Intro
지난 글에서 Docker와 NGINX를 사용하여 블루-그린 무중단 배포를 구현한 과정을 정리해보았다. 하지만 문제는 완전한 무중단 배포가 아니라 다운타임이 존재한다는 것이었다.
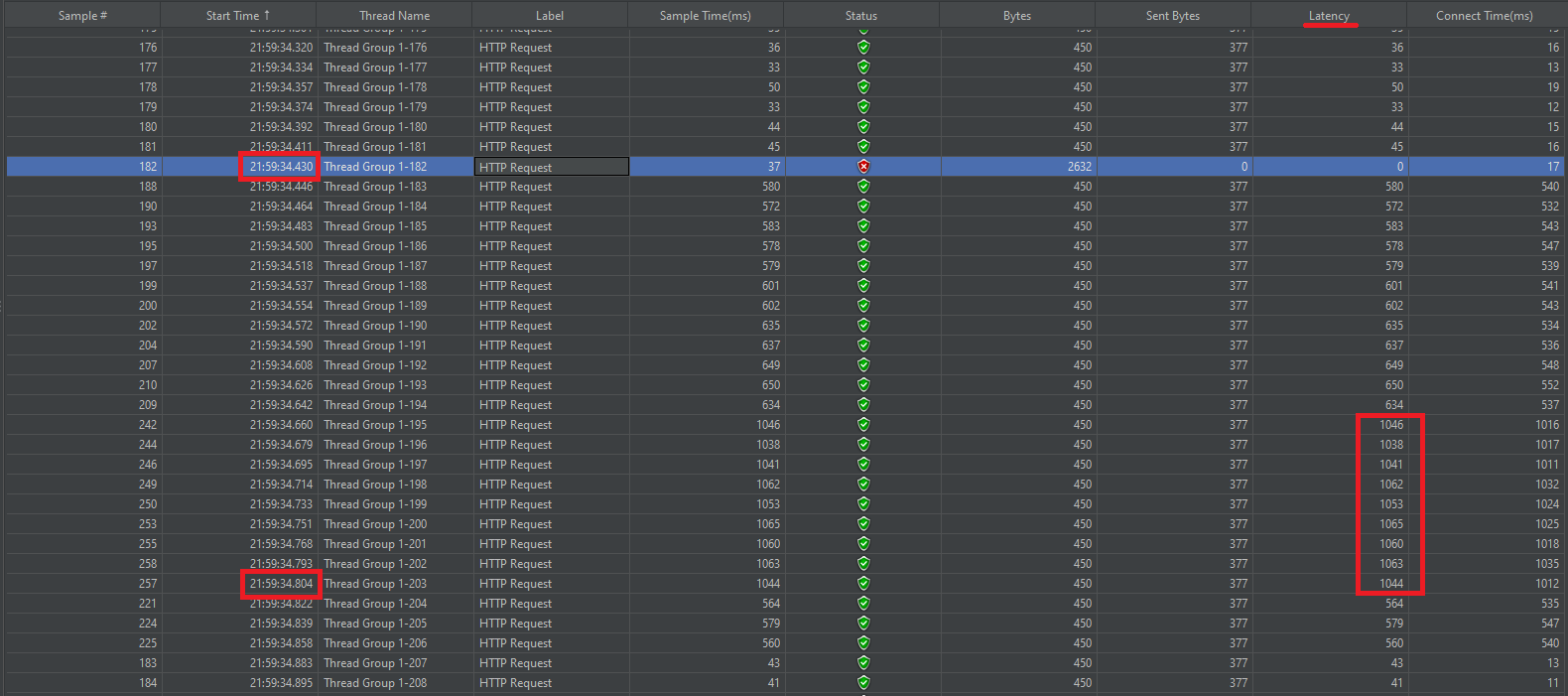
JMeter로 테스트한 결과 Docker로 띄운 NGINX 컨테이너가 재시작되는 시점에 요청 1개를 처리하지 못했고 이후에 재시작된 컨테이너가 요청을 처리할 수 있는 상태가 되기까지 최대 1초 정도 요청 처리에 지연이 발생했다.
여기서 들었던 생각은 1초 미만의 다운타임도 없앨 수 있을까?였다. 그래서 이번 글에서는 다운타임을 없애기 위해 학습하고 테스트한 내용을 정리해보겠다.
NGINX 시그널
NGINX를 재시작하지 않고 설정을 변경할 수 있는 방법을 찾아보다 NGINX 시그널을 알게 되었다.
이는 실행되고 있는 NGINX를 컨트롤 하기 위한 것으로 다음과 같이 사용할 수 있다.
nginx -s signal그리고 시그널의 종류는 다음과 같다.
stop: fast shutdownquit: graceful shutdownreload: reloading the configuration filereopen: reopening the log files
이 중에서 설정 파일을 다시 불러오는 reload를 사용해보겠다!
reload

NGINX 공식문서를 보면 nginx -s reload 명령을 입력하면 일어나는 일은 다음과 같다.
-
reload시그널이 마스터 프로세스에 전달된다. -
마스터 프로세스는 변경된 설정파일의 문법을 검사하고 적용하려고 시도한다.
(문제가 있는 경우 변경사항을 롤백하여 기존 설정을 유지한다) -
문제가 없는 경우 변경된 설정을 적용하여 새로운 워커 프로세스를 생성하고,
기존 워커 프로세스들에 shut down 요청을 한다. -
이를 받은 기존 워커 프로세스는 새로운 connection을 받지 않고,
현재 처리 중인 요청을 완료한 후 종료한다.
결과적으로 reload를 사용하면 배포 중에도 모든 요청을 처리할 수 있다고 말하고 있다. 이를 단디 프로젝트에 적용해보았다.
기존에 Docker를 사용하여 NGINX를 띄웠는데 이 상태에서는 NGINX가 실행되는 중에 설정 파일을 수정할 수 없었다.
volume으로 설정 파일과 연동한 컨테이너 외부 파일을 수정했을 때 컨테이너 내부의 설정파일에 반영되지 않았고, 컨테이너 내부의 설정 파일을 sed로 직접 수정하려고 했을 때 resource busy라는 에러가 발생하며 수정할 수 없었다.
이러한 이유로 host PC에 직접 NGINX 1.18.0 버전을 설치하여 사용했다. 그래서 배포 스크립트에서 트래픽을 전환하는 부분은 아래와 같이 수정하였다.
NGINX_CONFIG="config_path"
STOP_WEB_SERVER_IP=$(docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' frontend-$NOW_COLOR)
NEW_WEB_SERVER_IP=$(docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' frontend-$TARGET_COLOR)
sed -i "s/$WEB_SERVER_STOP_PORT/$WEB_SERVER_TARGET_PORT/g" $NGINX_CONFIG
sed -i "s/frontend-$NOW_COLOR/frontend-$TARGET_COLOR/g" $NGINX_CONFIG
sed -i "s/$STOP_WEB_SERVER_IP/$NEW_WEB_SERVER_IP/g" $NGINX_CONFIG
sudo nginx -s reload설정 파일에서 트래픽 전환을 위해 바뀌는 버전 컨테이너의 IP 주소, PORT, 그리고 upstream 변수명을 수정해주었다. 그리고 나서 NGINX를 reload한다.
테스트
그러면 정말 다운타임 없이 배포되는지 테스트를 해보겠다.
JMeter를 사용했고 100명의 사용자가 20초 동안 2번씩 요청을 보내도록 설정했다.
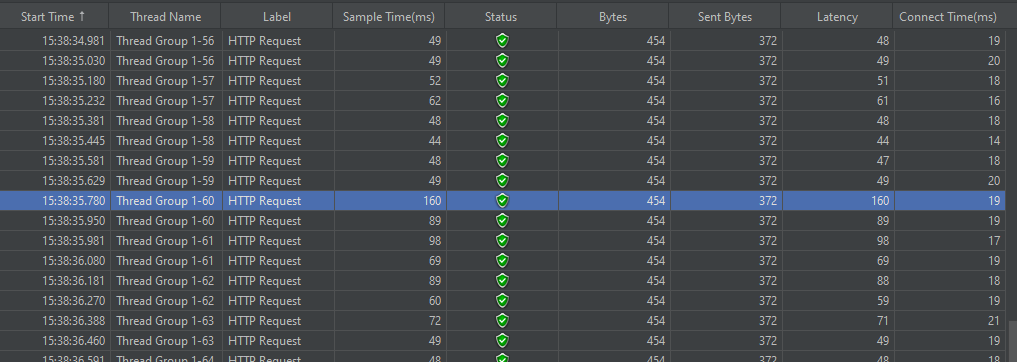
결과를 보면 대략 0.1초 간격으로 보내지는 요청이 모두 잘 처리된 것을 볼 수 있다.
.
.
.
.
하지만..................!!!!!!
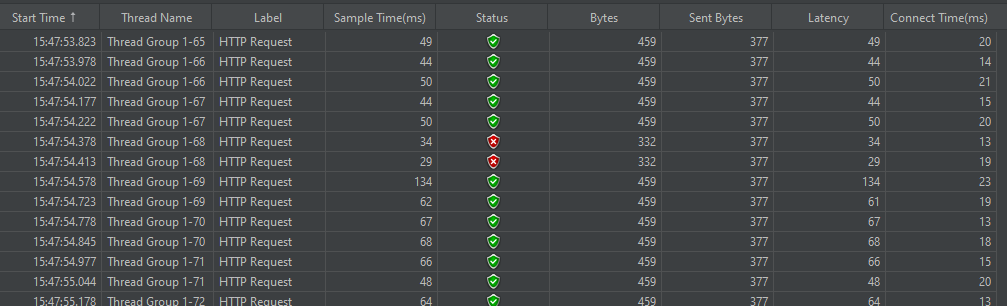
같은 시나리오에서 HTTP header의 Connection: keep-alive 옵션을 활성화하면 위와 같이 요청 2개가 처리되지 못한 것을 볼 수 있다.
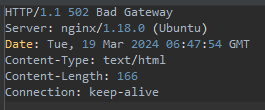
Response를 확인해보니 502 Bad Gateway 에러가 발생했다.
반쪽짜리 Zero Downtime...?
NGINX는 'zero-downtime', 'graceful reload'를 지원한다고 말하고 있다.
하지만 위에서 보았듯이 Connection을 keep-alive로 하면 다운타임이 발생한다.
이 블로그를 참고했다.
TCP 연결을 종료할 때 일어나는 4-Way handshake는 Half-Close 기법을 사용하기 때문에 TCP 연결을 바로 종료하지 않고 추가적인 데이터 전송을 할 수 있다. 문제는 여기서는 TCP연결이 완전히 종료되지 않았는데 워커 프로세스가 종료되어버렸고, 클라이언트는 끊긴 TCP 커넥션을 통해 추가로 요청을 보내려고 한다는 것이다.
결과적으로 Connection: keep-alive이면서 NGINX의 keepalive_timeout시간 내에 클라이언트가 요청을 보내는 경우 끊긴 TCP 커넥션을 통해 요청을 보내려고 하기 때문에 에러가 발생하게 된다.
RFC7230 문서를 보면 이러한 상황이 발생했을 때 브라우저는 다음과 같이 처리한다.

TCP 커넥션 종료 감지 ➡️ 새로운 커넥션 시도 ➡️ 요청 재전송
이렇게 해도 해결되지 않는 경우 "네트워크 에러" 또는 "서버에 연결할 수 없음" 등의 메시지로 나타낸다.
결론적으로 배포 시 발생한 에러를 브라우저가 자동으로 처리하여 새로운 TCP 커넥션을 통해 요청을 보낼 수 있다는 것이다. 즉, 사용자는 배포 시에도 서비스를 끊김 없이 사용할 수 있다!
마무리
위와 같이 NGINX의 reload 시그널을 사용하여 배포 시 발생하는 다운타임을 줄여보았고, 특정 상황에서 발생하는 0.3초의 다운타임 또한 브라우저에서 자동으로 에러 처리를 하여 사용자는 서비스를 끊김 없이 사용할 수 있음을 알게 되었다.
서비스 다운타임을 5분에서 1초로, 그리고 1초에서 0초로 없애는 과정에서 TCP connection과 관련하여 Half-Close 기법, 브라우저의 동작 등 많은 것을 깊게 배울 수 있었다!!😊
참고 자료
https://nginx.org/en/docs/beginners_guide.html
https://soonoo.me/docs/posts/2020/03/26/nginx-reload.html
https://devthomas.tistory.com/50
https://datatracker.ietf.org/doc/html/rfc7230#section-6.3.1
