공부할 때 왜 그것을 배우는지 목적이 중요하다 생각한다. JPA를 왜 사용하는지도 마찬가지다.
<목적>
- SQL 중심적인 개발에서 객체 중심으로 개발
- 생산성
- 유지보수
- 패러다임의 불일치 해결
- 성능
- 데이터 접근 추상화와 벤더 독립성
- 표준
-
JPQL은 객체 지향 SQL 이다. 라고 생각하면 된다.
-
엔티티의 생명주기는 4가지로 분류할 수 있다.
- 비영속
-
**//객체를 생성한 상태(비영속)
Member member = new Member();
member.setId("member1");member.setUsername("회원1");**
-
- 영속
- //객체를 생성한 상태(비영속) Member member = new Member(); member.setId("member1"); member.setUsername(“회원1”); EntityManager em = emf.createEntityManager(); em.getTransaction().begin(); //객체를 저장한 상태(영속) **em.persist(member); → 이렇게 해서 바로 DB에 저장되는 것이 아닌 Commit하는 시점에 저장된다.**
- //객체를 생성한 상태(비영속) Member member = new Member(); member.setId("member1"); member.setUsername(“회원1”); EntityManager em = emf.createEntityManager(); em.getTransaction().begin(); //객체를 저장한 상태(영속) **em.persist(member); → 이렇게 해서 바로 DB에 저장되는 것이 아닌 Commit하는 시점에 저장된다.**
- 준영속
- //회원 엔티티를 영속성 컨텍스트에서 분리, 준영속 상태
em.detach(member);
- //회원 엔티티를 영속성 컨텍스트에서 분리, 준영속 상태
- 삭제
- //객체를 삭제한 상태(삭제) em.remove(member);
- //객체를 삭제한 상태(삭제) em.remove(member);
- 비영속
-
1차 캐시 이점
- 회원을 조회할 때 1차 캐시에서 찾고, 없으면 DB에서 조회한다음 조회한 값을 1차 캐시에 저장함 이후에 트랜잭션이 끝나기전에 조회가 일어날 경우 DB까지 가지 않고, 1차 캐시에서 그대로 조회해서온다.
- DB 트랜잭션 1개 안에서 일어나는 일이므로, 그렇게 큰 이점을 가져가진 않는다.
-
트랜잭션을 지원하는 쓰기 지연
- 이 부분은 내가 특히나 와닿았다. JdbcTemplates로 개발했을 때 SQL로 트랜잭션 쿼리를 작성해 쓰기 지연을 적용시켰지만, JPA는 flush 하기 전까지 쿼리문을 갖고 있다가 commit하는 순간 쿼리를 보낸다.(버퍼와 같은 방식으로 생각하면 된다.)
-
변경 감지
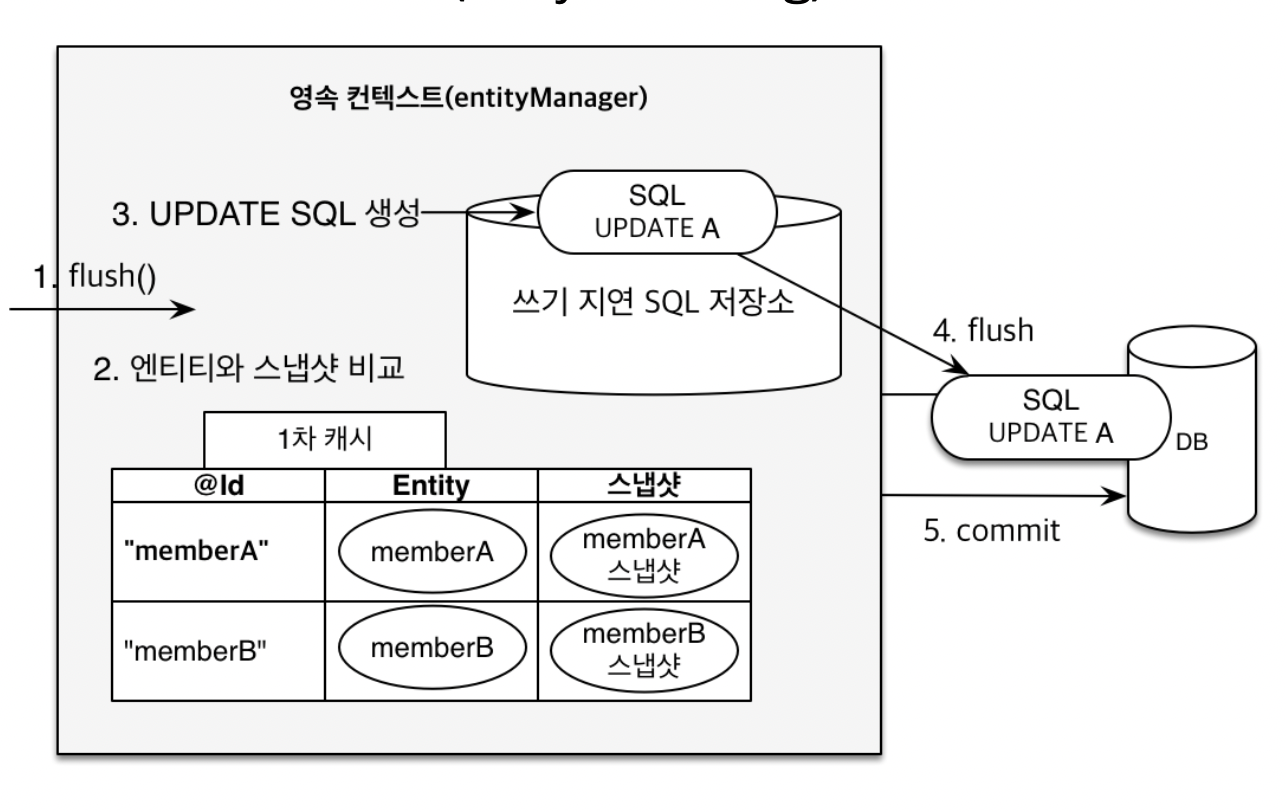
-
flush ⇒ 영속성 컨텍스트의 변경내용을 데이터베이스에 동기화
-
JPA를 사용해서 테이블과 매핑하려면 @Entity를 붙여야 된다.
-
데이터베이스 ddl.auto 설정에서
- 개발 초기 단계는 create 또는 update
- 테스트 서버는 update 또는 validate
- 스테이징과 운영 서버는 validate 또는 none
- 로컬에서는 create,update 자유롭게 쓰고, 여러 명이서 개발하는 테스트 서버에는 가급적이면 update도 쓰지 않는다.
-
JPA를 공부하던중 clob을 보고, 기존에 설계할 대 쓰던 blob과 차이점이 궁금하여 찾아봄
- BLOB
- 이진 대형 객체 (Binary), 이미지, 동영상, MP3 등...
- 비 전통적인 데이터 보관용
- CLOB
-
문자 대형 객체 (Character), Oracle Server는 CLOB과 VARCHAR2 사이에 암시적 변환을 수행
-
문자 기반 데이터 보관용
-
- ++ 매핑하는 필드 타입이 문자면 CLOB 매핑, 나머지는 BLOB 매핑
- CLOB: String, char[], java.sql.CLOB
- BLOB: byte[], java.sql. BLOB
- BLOB
-
DB에 반영안하고 계산 용도로만 쓰고 싶을 때
@Transient// DB에 반영안하고 계산 용도로만 쓰고 싶을 때
private inttemp;-
nullable = false →Not NULL
-
기본키를 Long타입으로 하는 이유 → 10억이 넘어갔을 때 Integer가 힘듬 그리고 10억 정도되는 규모에서 Integer → Long으로 변경하기도 힘들다.
-
Identity 전략은 em.persist()하는 순간 INSERT쿼리가 나간다.(쿼리를 날려야만 id값을 알 수 있음)
-
Sequence 전략은 next_val을 먼저 알고, 그다음에 INSERT 쿼리가 나간다.(쿼리 날리기전에 미리 id를 알 수 있음 = 버퍼를 사용해서 날린다 (Sequence전략은 성능 최적화를 위해 사용한다고 보면됨)
- allocationSize(시퀀스 한 번 호출에 증가하는 수(성능 최적화에 사용됨))
- 미리 기본 값인 50개를 불러놓고 -49,-48처럼 id를 넣을 때마다 마이너스를 해준다.
- 처음에 1번 사람을 넣으면 50개를 생성하고 2번, 3번 사람들 넣을 때부터는 Memory에서 가져오기 때문에 성능 최적화
- allocationSize(시퀀스 한 번 호출에 증가하는 수(성능 최적화에 사용됨))
-
(집중) 양방향 연관관계와 연관관계의 주인
- @OneToMany(mappedBy = "team") List members = new ArrayList(); →기존 member에서만 team을 참조할 순 있었지만, team에서 member를 참조하는 것을 해결
- 객체 연관관계⇒ 2개 (회원 → 팀(단방향), 팀 → 회원(단방향))
- 객체의 양방향 관계는 사실 양방향 관계가 아니라 서로 다른 단
뱡향 관계 2개다.
- 객체의 양방향 관계는 사실 양방향 관계가 아니라 서로 다른 단
- 테이블 연관관계 ⇒ 1개 외래키 값 하나로 서로 갈 수가 있다.
- 테이블은 외래 키 하나로 두 테이블의 연관관계를 관리
- **양방향 매핑 규칙**
- 객체의 두 관계중 하나를 연관관계의 주인으로 지정
- 연관관계의 주인만이 외래 키를 관리(등록,수정)
- 주인이 아닌쪽은 읽기만 가능
- 주인은 mappedBy 사용 X, 주인이 아닌쪽에 mappedBy속성으로 주인 지정
- 그래서 누가 주인??
- 외래 키(FK)가 있는 곳을 주인으로 정해라
- 순수한 객체 관계를 고려하면 항상 양쪽다 값을 입력해야 한다.
-
team에 member도 추가하고, member에 team도 넣어줘야함
team.getMembers().add(member); member.setTeam(team); em.persist(member); ----- 위 코드를 Member 엔티티에 setTeam할 때 들어가게 한다면? public void setTeam(Team team) { this.team = team; team.getMembers().add(this); } 이렇게 만들어주면 //team.getMembers().add(member); 를 작성할 필요없다. 이것을 '연관관계 편의 메소드' 라고 한다 사실setter방식을 권장하지 않기 때문에 setTeam -> chageTeam으로 변경해서 사용
-
- Controller에서는 절대 Entity를 반환하지 않는다.(Entity는 DTO로 변환해서 반환해라)
- 무한 루프 조심!!
- ex) toString(), lombok, JSON 생성 라이브러리
- @OneToMany(mappedBy = "team") List members = new ArrayList(); →기존 member에서만 team을 참조할 순 있었지만, team에서 member를 참조하는 것을 해결
-
JPA설계 할 때, 1차적으로 단방향으로 설계가 끝나야한다.(양방향없이)
-
Member 엔티티에 orders라는 List라는게 있는 것이 그렇게 좋지않음
- 어떤 회원이 주문한 목록을 보고 싶으면 주문 테이블에서 봐야하는데 이게 회원 테이블에 있다고 생각하면 될 것 같다.
-
mappedBy는 연결하려는 변수명에 name=””을 지정해준다고 생각하면 편한다.
-
단방향 관계만으로도 어플리케이션 가능하지만, JPQL하다보면 양방향 관계가 필요한 경우가 생긴다.
-
다대일은 (Member : Team) 를 생각 (Member가 주인인 case)
-
일대다는(Team: Membrer) , Team이 주인
- 비효율적, 거의 안씀, 그냥 다대일로 만든 다음 → 양방향 관계로 만들어주는게 더 낫다.
-
일대일 관계는 주 테이블 or 대상 테이블 어디던 외래키 가져도 상관없다. 단, 외래 키에 데이터베이스 유니크 제약조건 추가
- 주 테이블에 외래키를 설정할경우
- 객체지향 개발자 선호 , JPA 매핑 편리
장점: 주 테이블만 조회해도 대상 테이블에 데이터가 있는지 확인 가능
단점: 값이 없으면 외래 키에 null 허용
- 객체지향 개발자 선호 , JPA 매핑 편리
- 대상 테이블에 외래키를 설정할 경우
- 전통적인 데이터베이스 개발자 선호
장점: 주 테이블과 대상 테이블을 일대일에서 일대다 관계로 변경할 때 테이블 구조 유지
단점: 프록시 기능의 한계로 지연 로딩으로 설정해도 항상 즉시 로딩됨
- 전통적인 데이터베이스 개발자 선호
- 주 테이블에 외래키를 설정할경우
-
다대다 관계 → 일대다, 다대일로 풀어서 써라 객체는 다대다 (List List)로 가능하다.
-
논리모델을 물리모델로 바꾸는 방식
-
조인 전략(객체랑 잘맞고, 정규화 되고, 정석방식이라고 알아두면 된다.)
→ @DiscriminatorColumn ,@DiscriminatorValue공부하기
-
단일 테이블 전략( 테이블 한 개에 다 때려박음)
- 쿼리 1번에 들어가고, 성능으로 따지면 젤 괜춘
-
구현 클래스마다 테이블 전략(각각 다 갖는 방식)
- 아이템 아이디어만 아는 상태에서 조회할 때 앨범,영화,책 전부다 뒤져야된다.(UNION SQL 필요)
-
-
@MappedSuperclass
- 상속관계 매핑x(ex 부모객체를 쓴다던지 ㄴㄴ)
- 추상클래스로 만들어라(직접 생성해서 사용할 일이 없다.)
- 상속받는 자식클래스에 매핑 정보만 제공한다
- createAt(등록일),updateAt(수정일)이런거 사용할 때 유용할 듯?, or BaseResponse사용할 때
-
프록시
- 가정: 어떨땐 멤버이름과 어느팀소속인지를 출력해야하고, 어떤 경우는 멤버이름만 출력해야할 때,
전자가 자주 일어나지 않는데 메소드 구현한거면 비효율적 - 프록시 객체가 실제 엔티티에 “접근"한다 라고 이해하면 쉬울듯
- 원본 엔티티를 상속받는 것이므로, 프록시 객체들은 ==비교(x) instance of를 사용
- 영속성 컨텍스트에 em.find()로 이미 저장되어 있는 상태에서, em.getReference()를 호출하면 “실제 엔티티를 반환"한다.
- em.getReference()를 호출하고, em.find()를 호출하면 em.find()는 프록시를 호출한다. 그래서 JPA는 refMember==findMember를 보장해주기위해 true반환
- 준영속상태일 때, 프록시 객체를 초기화하면(프록시를 불러서 사용하면) 문제발생 →실무에서 매우 많이 문제나타나는 곳(주로 no session, org.hibernate.LazyInitializationException 예외를 터트림)
-
예시
Member.refMember = em.getReference(Member.class, member1.getId()); System.out.println("refMember = " + refMember.getClass()); //Proxy em.clear(); refMember.getUsername(); //여기서 에러발생
-
- 가정: 어떨땐 멤버이름과 어느팀소속인지를 출력해야하고, 어떤 경우는 멤버이름만 출력해야할 때,
-
실무에서 즉시 로딩은 사용하지 않는다.
- 예상치 못한 SQL이 발생하기 때문, JPQL에서 N+1 문제를 일으키기 때문
- @ManyToOne, @OneToOne은 기본이 즉시 로딩
- JPQL fetch 조인이나, 엔티티 그래프로 해결하라
-
CASCADE할 때, Parent의 영속성을 Child로 전이할 때는 가능하지만 Child가 다른 것과 연결이 되어있을 때(참조하는 것이 하나일 때)는 CASCADE하면 안된다.
-
**orphanRemoval = true 고아객체, CASCADE.Remove처럼 동작한다라고 이해하면 될 것같다. 사실 CASCADE.ALL만해도 적용됨**
-
Order → Delivery 영속성 전이 ALL 설정, Order → OrderItems 영속성 전이 ALL
- 주문할 때 배송정보도 같이 들어가게 하겠다는 뜻
- 주문할 때 주문 아이템들도 같이 들어가게
-
엔티티 타입
- 데이터가 변해도 식별자로 지속해서 추적 가능
-
기본 타입
- int, double같은 primary type은 절대 공유x
- 기본 타입은 항상 값을 복사함
- Integer같은 래퍼 클래스나 String 같은 특수한 클래스는 공유
가능한 객체이지만 변경X
-
임베디드 타입
- 잘 설계한 ORM 애플리케이션은 매핑한 테이블의 수보다 클래스의 수가 더 많다.
- 임베디드 타입 사용법
-
@Embeddable: 값 타입을 정의하는 곳에 표시
-
@Embedded: 값 타입을 사용하는 곳에 표시
-
객체와 테이블을 세밀하게 매핑하는 것이 가능
-
한 엔티티에서 값은 값 타입을 사용하려면?
- @AttributeOverrides를 사용해서 재정의****⇒느낀점: 구조를 복잡하게 테이블을 따로 만들 필요없이, 임베디드하게 설계 해주면 테이블 생성도 안해도되고, 깔끔하게 설계가 되는 것같다.
-
-
값 타입은 불변으로 만들어야 한다.
- 객체를 전달하면 주소를 전달하므로, 객체를 복사해서 만든 다음 할당해줘야 한다.
- 값 타입은 a.equals(b)를 사용해서 동등성 비교를 해야 한다.
-
값 타입 컬렉션 컬럼들이 전부 PK인 이유 → PK를 하나만 설정해주면 엔티티로 취급하므로
- 컬렉션들은 지연로딩이다.
- 실무에서는 상황에 따라 값 타입 컬렉션 대신에 일대다 관계를
고려 - 그래서 값타입 컬렉션을 언제 쓰냐? →추적할 필요없고, 업데이트 할 필요가 없을 때, 단순할 때 쓴다.
- 식별자가 필요하고, 지속해서 값을 추적,변경해야 한다면 그것은 값 타입이 아닌 엔티티
정리
-
임베디드 타입은 “엔티티의 값"일 뿐이다.
-
그런 값 타입은 불변 객체로 설계해야하고, equals()로 비교한다.
-
값 타입은 eqauls()랑 hashcode를 오버라이딩 해서 사용한다.
- Use getters during code generation을 체크해서 만들어라, getter를 통해 즉, 메소드를 통해 호출하도록 하는 것이 좋다.(이게 안전, 프록시가 엔티티에 접근할 수 있기 때문에)
-
JPQL - 테이블을 대상으로 x, 엔티티 객체를 대상으로 쿼리
-
SQL - 데이터베이스 테이블을 대상으로 쿼리
-
Mybatis, JdbcTemplates를 섞어서 쓸거면, SQL을 실행하기 직전에 영속성 컨텍스트
수동 플러시 해야한다. -
getResultList(); → 결과가 하나 이상일 때
-
getSingleResult(); → 결과가 정확히 하나
- 결과가 없으면 NoResultException
- 두 개 이상이면 NonUniqueResultException
-
Option + Commnad + V → 변수 생성
-
프로젝션 = SELECT할 것
- 프로젝션 대상: 엔티티, 임베디드 타입, 스칼라 타입(숫자,문자 등 기본 데이터 타입)
- 엔티티 프로젝션 → 엔티티 프로젝션은 em.clear()이후에 쿼리 해줘도, 영속성 컨텍스트에 반영된다.
- 여러값 조회 할 때
-
new 연산자 사용(Best), 패키지 명이 길면 다 적어야 되는 단점
List<MemberDTO> result = em.createQuery("select new jpql.MemberDTO(m.username, m.age) from Member.m", MemberDTO.class) .getResultList();
-
-
페이징
- setFirstResult → offset, 조회 시작 위치
- setMaxResults → Limit , 조회할 데이터 수
-
조인
- 내부 조인 → member가 소속된 팀이 없으면 member조회 안됨
- 외부 조인 → member가 소속된 팀이 없어도 member조회 된다.
- 세타 조인 → 카디전 프로덕트 (곱집합)
- 연관관계 없는 엔티티를 조인 하는 법
SELECT m, t FROM Member m LEFT JOIN Team t on m.username = t.name SQL:SELECT m., t. FROM Member m LEFT JOIN Team t ON m.username = t.name username과 team의 name 전혀 관계 없지만 조인 가능 →내 생각: left outer라서 가능한듯?**JPQL:**
-
서브 쿼리
- 서브쿼리 지원 함수
-
[NOT] EXISTS (subquery): 서브쿼리에 결과가 존재하면 참
-
{ALL | ANY | SOME} (subquery)
-
ALL:모두 만족하면 참
-
ANY, SOME: 같은 의미, 조건을 하나라도 만족하면 참
-
[NOT] IN (subquery): 서브쿼리의 결과 중 하나라도 같은 것이 있으면 참
-
예시
팀A 소속인 회원
select m from Member m
where exists (select t from m.team t where t.name = ‘팀A')
전체 상품 각각의 재고보다 주문량이 많은 주문들
select o from Order o
where o.orderAmount > ALL (select p.stockAmount from Product p)
어떤 팀이든 팀에 소속된 회원
select m from Member m
where m.team = ANY (select t from Team t)
-
- select절에서 서브 쿼리는 하이버네이트 에서 지원 , But from절 서브 쿼리는 지원안된다.
- 서브쿼리 지원 함수
-
JPQL 타입 표현
- ENUM은 패키지명 포함해서 적고, @Enumerated는 기본이 ordinal이라 숫자로 입력되기 때문에, EnumType=STRING을 꼭 선언해줘라
- 엔티티 타입 TYPE(m) = Member (상속 관계에서 사용)
-
조건식
- coalesce : 하나씩 조회해서 null이 아니면 반환
- coalesce(m.username, ‘이름 없는 회원') null일 경우 대체값 생성 가능
- NULLIF : 두 값이 같으면 null 반환, 다르면 첫번째 값 반환
- coalesce : 하나씩 조회해서 null이 아니면 반환
-
경로 표현식
-
상태 필드: 단순히 값을 저장하기 위한 필드(ex m.username)
-
연관 필드: 연관관계를 위한 필드
-
단일 값 연관 필드:(묵시적 내부 조인 발생, 탐색 O)
@ManyToOne, @OneToMany, 대상이 엔티티 (ex m.team)
-
컬렉션 값 연관 필드:(묵시적 내부 조인 발생, 탐색X)
@OneToMany, @ManyToMany, 대상이 컬렉션 (ex m.orders)
-
-
명시적 조인: join 키워드 직접 사용
-
묵시적 조인: 경로 표현식에 의해 묵시적으로 SQL 조인 발생(내부 조인만 가능)
→ 결론: 실무에서 묵시적 조인 쓰지마라, 명시적 조인을 써라
why? 코드보고 유지보수하기가 더 용이, 문제 터졌을 때 찾기 힘들다.
묵시적 조인은 조인이 일어나느 상황을 한눈에 파악하기 어려움
-
-
페치 조인(실무에서 매우 중요)
- 즉시 로딩을 한다.
- JPQL에서 성능 최적화를 위해 제공하는 기능
- 한방쿼리
- 3명의 팀 이름을 가져올 때 그냥 호출하면 3번 쿼리 날릴 것을, join fetch하면 쿼리 1번만 날린다.
- 페치 조인 vs 일반 조인
- JPQL은 결과를 반환할 때 연관관계 고려 x
- SELECT절에 지정한 엔티티만 조회할 뿐
- 페치 조인으로 N+1의 문제를 해결한다.
-
페치 조인의 한계
-
별칭을 주지 말아라(줄 순 있으나, 문제터질 가능성있음)
-
컬렉션을 페치 조인하면 페이징API(setFirstResult, setMaxResults)를 사용할 수 없다.
→ 결론: 모든 것을 페치 조인으로 해결할 수는 없다. 페치 조인은 객체 그래프를 유지할 때 효과적이다.
여러 테이블을 조인해서 엔티티가 가진 모양이 아니라 전혀 다른 결과를 내야한다면, 일반 조인을 사용해서 필요한 데이터들만 조회해서 DTO로 반환하는 것이 효과적이다.대부분의 성능 문제의 7~80%는 N+1 문제더라.
-
-
다형성 쿼리
- where treat(i as Book).author = ‘kim’ 이런식으로 캐스팅 변환 가능
-
벌크 연산
-
SQL의 UPDATE,DELETE지원
-
em.reateQuery("update Member m set m.age =20"); //이런식으로 -
벌크 연산은 영속성 컨텍스트를 무시하고, 데이터베이스에 직접 쿼리
- 연봉 5000→6000으로 인상됐을시, DB에는 6000인데 애플리케이션에는 5000으로 되어있을 수 있다. 이 때 방안은
- 벌크 연산을 먼저 실행 OR 벌크 연산 수행 후 영속성 컨텍스트 초기화
- 벌크 연산 query수행 이후, em.clear(); 시키면 DB에서 가져온다.
- 연봉 5000→6000으로 인상됐을시, DB에는 6000인데 애플리케이션에는 5000으로 되어있을 수 있다. 이 때 방안은
-
