해시 테이블
-
해시함수 : 임의의 길이의 데이터를 고정 길이의 데이터(해시)로 매핑하는 함수
-
리스트에서 어떤 값을 찾으려면 리스트를 한번 순회해야 함, 시간복잡도 O(N)
-
해시함수로 데이터 저장 시 값이 있는 위치에 바로 접근 가능하여 시간복잡도 O(1)
-
-
해시 : 해시 함수를 통해 얻어진 값
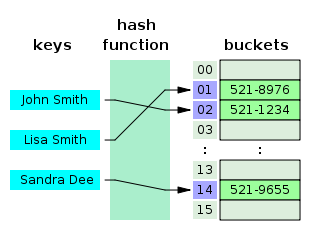
파이썬의 dictionary와 set은 해시함수와 해시 테이블을 사용한다.
딕셔너리 Dictionary
-
키-값(key : value) 쌍으로 이루어진 모음(collection)
-
Hash function을 이용한 산술 계산으로 값이 있는 위치를 바로 알 수 있음
-
삽입, 삭제, 수정, 조회 연산의 속도가 리스트보다 빠름
-
키는 불변 자료형만 가능, 값은 모든 형태 가능
-
변경 가능하며(mutable), 반복 가능함(iterable)
-
기본형태
dic = {key : value, key : value, key : value ...} # 중괄호
키-값 추가 및 변경
score = {'홍길동': 100, '최수현': 90}
score['홍길동'] = 50 # {'홍길동': 50, '최수현': 90} 변경
score['김철수'] = 80 # {'홍길동': 50, '최수현': 90, '김철수': 80} 추가키-값 삭제
score = {'홍길동': 50, '최수현': 90, '김철수': 80}
score.pop('홍길동')
# score = {'최수현': 90, '김철수': 80}딕셔너리 순회
- 딕셔너리는 기본적으로 key순회
grades = {'john': 80, 'eric': 90}
for name in grades:
print(name) # john, ericgrades = {'john': 80, 'eric': 90}
for name in grades:
print(name, grades[name]) # john 80, eric 90자주 사용하는 메서드
-
d.clear() : 모든 항목 제거
-
d.keys() : 모든 키를 담은 뷰 반환
-
d.values() : 모든 값을 담은 뷰 반환
-
d.items() : 모든 키-값의 쌍을 담은 뷰 반환
grades = {'john': 80, 'eric': 90} print(grades.keys()) # dict_keys(['john', 'eric']) print(grades.values()) # dict_values([80, 90]) print(grades.items()) # dict_items([('john', 80), ('eric', 90)]) -
d.get(k) : key의 값을 반환, key가 존재하지 않을 시 None반환(get 안쓰면 원래는 Key Error)
drama = {'name' = '더글로리', 'writer' = '김은숙' } print(drama['director']) # KeyError print(drama.get('director')) # None -
d.get(k, v) : key의 값을 반환, key가 존재하지 않을 경우 v 반환
-
d.pop(k) : key의 값을 반환 후 삭제, 없는 경우 KeyError
-
d.pop(k, v) : key의 값을 반환 후 삭제, 없는 경우 v 반환
-
d.update([other]) : 딕셔너리의 값을 매핑하여 업데이트
세트 Set
-
유일한 값들의 모음(collection)
-
수학에서
집합을 나타내는 데이터 구조로 Python에서는 기본적으로 제공 -
순서가 없고 중복된 값 없음
-
변경 가능(mutable), 반복 가능(iterable)
-
데이터의 중복이 없어야 할 때, 정수가 아닌 데이터의 삽입/삭제/탐색이 빈번히 필요할 때 사용
생성
-
중괄호({}) 또는 set()을 통해 생성
-
{}은 딕셔너리가 되기에 빈 set을 만들기 위해서는 set()사용
-
순서가 없어 별도의 값에 접근 불가능
활용
-
다른 컨테이너에서 중복된 값 제거
-
이후 순서 무시되므로 순서가 중요한 경우 사용 불가
my_list = ['서울', '서울', '대전', '광주']
len(set(my_list)) # 3
set(my_list) # ['서울', '대전', '광주']set의 연산
- .add()
- .remove()
- | : 합집합
- - : 차집합
- & : 교집합
- ^ : 대칭차집합
set의 시간복잡도
| 연산 종류 | 시간 복잡도 |
|---|---|
| 탐색 | O(1) |
| 제거 | O(1) |
| 합집합 | O(N) |
| 교집합 | O(N) |
| 차집합 | O(N) |
| 대칭 차집합 | O(N) |
자주 사용하는 메서드
-
s.copy() : 세트의 얕은 복사본 반환
-
s.add(x) : x 추가
-
s.pop() : 랜덤으로 항목을 반환 후 제거
-
s.remove(x) : x 삭제
-
s.discard(x) : x 삭제
-
s.update(t) : 세트 t에 있는 항목 중 세트 s에 없는 항목 추가
-
s.clear() : 모든 항목 제거
-
s.isdisjoint(t) : 세트 s와 세트 t의 교집합 없는 경우 True 반환
-
s.issubset(t) : 세트 s가 세트 t의 하위세트인 경우 True 반환
-
s.issuperset(t) : 세트 s 가 세트 t의 상위 세트인 경우 True 반환
