역정규화란?
역정규화(Denormalization)는 정규화된 데이터베이스 구조에서 일부러 중복을 허용하거나 테이블을 병합하여 조회 성능을 높이는 작업이다. 이는 데이터 무결성보다 빠른 읽기 속도나 간결한 쿼리 작성이 우선일 때 선택하는 전략으로 성능 개선을 위한 실질적인 트레이드오프다.
왜 정규화를 되돌릴까?
정규화(Normalization)는 데이터베이스 설계의 기본으로 중복을 제거하고 무결성을 보장하며 데이터 변경 시 일관성을 유지하는 데 중점을 둔다. 하지만 실무에서는 지나친 정규화로 인해 조인 연산이 과도하게 발생해 성능이 저하되거나 간단한 조회조차 복잡한 쿼리를 필요로 하는 상황이 발생하기도 한다. 특히 실시간 응답이 중요한 API 환경에서는 조인으로 인한 병목 현상이 사용자 경험에 직접적인 영향을 줄 수 있다. 이러한 이유로 성능이 절대적으로 필요한 상황에서는 일부 정규화를 되돌리는 역정규화가 필요한 선택지가 될 수 있다.
그렇다면 언제 역정규화를 고려해야 할까?
역정규화는 모든 상황에서 사용하는 만능 해결책이 아니다. 하지만 다음과 같은 상황이라면 충분히 고려해볼 수 있다.
첫째, 복잡한 조인으로 인해 조회 성능이 느려지는 경우다. 여러 테이블을 반복적으로 조인해야 하는 구조에서는 CPU와 IO 사용량이 늘어나고 결과적으로 응답 속도가 떨어진다. 특히 테이블 간 참조가 깊고 조회 대상 데이터가 많다면 역정규화를 통해 일부 정보를 직접 포함시킴으로써 조인을 줄일 수 있다.
둘째, 데이터의 읽기 비중이 높고 쓰기(갱신) 비중은 낮은 환경에서는 역정규화가 매우 효과적이다. 예를 들어 분석 시스템(OLAP)이나 대시보드, 검색 서비스처럼 조회는 빈번하지만 데이터 변경은 드문 경우에는 중복 데이터를 감수하고라도 읽기 성능을 극대화하는 것이 효율적이다.
셋째, 정규화된 구조가 너무 복잡하여 유지보수가 어려운 경우도 역정규화를 고려할 수 있다. 지나치게 세분화된 테이블 구조는 쿼리 작성뿐 아니라 도메인 이해도 어렵게 만들기 때문에 실무에서 유지보수성과 직관성을 확보하기 위해 단순화된 구조로 일부 데이터를 병합하는 것이 도움이 된다.
마지막으로, 실시간 응답 속도가 중요한 API를 운영하고 있을 때다. 특히 사용자에게 즉각적인 반응이 요구되는 모바일 앱이나 프론트엔드 페이지에서 여러 테이블을 조인하는 복잡한 조회는 병목을 발생시킬 수 있다. 이럴 때는 응답 속도를 높이기 위해 조인을 제거하고 필요한 데이터를 한 테이블에 포함시키는 전략이 성능 개선에 효과적이다.
예시로 이해해보자
정규화된 구조
[User]
- user_id (PK)
- name
- department_id (FK)
[Department]
- department_id (PK)
- name
특정 유저의 이름과 부서명을 조회하려면 조인이 필요하다.
SELECT u.name, d.name
FROM user u
JOIN department d ON u.department_id = d.id하지만 유저 수가 많고 실시간 성능이 중요하다면 JOIN이 병목이 될 수 있다.
역정규화 적용된 구조
[User]
- id (PK)
- name
- department_id
- department_name (중복 허용)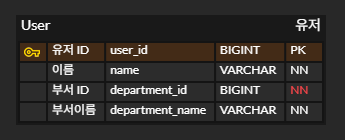
이렇게 하면 JOIN 없이도 부서 이름을 바로 조회할 수 있다.
SELECT name, department_name FROM user이로 인해 읽기 성능이 비약적으로 향상된다. 단, 부서명이 바뀔 경우 관련 유저 레코드도 모두 업데이트해야하는 단점이 있다.
그렇다면 역정규화는 언제부터 고려해야 할까?
역정규화는 보통 초기 설계 단계부터 바로 적용하기보다는 우선 정규화된 구조로 데이터베이스를 설계한 후 실제 운영 중에 성능 병목이 확인된 구간에 한해 선택적으로 도입하는 것이 일반적인 방식이다. 초반부터 중복 데이터를 허용하게 되면 유지보수 부담이 크고 변경 시 오류가 발생할 가능성이 높기 때문이다.
예를 들어 개발 중에는 크게 문제가 없었지만 유저 수가 많아지면서 조회 쿼리에 JOIN이 많아지고 응답 속도가 느려지는 상황이 발생했을 때 해당 병목 지점만 역정규화로 전환하는 방식이 안정적이다. 이러한 접근은 역정규화의 목적이 '처음부터' 설계를 단순화하는 것이 아니라 "실제 데이터 사용 패턴에 맞춰 성능을 최적화"하는 데 있다는 점을 강조한다.
어떻게 적용해야 할까?
역정규화를 적용할 때 가장 중요한 것은 정합성을 어떻게 유지할 것인가다. 중복된 데이터를 수동으로 관리하기보다는 자동화된 방식으로 동기화를 유지할 수 있는 시스템을 함께 설계해야 한다. 가장 일반적인 방법은 데이터베이스 트리거(Trigger)를 활용하는 것이다.
예를 들어 부서명이 바뀌었을 때 관련 유저 테이블의 department_name 컬럼도 자동으로 업데이트되도록 다음과 같은 트리거를 설정할 수 있다.
CREATE TRIGGER update_department_name
AFTER UPDATE ON department
FOR EACH ROW
BEGIN
UPDATE user
SET department_name = NEW.name
WHERE department_id = NEW.department_id;
END;이와 같은 방식은 부서 테이블의 데이터가 수정되었을 때 유저 테이블에 있는 중복 데이터도 실시간으로 반영되므로 데이터 일관성을 유지하면서도 빠른 조회 성능을 유지할 수 있는 장점이 있다.
트리거 외에도 애플리케이션 레벨에서는 Kafka나 이벤트 기반 메시징 시스템을 사용해 "변경 이벤트 발생 -> 연관 데이터 갱신"의 구조를 구성할 수도 있다. 이 방식은 특히 마이크로서비스 환경에서 선호되며 데이터 소스 간의 느슨한 결합과 높은 확장성을 동시에 달성할 수 있다.
📝 배운점
역정규화는 단순히 성능을 높이기 위한 마법 같은 기법이 아니라 반드시 사전 검토와 전략적 판단이 수반되어야 하는 기술이라는 점을 다시금 느꼈다. 정규화는 데이터 일관성을 위한 기본이며 역정규화는 이 정합성을 일부 희생하고 성능이라는 목표를 달성하기 위해 선택하는 구조다.
특히 중요한 것은 역정규화를 적용하기 전 성능 병목의 원인이 조인 때문임이 명확히 분석되어야 하며 데이터의 변경 주기가 짧지 않고 중복 데이터의 동기화를 유지할 수 있는 시스템이 마련되어 있어야 한다는 점이다. 이러한 조건이 충족되지 않는 상태에서 무작정 역정규화를 도입하면 오히려 시스템의 신뢰성을 해칠 수 있다. 트리거나 이벤트 기반 처리처럼 동기화를 자동화하는 방법을 함께 고려한다면 역정규화의 단점을 완화하면서 성능 이점을 얻을 수 있다. 결국 역정규화는 “정규화를 이해한 사람만이 올바르게 사용할 수 있는 기술”이라는 말이 매우 인상 깊게 다가온다.
참고
