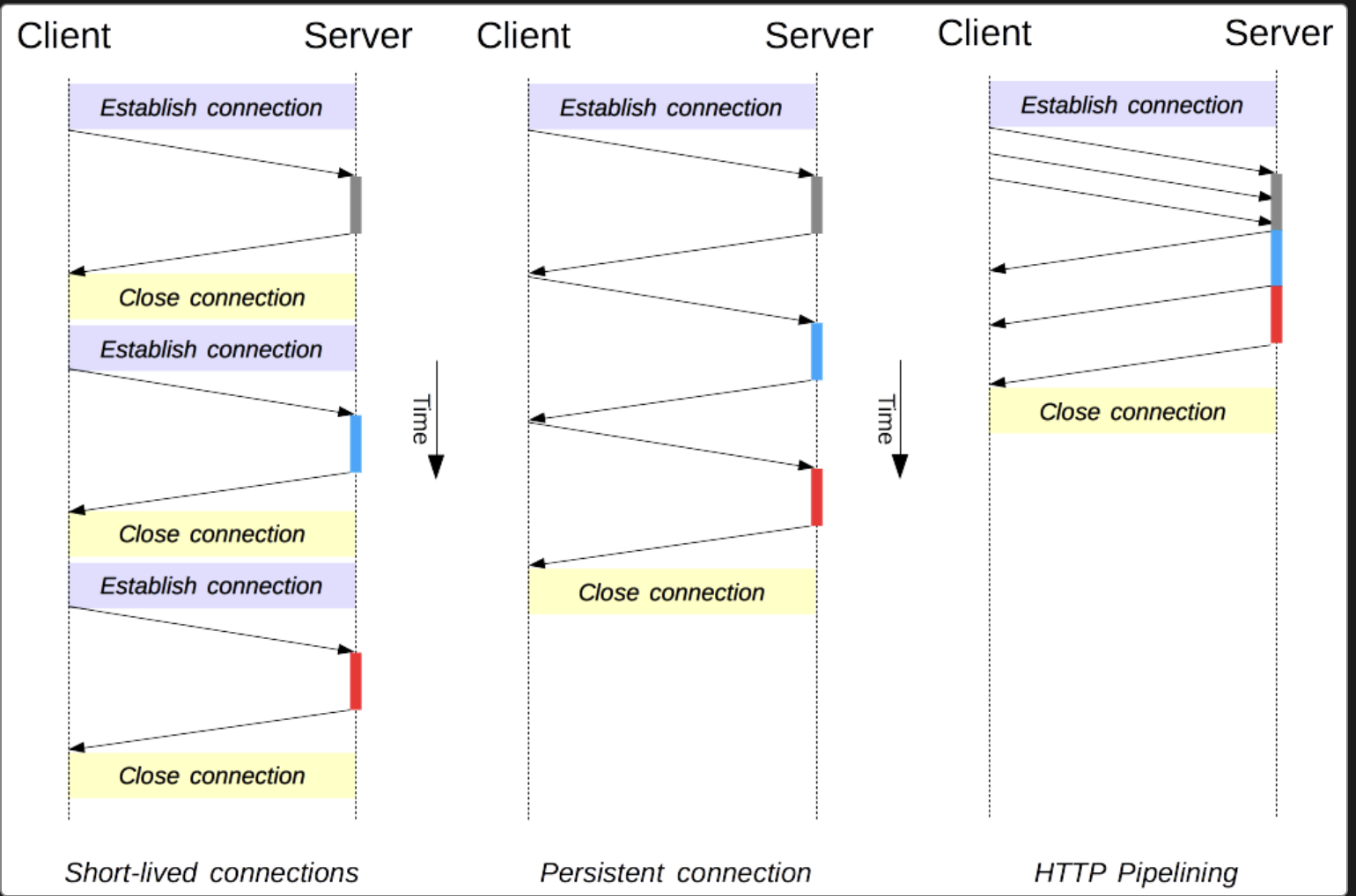
HTTP 통신은 순차적으로 이루어진다. 위 그림과 같이 3개의 컨텐츠를 요청한다고 가정하면 파이프라인이 없는 경우 Req#1 -> Res#1 -> Req#2 -> Res#2 -> Req#3 -> Res#3와 같이 순차적으로 진행된다.
즉, Req#1에 대한 Res#1을 정상적으로 응답받아야 나머지 요청도 진행되기 때문에 어떠한 문제로 인하여 Req#1 요청이 실패한다면 Req#2, Req#3은 진행되지 못한다.
만약 문제가 없더라도 순차적으로 진행되기에 비효율적이다.
파이프라이닝은 이를 개선한 기술이다.
위 그림과 같이 요청에 대한 응답을 기다리지않고 Req#1, Req#2, Req#3요청을 연속적으로 보낼 수 있다. 이렇게 요청간 대기 시간을 없앰으로써 커넥션을 효율적으로 사용할 수 있다.
(파이프라이닝은 HOL 문제가 있어, HTTP/2에서는 멀티플렉싱으로 대체 되었다)
[ 호스트 헤더 (Host Header) ]
HTTP 1.0은 하나의 IP 주소에 여러개의 도메인을 운영 할 수 없었다. 따라서 도메인 별로 IP를 구분해서 사용해야 하였기 때문에 서버의 개수가 늘어나야 했다. 하지만 HTTP 1.1은 가상 호스팅이 가능해졌기 때문에 하나의 IP 주소에 여러 개의 도메인을 적용시킬 수 있다.
[ 강력한 인증 절차 (Improved Authentication Procedure) ]
HTTP 1.1은 다음과 같은 2개의 header가 추가되었다.
- proxy-authentication
- proxy-authorization
실제 서버에서 클라이언트 인증을 요구하는 www-authentication 헤더는 HTTP/1.0부터 지원되었으나, 서버와 클라이언트 사이에 프록시가 있는 경우 프록시가 사용자의 인증을 요구할 수 있는 방법이 없었다.
그러나 위와 같은 헤더가 추가되어 프록시가 사용자 인증을 요구하는게 가능해졌고, 이를 통해 인증 절차가 향상되었다.
[ HTTP 2.0 - 더 나은 성능을 위한 프로토콜 ]
HTTP 2.0은 기존 HTTP 1.1 버전의 성능 향상에 초첨을 맞춘 프로토콜이다. 인터넷 프로토콜 표준의 대체가 아닌 확장으로써, HTTP 1.1은 한번에 한가지 파일만 전송이 가능하였다.
파이프라이닝이라는 기술이 있었지만, 여러 파일을 한꺼번에 전송 할 경우 선행하는 파일의 전송 속도가 늦어지면 HOL Blocking이 발생하였다.
따라서 HTTP 2.0에서는 이 문제를 해결하기 위해 여러 파일을 한번에 병렬로 전송한다.
[ SPDY 프로토콜 ]
HTTP 2.0의 원조는 구글에서 만든 SPDY 프로토콜이다.
HTTP 1.1의 메시지 포맷은 구현의 단순성과 접근성에 주안점을 두고 최적화 된 프로토콜이다 보니 성능은 어느 정도 희생시키지 않을 수 없었다. 때문에 더 효율적이고 빠른 HTTP가 필요했고, 이러한 요구 사항에 만들어진것이 구글의 SPDY 프로토콜이다.
SPDY은 HTTP를 대체하는 프로토콜이 아니고 HTTP를 통한 전송을 재정의하는 형태로 구현되었다. 그래서 전송 계층의 구현만 변경하면 기존 HTTP 프로그램을 그대로 SPDY에서 사용할 수 있었다.
점차 SPDY 프로토콜을 사용하는 사이트가 늘어나게 되고, 이러한 상황을 주시하고 있었던 HTTP WG(Working Group)은 HTTP 2.0 표준을 선보이려는 노력을 했고 이 프로토콜의 초안을 SPDY 프로토콜로 채택하였다.
[ HTTP 2.0 개선점 ]
[ Binary Framing Layer ]
HTTP 1.1에서는 메시지가 text로 전송되었던과는 달리 HTTP 2.0에서는 binray frame으로 인코딩되어 전송된다는 점이다.
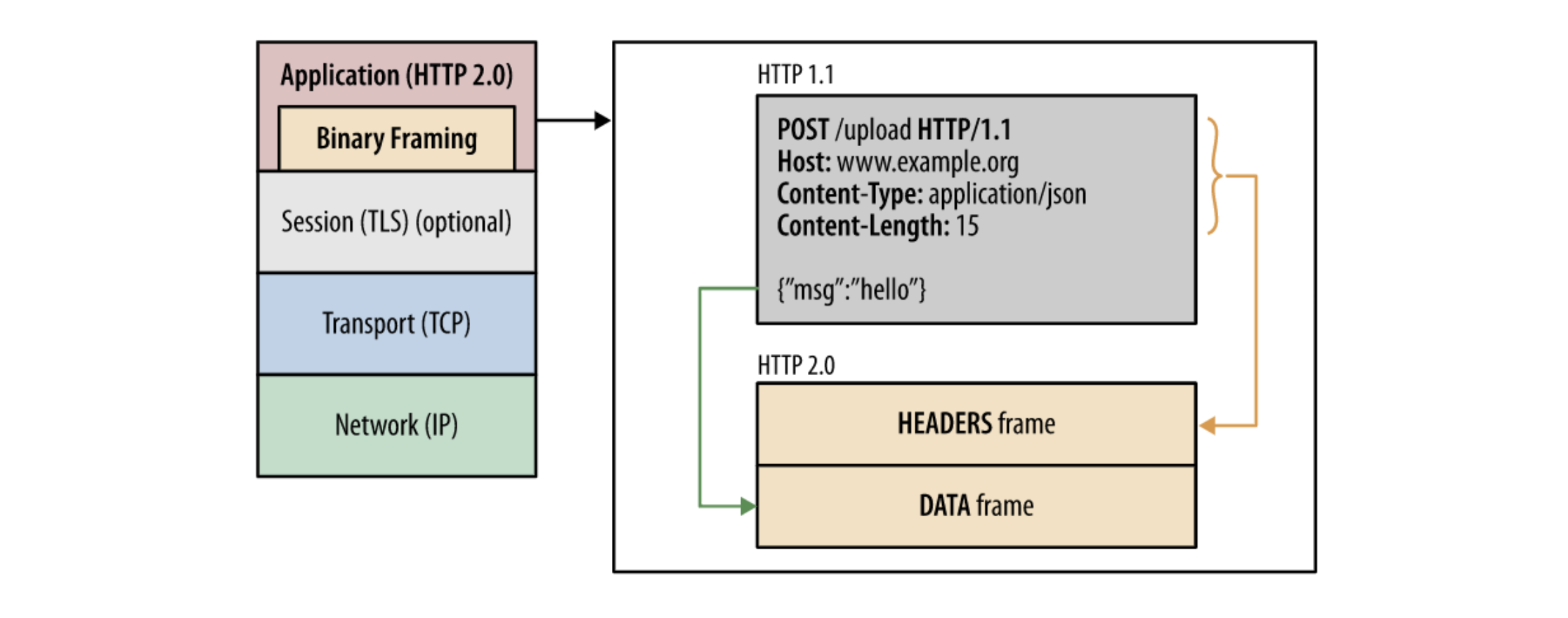
또한 HTTP 헤더는 개행 문자로 구분이 되었지만, HTTP 2.0에서는 헤더와 바디가 Layer로 구분된다.
이로인해 데이터 파싱 및 전송 속도가 증가하였고 오류 발생 가능성이 줄어들었다.
[ Stream와 Frame 단위 ]
HTTP 1.1에서는 HTTP 요청과 응답은 Plain Text Message 단위로 구성되어 있었다.
HTTP 2.0부터 Message 단위외에 Frame, Stream 이라는 단위가 추가되었다.
- Frame : HTTP 2.0에서 통신의 최소 단위이며, Header 혹은 Data가 들어가있다.
- Message : HTTP 1.1와 마찬가지로 요청 혹은 응답의 단위이며, 다수의 Frame으로 이루어져 있다.
- Stream : 연결된 Connection에서 양방향으로 Message를 주고받는 하나의 흐름
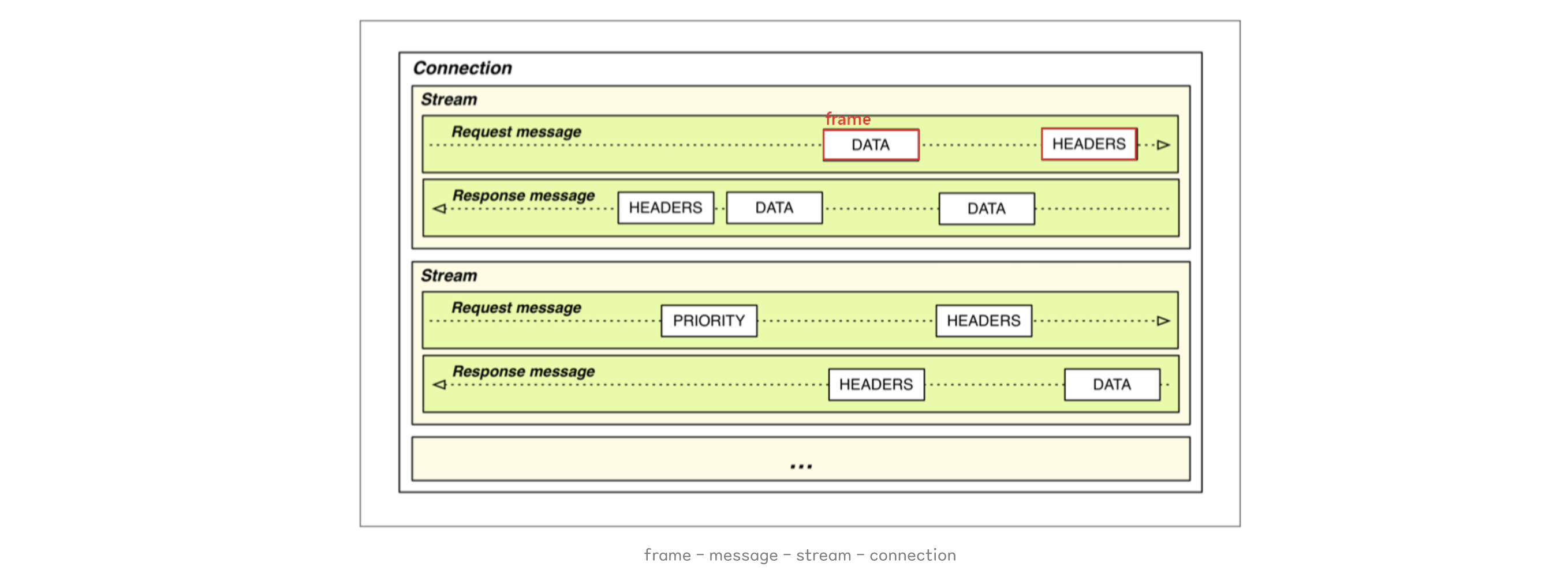
즉, HTTP 2.0은 HTTP 요청을 다수의 Frame들로 나누고, 이 Frame들이 모여 요청 / 응답하는 Message로 이루어진다.
그리고 Message는 특정 Stream에 속하게 되고, 여러개의 Stream은 하나의 Connection에 속하게 된다.
이처럼 프레임 단위로 이루어진 요청과 응답 메시지는 하나의 스트림을 통해 이루어지며, 이런 스트림들이 하나의 커넥션에서 병렬적으로 처리되기 때문에 성능이 향상된다.
[ Multiplexing ]
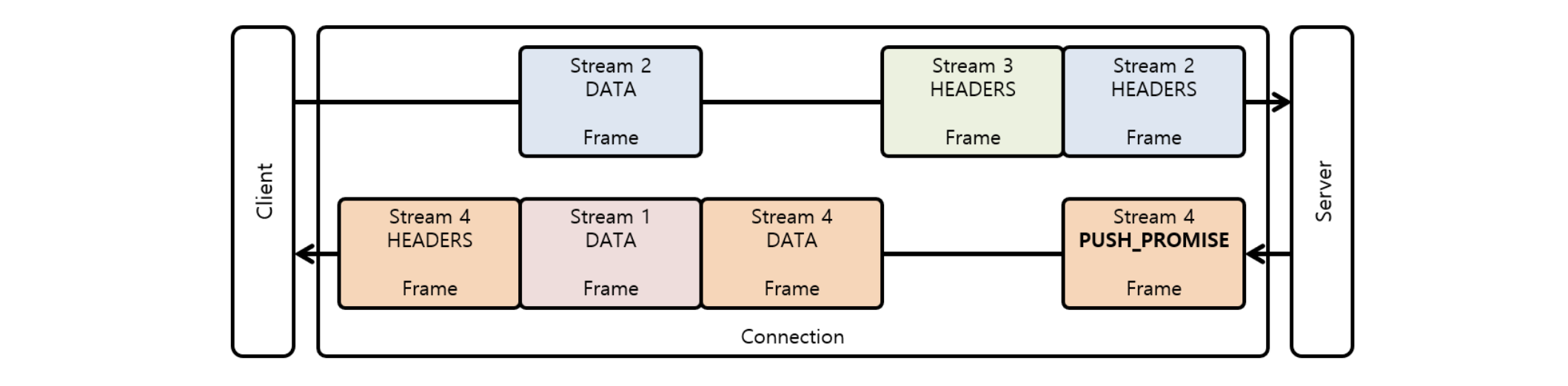
HTTP 헤더 메시지를 바이너리 형태의 프레임으로 나누고 하나의 컨넥션에서 동시에 여러개의 메시지 스트림을 응답 순서에 상관없이 주고 받는 것을 멀티플렉싱이라고 한다.
- HTTP 1.1의 Connection Keep-Alive, Pipelining, HOL Blocking 문제를 개선
- latency만 줄여주는게 아니라 결국 네트워크를 효율적으로 사용할 수 있게 하고 그 결과 네트워크 비용이 줄어든다.
[ Server Push ]
HTTP 2.0에서는 클라이언트의 요청에 대해 미래에 필요할것같은 리소스를 미리 보낼 수 있다.
- 서버가 클라이언트로부터 Req#1을 받으면 html 파일에 있는 자원들을 파싱한다.
- 클라이언트가 요청하지않아도, 서버가 알아서 미리 자원들을 클라이언트에 보낸다.
- 따라서 총 로드 시간이 줄어드는 이점이 있다.
[ Stream Prioritization ]
HTTP 1.1의 파이프라이닝은 우선 순위 때문에 HOL Blocking 문제가 발생했었다. HTTP 2.0에서는 리소스간 의존관계(우선순위)를 설정하여 이런 문제를 해결하였다.
HTTP 메시지가 개별 바이너리 프레임으로 분할되고, 여러 프레임을 멀티플렉싱 할 수 있게 되면서 요청과 응답이 동시에 이루어져 속도 향상이 되었다.
하지만 하나의 컨넥션에 여러 요청과 응답의 패킷 순서가 뒤섞여버리게 되었다. 따라서 스트림들의 우선 순위를 지정할 필요가 생겼는데, 클라이언트는 우선순위 지정 트리를 사용하여 스트림에 식별자를 설정함으로써 해결하였다.
- 각각의 스트림은 1-256 까지의 가중치를 갖는다.
- 하나의 스트림은 다른 스트림에게 명확한 의존성을 갖는다.
[ 스트림 우선순위 통신 과정 ]
1. 클라이언트는 서버에게 스트림을 보낼때, 각 요청 자원에 가중치 우선순위를 지정하고 보낸다.
2. 그렇게 요청 받은 서버는 우선순위가 높은 응답이 클라이언트에 우선적으로 전달될 수 있도록 대역폭을 설정한다.
3. 응답 받은 각 프레임에는 이것이 어떤 프레임인지에 대한 고유한 식별자가 있어, 클라이언트는 여러개의 스트림을 interleaving을 통해 서로 끼워놓는 식으로 조립한다.
[ HTTP Header Data Compression ]
HTTP 1.1에서 헤더는 아무런 압축 없이 그대로 전송되었다. 이를 개선하기 위해 HTTP 2.0에서는 HTTP 메시지의 헤더를 압축하여 전송한다.
또한 HTTP 1.1에서는 연속적으로 요청되는 HTTP 메시지들에게서 헤더값이 중복되는 부분이 많아 역시 메모리가 낭비되었는데, HTTP 2.0에서는 이전 메시지의 헤더의 내용 중 중복되는 필드를 재전송하지 않도록 하여 데이터를 절약할 수 있게 되었다.
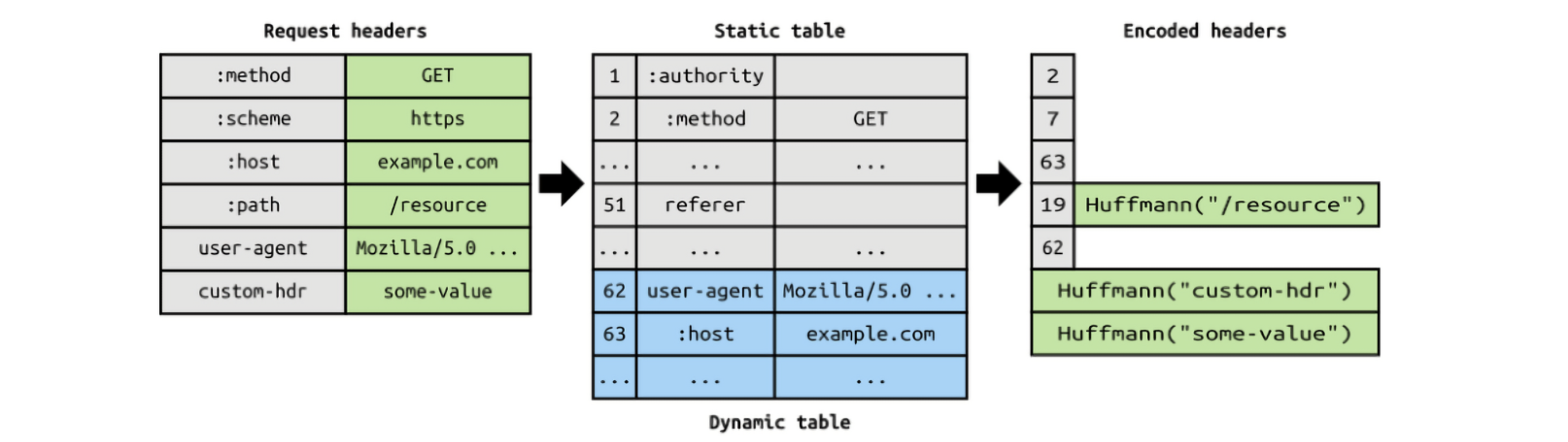
만약 메시지 헤더에 중복값이 존재하는 경우, 위 그림에서 Static / Dynamic table 개념을 사용하여 중복 헤더를 검출하고, 중복된 헤더는 index값만 전송하고 중복되지 않은 Header 정보의 값은 호프만 인코딩 알고리즘을 사용하는 HPACK 압축 방식으로 인코딩 처리 하여 전송하여, 데이터 전송 효율을 높였다고 보면 된다.
[ HTTP 2.0 문제점 ]
- RTT Latency
- HTTP 2.0역시 TCP를 이용하기 때문에 Handshake의 RTT로 인한 지연 시간(Latency)이 발생한다. 결국 TCP로 통신하는게 문제인 것이다.
- TCP 자체의 HOL Blocking
- HTTP 2.0에서 HTTP 1.1의 파이프라이닝 HOLB 문제를 멀티플렉싱을 통해 해결했다고 하였다.
하지만 TCP는 패킷이 유실되거나 오류가 있을때 재전송하는데, 이 재전송 과정에서 패킷의 지연이 발생하면 결국 HOLB 문제가 발생된다.
TCP/IP 4 계층을 보면, 애플리케이션 계층에서 HTTP HOLB를 해결하였다 하더라도, 전송 계층(L3)에서의 TCP HOLB를 해결한건 아니기 때문이다.
- HTTP 2.0에서 HTTP 1.1의 파이프라이닝 HOLB 문제를 멀티플렉싱을 통해 해결했다고 하였다.
- 중개자 캡슐화 공격
- HTTP 2.0은 헤더 필드의 이름과 값을 바이너리로 인코딩한다. 이를 다르게 말하면 HTTP 2.0이 헤더 필드로 어떤 문자열이든 사용할 수 있게 해준다는 뜻이다.
그래서 이를 악용하면 HTTP 2.0 메시지를 중간의 Proxy 서버가 HTTP 1.1 메시지로 변환할 때 메시지를 위조할 수 있는 리스크가 있다.
- HTTP 2.0은 헤더 필드의 이름과 값을 바이너리로 인코딩한다. 이를 다르게 말하면 HTTP 2.0이 헤더 필드로 어떤 문자열이든 사용할 수 있게 해준다는 뜻이다.
- 오랫동안 커넥션 유지로 인한 개인정보 노출 우려
- HTTP 2.0은 기본적으로 성능을 위해 클라이언트와 서버 사이의 커넥션을 오래 유지하는 것을 염두에 두고 있다.
하지만 이것은 개인 정보의 유출에 악용될 가능성이 있으며, HTTP 1.1에서의 Keep-Alive도 동일한 문제를 가지고 있다.
- HTTP 2.0은 기본적으로 성능을 위해 클라이언트와 서버 사이의 커넥션을 오래 유지하는 것을 염두에 두고 있다.
[ 참고사이트]
https://kotlinworld.com/97
https://inpa.tistory.com/entry/WEB-%F0%9F%8C%90-HTTP-20-%ED%86%B5%EC%8B%A0-%EA%B8%B0%EC%88%A0-%EC%9D%B4%EC%A0%9C%EB%8A%94-%ED%99%95%EC%8B%A4%ED%9E%88-%EC%9D%B4%ED%95%B4%ED%95%98%EC%9E%90
