빅데이터 이야기...
'분산'이라는 사상이 아주 중요하다.
저장소를 분산해보자는 개념에서 HDFS가 등장했고, 처리를 분산해보자는 생각에서 Map Reduce가 등장했고, 이외의 것들도 분산처리를 해보자는 개념에서 YARN이 등장했다.
빅데이터 이야기에서는 '분산'이 아주 중요한 키워드라고 생각된다.
Map Reduce
Map reduce는 데이터를 처리하기 위한 시스템이고 Map 단계와 Reduce단계 두가지로 구분이 된다.
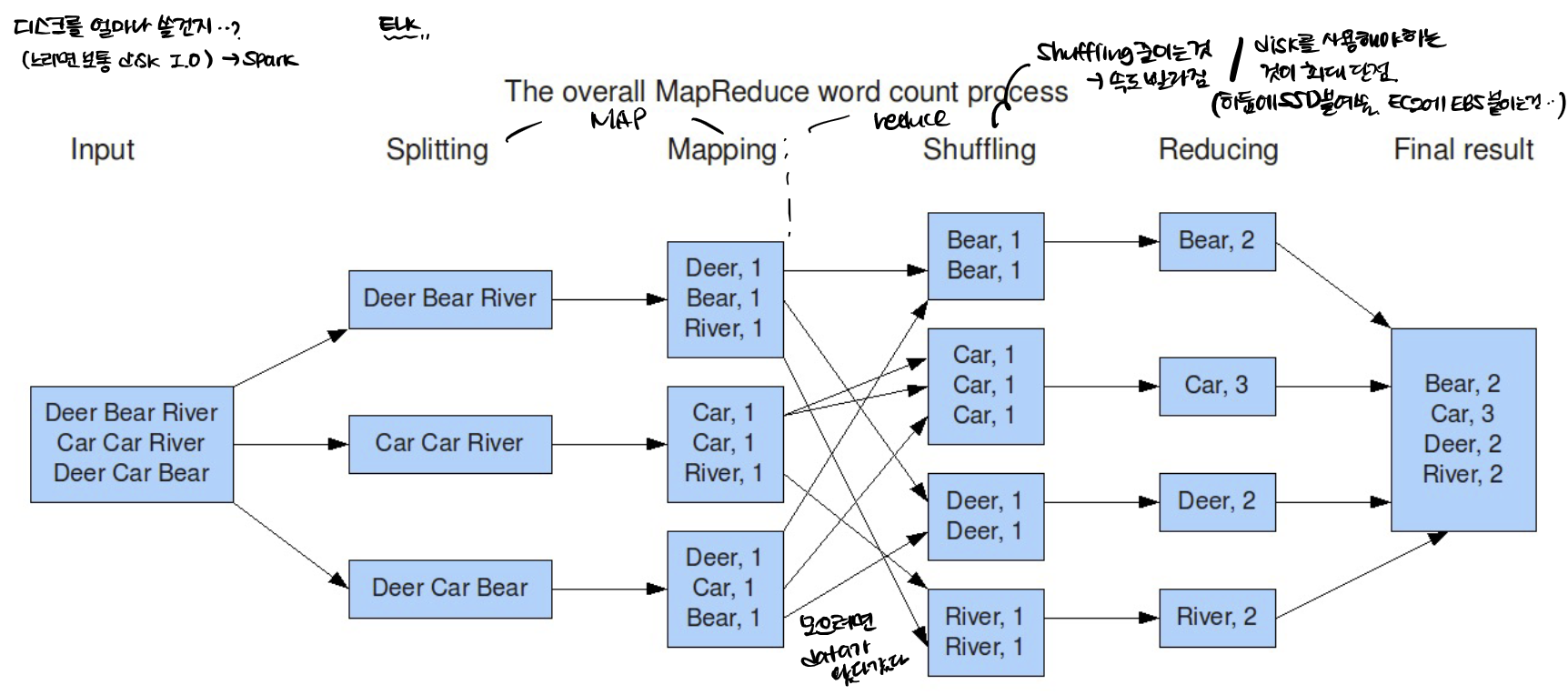
Map reduce 작업이 시작되면 HDFS로 부터 파일을 가져오고, Map reduce 작업이 끝나면 HDFS에 파일이 써진다.
YARN
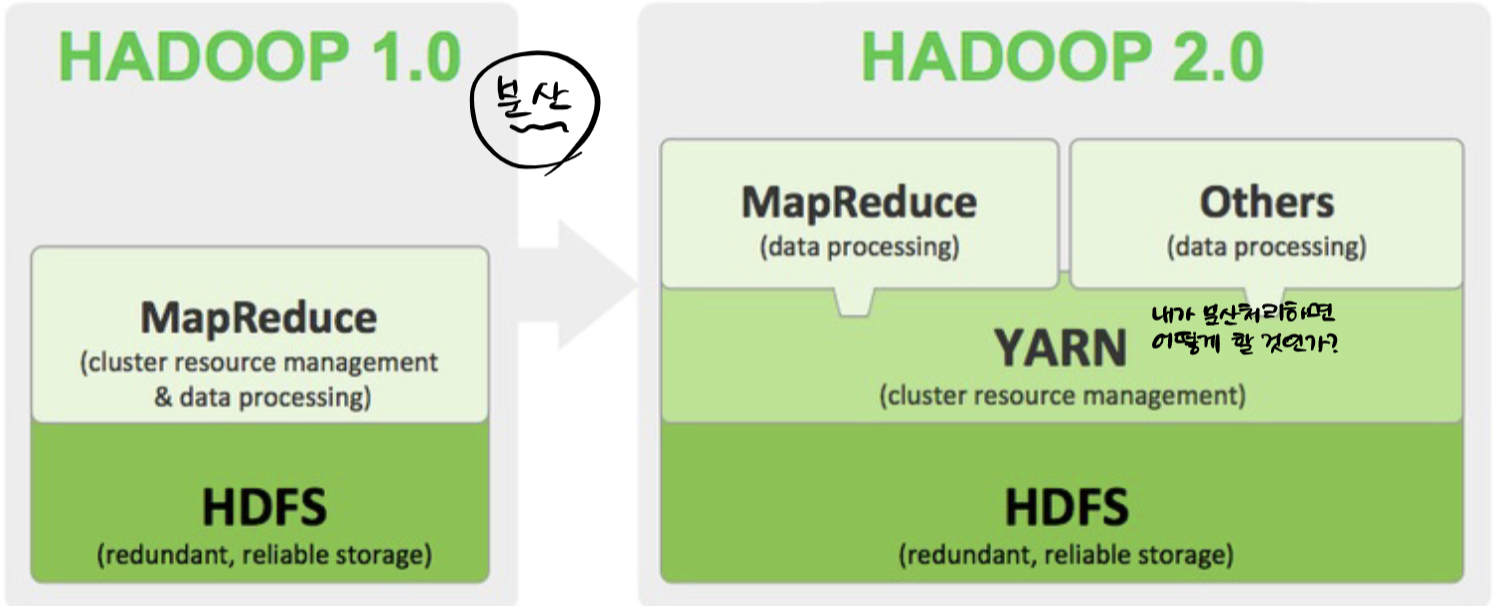
hadoop 1.0에서 2.0으로 넘어가면서 '분산'의 컨셉이 더 강해졌다. 기존의 1.0에서 Map Reduce 과정에서는 resource managing까지 이루어졌지만 이를 더 분산하고자 해서 YARN이 등장했다.
분산을 조금 더 쉽게 이해하고자 하면 대장님이 일을 시킨다.. 라고 생각을 하면 된다.
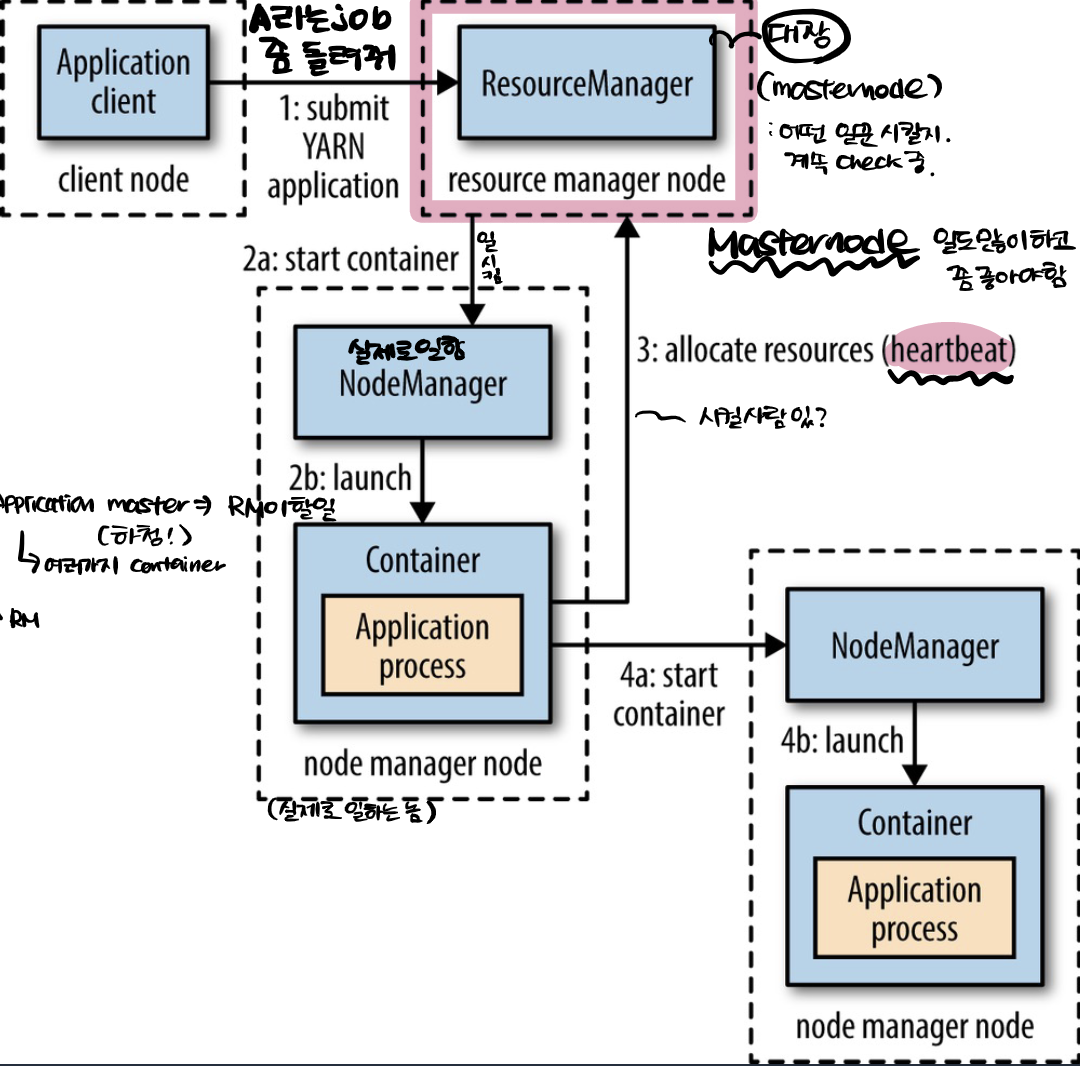
node들을 다음과 같이 나눌 수 있다
- Master node : Resource manager, Name node
- Worker node (Slave node) : core node, task node
고객이 A라는 job을 요청한다. 그러면 대장인 Resource manager는 하청을 한다. 바로 App Master를 띄워주는 것. 그러면 App master 역시 새로운 하청을 한다. 일할 놈들을 띄우는 것!
pop quiz ) Q. Resource Manager가 첫번째로 띄우는 container는 ?
A. App master
HDFS (Hadoop Distributied File System)
HDFS를 이해하기 전 block storage를 먼저 이해해보는 것이 좋은 것 같다. HDFS는 block file system이다.
block storage란?
-
데이터를 블록 단위로 나누어서 저장한다. 이런 방식은 내가 가진 데이터를 블록으로 쪼개고 일부는 Linux 환경에, 일부는 Windows 환경에 저장할 수 있다는 의미이다.
-
블록으로 쪼개서 저장한 데이터는 후에 데이터 블록을 재조합해서 사용자에게 제공된다.
-
file storage와 다르게 단일 데이터 경로에 의존하지 않아서 신속한 검색이 가능하고 파티션으로 분할할 수 있어서 서로 다른 운영체제를 이용할 수 있다는 장점이 있다.
-
자유로운 데이터 설정이 가능하고, 많은 데이터 transaction 수행시 유리하다.
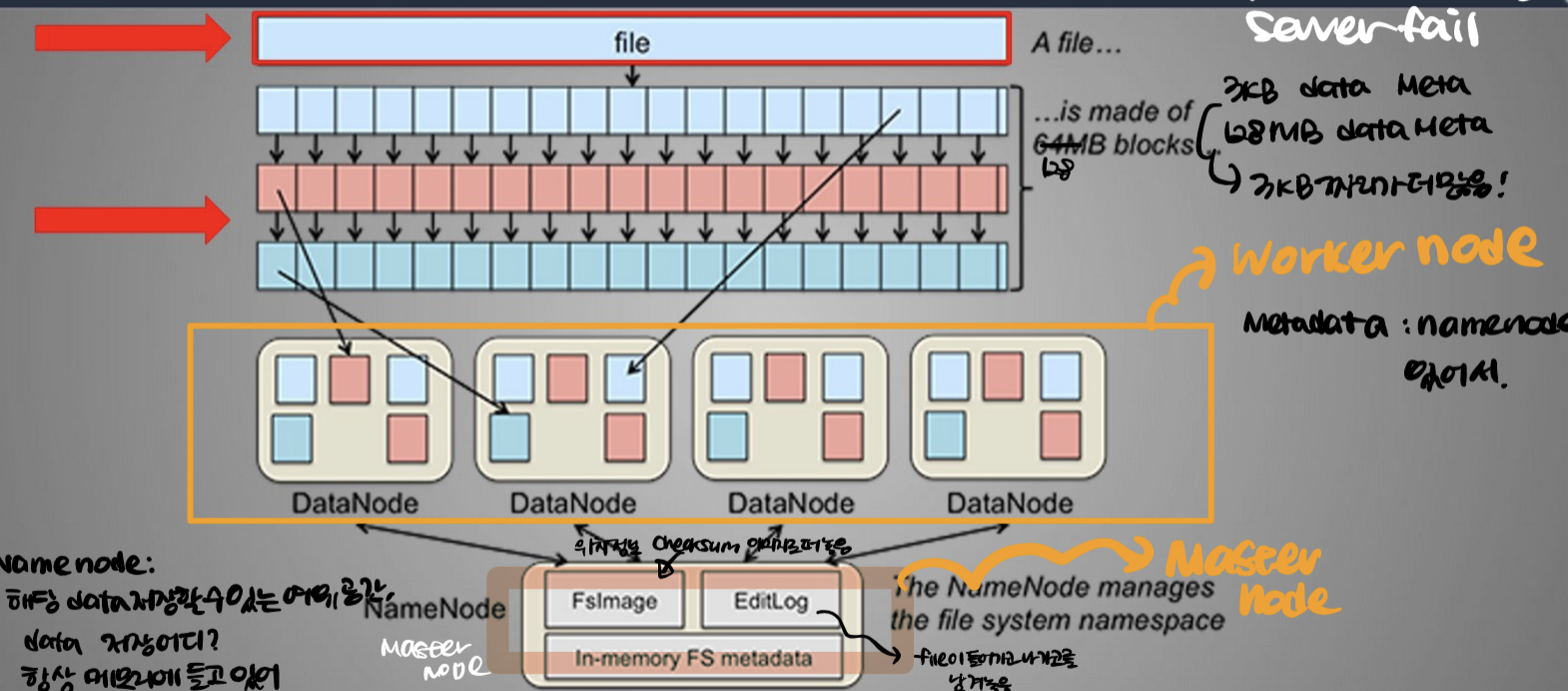
HDFS는 대용량 데이터 파일을 분산된 서버에 저장하고 이 데이터를 빠르게 처리하는 시스템이다.
블록 크기는 기존에는 64MB, 2.0버전에서는 128MB로 증가했다.
HDFS에서는 Locality를 고려할 수록 시간이 단축된다. 반면에 s3를 이용한다면 locality를 고려하지 않는 것이 된다.
