대량데이터를 update하기 위한 튜닝 기법을 알아본다.
먼저, 샘플 데이터를 구해야 하는데 이번 예시에서는
아래 두 사이트중 owid의 covid-19 csv파일을 이용해 본다.
Github: owid/covid-19-data
위 사이트에서 받아온 csv 파일을 import 해보면 다수의 컬럼이 존재하는데,
이 중 iso_code, continent, location, date, total_cases만 이용해본다.
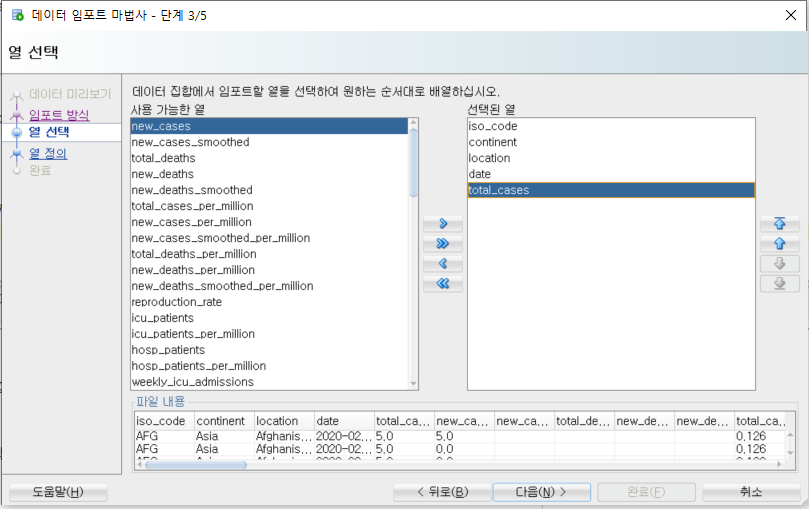
date 컬럼의 경우 컬럼 생성규칙에 맞춰 오른쪽과 같이 date_col로 변경한다.
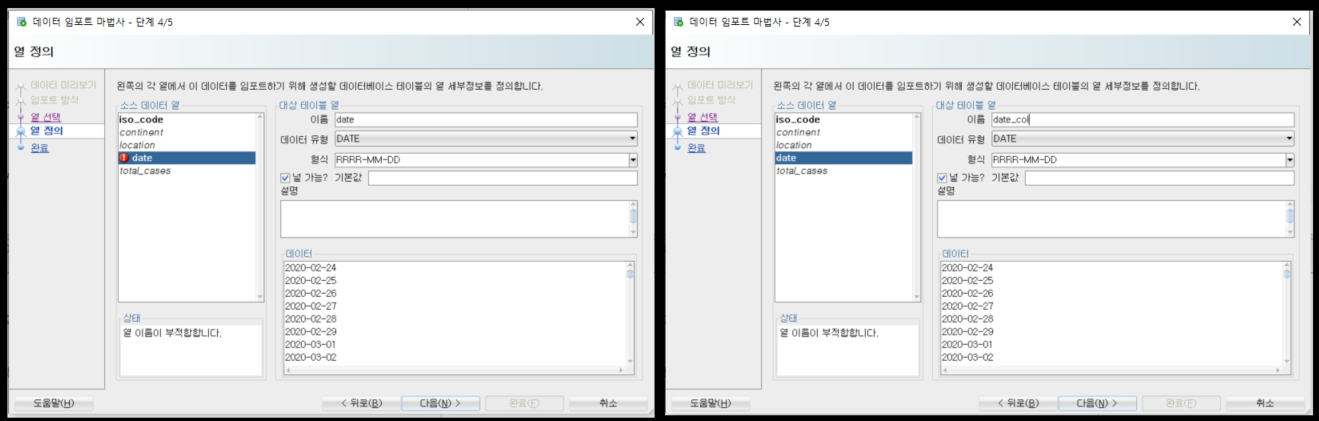
import가 문제 없이 되었다면 아래와 같이 약 16만건의 데이터가 있음을 확인 할 수 있다.
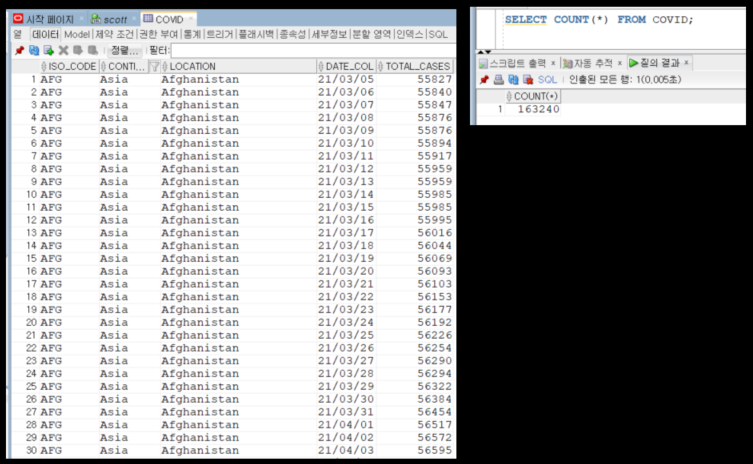
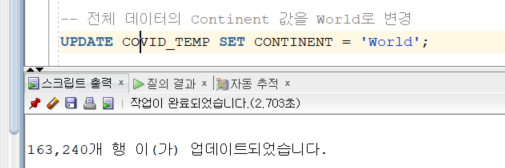
여기서, 모든 데이터의 Continent값을 World로 update 해보자.

일반적인 UPDATE문을 실행하는 경우,
실행계획에서 보여주듯이 2초 후반대를 기록했다. (생성된 인덱스 없음)
반면, 아래와 같이 세단계로 작업을 진행한다면 대량 데이터에 대해서
좀 더 우수한 성능을 보일 수 있다.
- 테이블 복제 (CTAS)
- 데이터 비움 (Truncate)
- 변경된 데이터 삽입 (Insert)
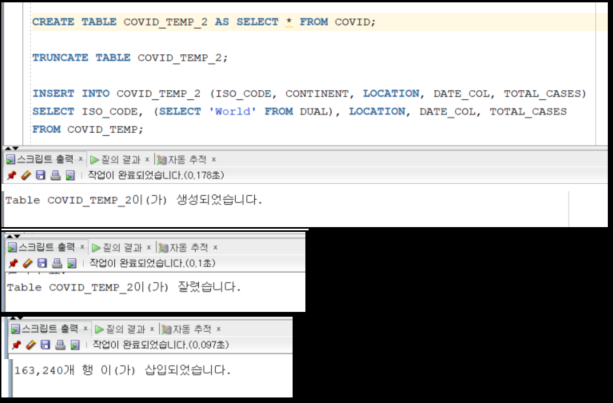
물론, 기존에 생성된 테이블 COVID_TEMP에 제약조건 또는 인덱스가 있는 경우
Truncate Table 전에 drop 해줘야 하는 것을 잊지 말자.
또한 Insert 이후에 적절한 제약조건과 인덱스를 추가하는 것이 좋다.
이번 테스트에서 아쉬운 점은 데이터가 16만건이 아니라 수 백만 건이었다면
성능 비교 부분에서 좀 더 확실하게 알 수 있었을 것이다.
또한 인덱스가 없이 테스트 하였기 때문에, 적당한 인덱스를 주고서도 테스트 했다면
결과에 달라짐을 비교해 보는 것도 유의미 했을 것이다.
참고: SQL 전문가 가이드, 한국데이터산업진흥원 p.704
