오랜시간 코딩테스트는 발목을 잡는 산이였다.
이름부터가 오묘한 아우라가 있달까..
문자열 다루는 간단한 놀이를 끝내면 처음마주하는 관문이 DFS, BFS이다.

나와같이 이름에서 벽을 느껴버린 개린이들에게 내가 이해한 방식을 정리도할겸 공유하고자 한다.
탐색
탐색은 특정 조건을 만족하는 값을 찾는다는 뜻이다. 주어진 메모리에 어떤 값이 있는지, 얼마나 있는지, 어떤식으로 있는지 등을 확인하고 체크한다.
> 간단하게 예를들어 2차원 배열에서 몇 개의 인덱스에 1이있고 0이 있는지, 어느 인덱스에 있는지 등을 찾는것도 탐색이다.
DFS
깊이 우선 탐색. 깊게 파고드는 방식으로 특정 조건을 만족하는 값을 고구마 캐듯 우루루 찾아오는 방식이다. 찾으려는 값이 깊이 있을 수록 탐색에 효과가 좋은 방식이다. 이것 뿐만이 아니고 코드가 깔끔해서도 많이들 쓰는것 같다.
[탐색의 순서]
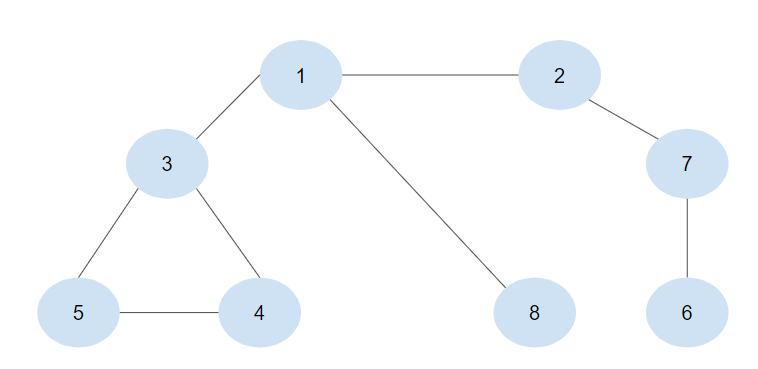
많이 봤을 그림이다. 탐색할 순서만 그려보도록 하겠다.
1-> 2-> 7-> 6-> 3-> 4-> 5-> 8DFS 방식은 탐색 노드의 자식노드 , 그 자식노드의 자식노드 이런식으로 깊게 깊게 탐색한다. (= 값을 찾는다)
로직이 반복되는 부분이 많아 재귀를 많이 사용하고, 탐색중인 자식노드의 탐색이 끝나면 부모노드, 그리고 그 부모노드의 인접노드를 찾아야하기에 Stack과 같이 많이 쓰인다.구현방식
1. 문제에서 재귀로 구현해야할 부분을 캐치해내는게 중요하다. 어떤 로직을 재귀함수로 반복할거며, 어떤 값을 인자로 전달할지를 정한다.
2. 재귀함수에서 어떤 조건에 의해 탈출될건지 탈출조건을 정한다.
- 1번 로직을 태울 인자를 Stack에 넣고, 확인한 노드에 대해선 별도의 배열을 만들어 해당 노드를 체크했음을 표시해둔다.(이후에 다시 방문하지 않도록)
함수 따라가보기
재귀를 할때 많이들 놓치고 헷갈려하는거같다. 이걸 꼭 해봐야 감이 약간은 온다.
[2차원 배열에서 1찾기]int[][] arr = {{0,0},
{1,0}};
//main : 반복문으로 인자 i,j전달
dfs(0,0)
//dfs(int i, int j)
//탈출조건1 - i, j가 arr범위를 벗어나면 return(생략)
//탈출조건2 - 찾으면 나가기
if(arr[i][j] == 1) return;
//구현부분
dfs(i, j+1);
dfs(i+1, j);
이런 과정을 거치게 된다. 생긴게 어려워서 그렇지 몇번 따라가보고 그리다 보면 조금씩 쉬워진다. 하루이틀이면 충분하니 꼭 따라 그리면서 이해해보길 바란다. 예제는 야매로 했다 ..ㅎㅎ
BFS
너비 우선 탐색이다. 가까운 노트부터 점진적으로 탐색해 가는방법이다.
[탐색의 순서]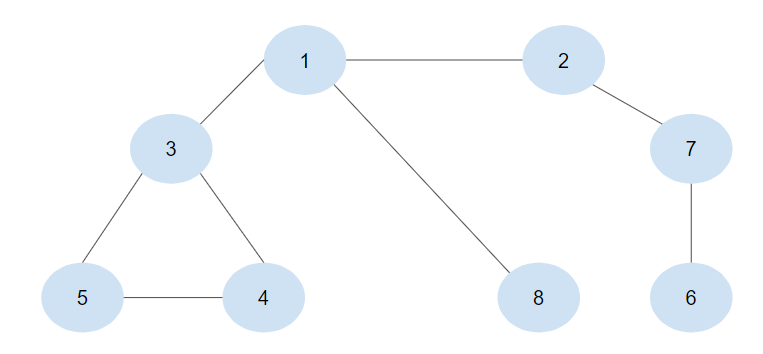 1->2->3->8->7(부모2)->4(부모3)->5(부모3)->6(부모7)
1->2->3->8->7(부모2)->4(부모3)->5(부모3)->6(부모7)
BFS는 탐색노드의 근접한 노드를 확인하고 그 다음 근접노드를 구해가는 특징을 따라 Queue와 함께 쓰인다.
구현방식
1. 탐색노드를 Queue에 넣는다.
2. 인접노드도 Queue에 넣는다.
위 과정을 반복한다.
정리하자면 결과가 도출되는 여러 경우의 수중에 한 경우씩 확인해 보는게 DFS, 각 경우의 수를 순서대로 확인해가는게 BFS 이다.
BFS는 재귀를 쓰는 DFS보다는 속도가 빠르다는 사실은 참고로 기억해두자.
위 내용 중 틀린사항이나 지적하실 부분있으면 언제든 환영입니다.
