Intro
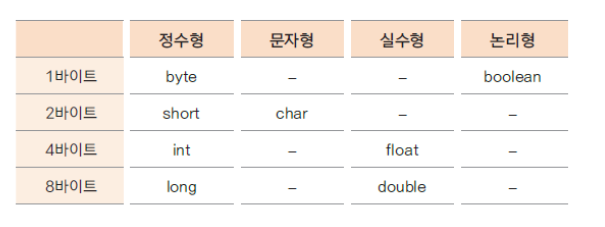
Java의 기본 자료형(Primitive Data Type)에는 정수형, 실수형, 문자형, 논리형이 있다. 기본 자료형의 변수는 메모리에 실제 값을 가지게 된다.
참조 자료형(Reference Data Type)은 기본 자료형을 제외한 모든 자료형이며, 참조 자료형의 변수는 메모리에 실제 값이 아닌 실제 데이터가 저장된 메모리의 주소값을 가지고 있다.
참조 자료형은 직접 정의할 수 있다. heap memory에 저장되며 대문자로 시작한다. ex) String, 클래스...
이번 글에서는 기본 자료형에 대해 먼저 알아보겠다.
정수형
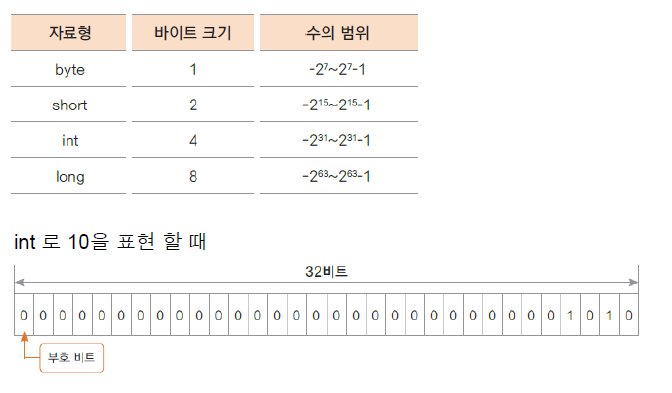
byte
- 1byte 단위의 자료형
- 동영상, 음악파일, 실행 파일의 자료를 처리할 때 사용
short
- 2byte 단위의 자료형
- C/C++ 언어와 호환 시 사용
int
- 4byte 단위의 자료형
- 자바에서 정수에 대한 기본 자료형, 모든 숫자(리터럴)은 int로 저장됨
- 32bit를 초과하는 숫자는 long 자료형으로 처리
long
- 8byte 단위의 자료형
- 숫자 뒤에 알파벳 L을 써서 long형임을 표시
ex) int num = 12345678900; // 오류
long lnum = 12345678900; //오류
long lnumber = 12345678900L; // ok→ 대입하려는 숫자가 int 범위에 들어오는 숫자이면 long 자료형에 대입 시 자동형변환이 되지만,
그 범위를 벗어난다면 뒤에 L을 붙여줘야함.
정수 오버플로우 & 언더플로우
정수형 데이터의 타입을 사용할 때에는 반드시 자신이 사용하고자 하는 데이터의 최소/최대 크기를 고려해야 한다. 만약 해당 타입이 표현할 수 있는 범위를 벗어난 데이터를 저장하게 되면, 오버플로우(overflow)가 발생해 전혀 다른 값이 저장될 수 있기 때문이다.
- 오버플로우 : 해당 타입이 표현할 수 있는 '최대 표현 범위'보다 큰 수를 저장할 때 발생하는 현상
- 언더플로우 : 해당 타입이 표현할 수 있는 '최소 표현 범위'보다 작은 수를 저장할 때 발생하는 현상
byte max = 127;
byte min = -128;
System.out.println(max + 1000); // ERROR
System.out.println(min - 1000); // ERRORunderscore 표기법
언더스코어 표기법은 jdk 7 부터 지원하는 문법으로, 우리가 큰 숫자를 콤마 1000,000,000 로 표현하듯이 프로그래밍에선 콤마 대신 밑줄 문자로 표현해도 실제로는 숫자로 읽혀지게 된다.
int cost = 1000_000_000; // 10000000002진수, 8진수, 16진수
int type을 사용하여 2진수, 8진수, 16진수를 아래와 같이 표현할 수 있다.
8진수, 16진수를 사용하면 각각 3bit, 4bit를 한 번에 표현 가능하다.
// 0(숫자 '0')으로 시작하면 8진수
int octal = 023;
// 0x(숫자 '0' + 알파벳 'x')로 시작하면 16진수
int hex = 0xC;
// 0b(숫자 '0' + 알파벳 'b')로 시작하면 2진수
int binary 0b101실수형
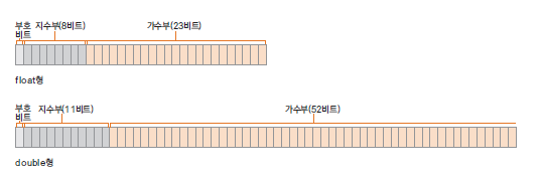
실수를 표현하기 위한 자료형은 대표적으로 float, double 이 있다.
과거에는 실수를 표현할 때 float형을 많이 사용했지만, 하드웨어의 발달로 인한 메모리 공간의 증가로 현재에는 double형을 가장 많이 사용한다.
float
4byte 단위의 자료형
실수는 기본적으로 double형이기 때문에 float형의 실수 뒤에는 f or F를 붙임
double
8byte 단위의 자료형
자바에서 실수에 대한 기본자료형은 double
부동 소수점 방식
컴퓨터의 메모리는 한정적이기 때문에 정수에도 범위가 있듯이 소수의 소수점을 나타내는 범위에도 제한이 있다. 그러나 부동 소수점 방식을 사용하게 되면 매우 큰 범위의 실수까지도 표현할 수 있게 된다.

부동 소수점 방식의 오류
지수와 가수로 나타내는 부동 소수점 방식에서 지수부가 0을 표현할 수 없기 때문에 약간의 오차가 발생하게 된다. 이것은 Java뿐만이 아닌 모든 프로그래밍 언어의 문제이다.
double value1 = 12.23;
double value2 = 34.45;
// 기대값 : 46.68
System.out.println(value1 + value2); // 46.68000000000001이러한 연산 문제를 해결하기 위해 Java에서는 실수를 int나 long 타입으로 치환하여 사용하거나, BigDecimal 클래스를 사용할 수 있다.
// long type으로 변환하여 계산
long a2 = (long)(a * 10);
long b2 = (long)(b * 10);
double result = (a2 - b2) / 10.0;
System.out.println(result); // 0.1
// BigDecimal 자료형을 사용
BigDecimal bigNumber1 = new BigDecimal("1000.0");
BigDecimal bigNumber2 = new BigDecimal("999.9");
BigDecimal result2 = bigNumber1.subtract(bigNumber2); // bigNumber1 - bigNumber2
System.out.println(result2); // 0.1실수 오버플로우 & 언더플로우
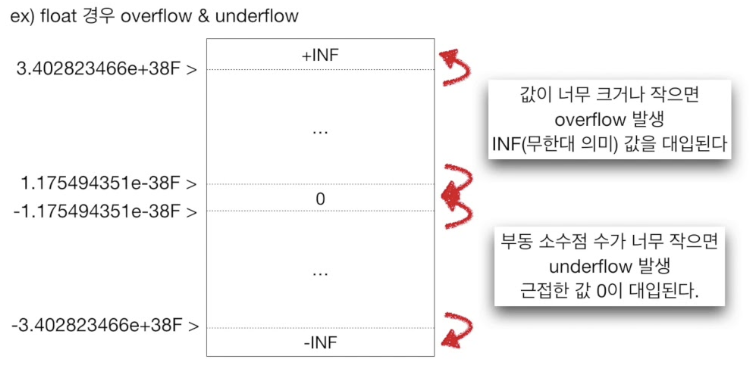
- 오버플로우: 무한대 (infinity)
- 언더플로우: 실수형으로 표현할 수 없는 아주 작은 값, 즉 양의 최솟값보다 작은 값이 되는 경우를 말하여 값은 0이 된다.
논리형
boolean
논리형에는 true, false의 값을 가지는 boolean type이 있는데 1byte의 크기를 가진다.
값이 존재하는지, 배열이 비었는지, 결과가 참인지 거짓인지 등을 표현한다.
문자형
char
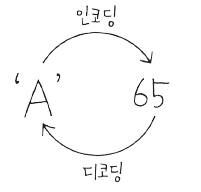
문자는 컴퓨터 내부에서 표현하기 위해 특정 정수값으로 정의된다. 각 문자를 얼마로 표현할 것인지 정의한 문자세트가 있는데 자바에서는 세계표준인 유니코드를 사용한다. (아스키코드는 유니코드의 하위 집합)
ex) ASKII(1byte), euc-kr(우리나라것), UNICODE(utf-8,utf-16)
- 2byte 크기를 가지며, 할당 시 작은 따옴표로 감싸주어야 한다.
- char type 변수는 내부적으로 숫자로 표현되므로 숫자를 할당해도 문자로 출력이 된다.
char ch = 65; System.out.println(ch); // A
문자열은 어떻게 표현할까?
문자열은 char의 배열과 같은데 이를 표현하기 위해서는 String class를 사용하게 된다. 이때 char와 다르게 String은 쌍따옴표를 사용한다! 추가로 String은 불변 객체!!
문자열을 선언하고 값을 할당할 때 두 가지 방법이 있다.
String a = "Happy Java"; // 리터럴 방식
String b = new String("Happy Java"); // 생성자 방식두 가지 방식 중 리터럴 방식을 사용하는 것이 더 효율적이다!
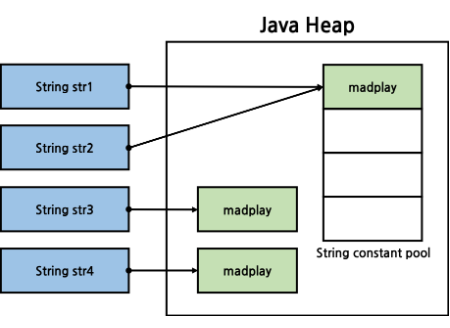
리터럴 방식을 사용하면 그 값이 String constant pool이라는 공간에 저장된다. 다음에 또 같은 값의 문자열을 할당할 경우 String constant pool에 추가로 저장하는 것이 아니라 같은 주소값을 가리키도록 한다. 하지만 생성자 방식을 사용하면 heap 영역에 항상 객체가 생성된다.
✅ 따라서 리터럴 방식이 메모리 사용을 최적화하고 성능을 향상시킬 수 있다!
참고 자료
