
What is the Hash Table?
Hash Table은 key-value system을 이용하여, 자료를 정리한다.
key: value
dictionary를 생각하면 된다.
프로그래밍에서 같은 함수가 각기 다른 프로그래밍 언어에서 존재한다.
JS에서는 Object
Python에서는 Dictionary
Go에서는 map 기타등등
그렇다면 해쉬테이블과 배열(Array)의 비교해보자.
예를 들어 레스토랑의 메뉴를 배열에 저장한다면?
menu = [
{ name: "coffee",price: 10},
{ name: "burger",price: 15},
{ name: "tea",price: 15}
]이 중에서 tea의 값을 알고 싶다면 linear Search(선형검색)을 통해서 순차적으로 찾을 것이다. => 시간이 많이 걸린다!
순차적으로 하나하나 쓰고 싶지 않을때 어떻게 써야할까?
같은 메뉴를 해쉬테이블로 만들어보자
menu = {
coffee : 10,
burger : 15,
tea : 15
]
이 경우 tea를 알고 싶으면 tea = key가 될것이고 hash tables는 가격을 Value로 제공한다.
시간 복잡도를 비교해 본다면?
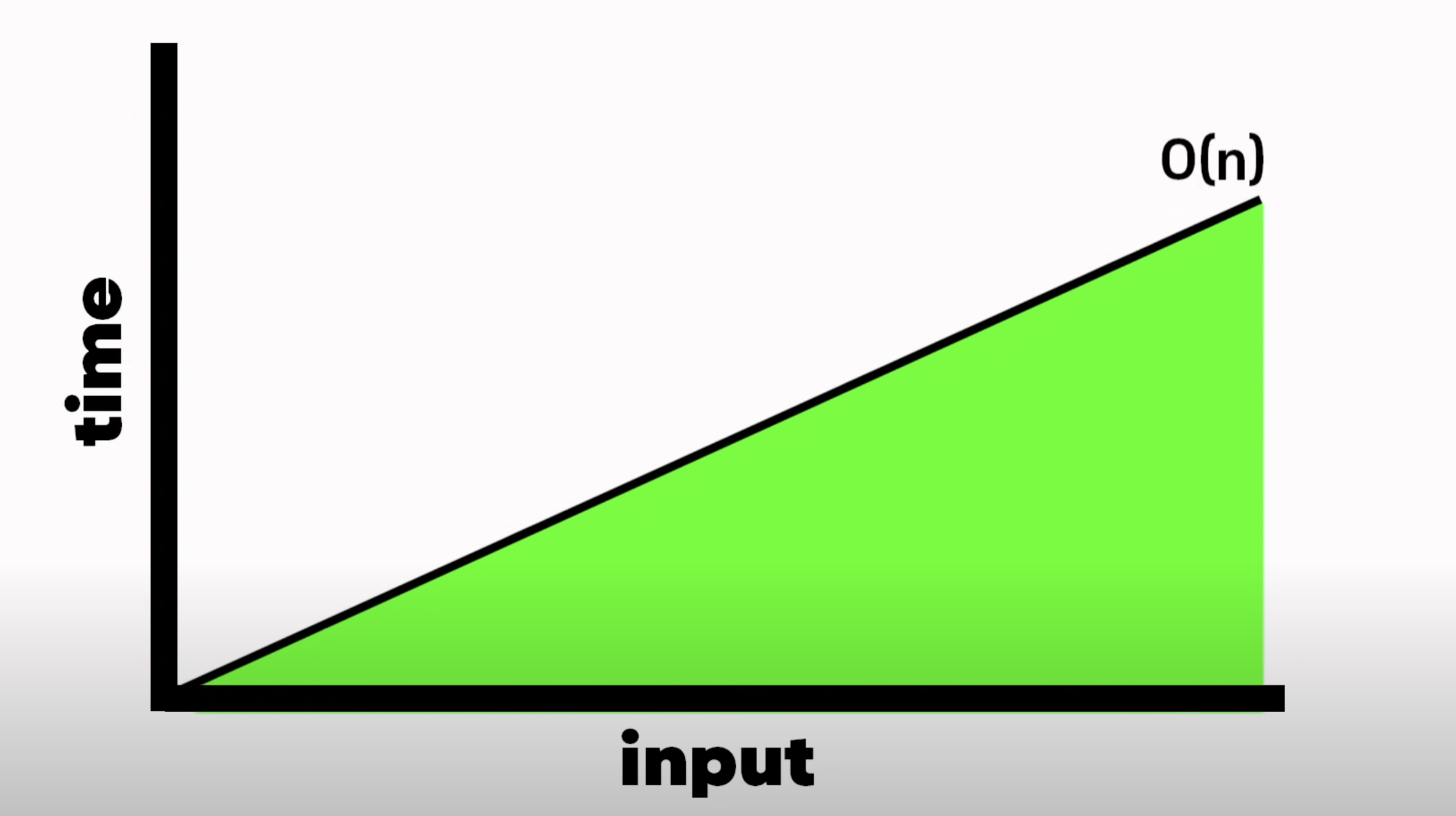
처음 했던 방법은 O(N)이라 할 수 있다. Linear Time(선형 시간)
아이템이 많을수록 찾는 시간도 오래 걸린다.
그렇다면 해쉬테이블은?

O(1) 즉, Constant Time(상수 시간)이다.
해쉬테이블에서 어떤 값을 찾더라도 소요되는 건 오직 하나의 단계이기 때문에 배열에 비해서 굉장히 빠르다. 삭제 했을때도 마찬가지이다.
value만 쓰고 싶다면?
conturies = [
"🇬🇷",
"🇬🇱",
"🇬🇳",
"🇳🇦",
"🇳🇷",
"🇦🇶"
]key 값이 없는데 어떻게 찾냐?
conturies = {
"🇬🇷": true,
"🇬🇱": true,
"🇬🇳": true,
"🇳🇦": true,
"🇳🇷": true,
"🇦🇶": true
}
#key가 국기가 되고, value는 그저 true 이다..!이렇게 되면 한 스텝만에 원하는 값을 찾을수(검색) 있다.
해쉬테이블은 어떻게 작동하고 왜 "Hash"테이블이라고 할까?
Hash Tables에는 array 구조가 있다.
인덱스 값을 던져 주었을 때 key의 value값을 찾게 해주는 방법은 무엇이 있을까? 바로 Hash function(해시 함수)가 그것을 가능하게 해준다.

key_2의 값이 해시 함수를 지나면서 index가 0인 값을 자동으로 찾아주게 된다. 조금 더 쉽게 가보자
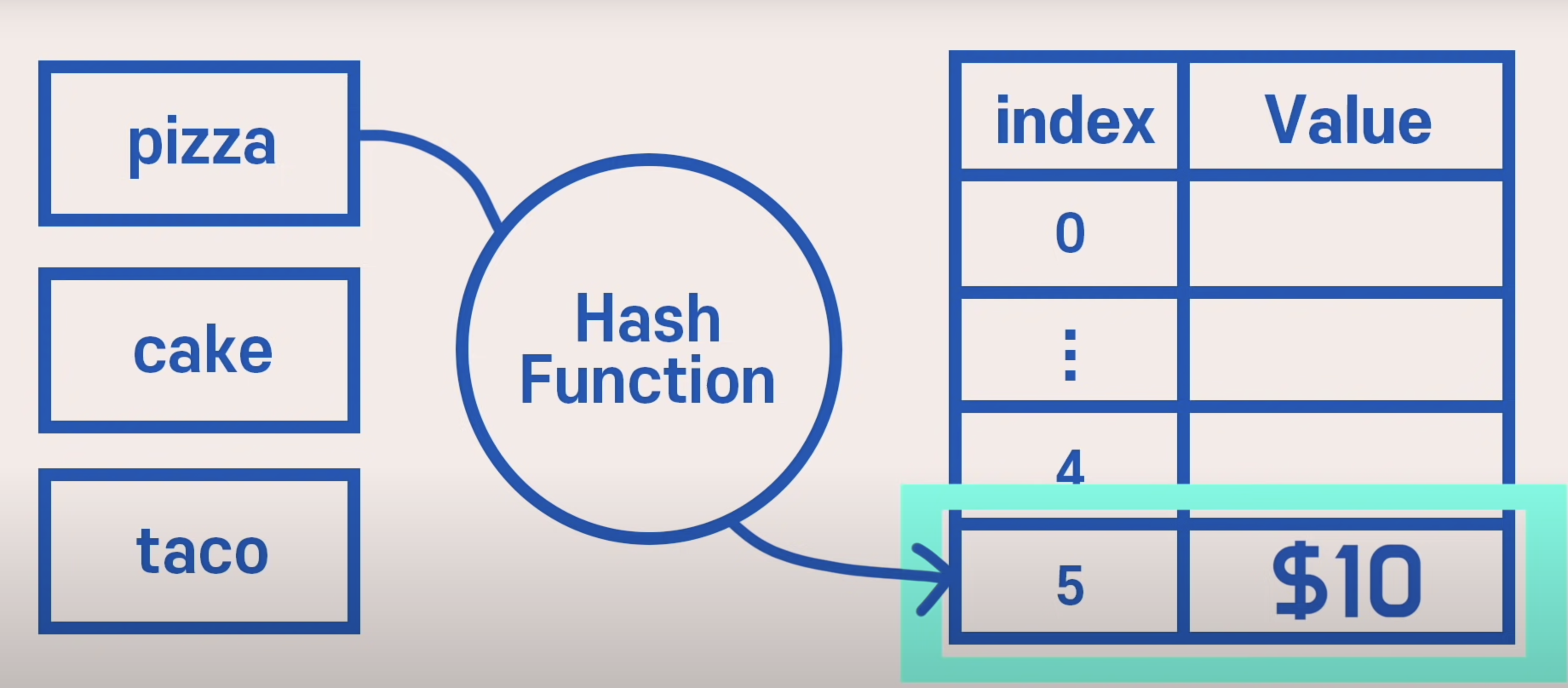
pizza의 알파벳 숫자를 5라고 했을 때 해시함수는 인덱스 5를 찾는다고 가정한다면 인덱스가 5번인 곳에 10을 넣어준다.
cake는 알파벳이 4이기 때문에 4에 value값을 넣어준다. 그런데 taco도 4이기 때문에 오류가 일어나는데 이것을 Hash Collision(해시 충돌)라고 한다.
이를 해결하기 위한 하나의 방법은 인덱스 4의 값에 cake와 taco 두개의 값을 가지고 있는 list를 만드는 것이다.
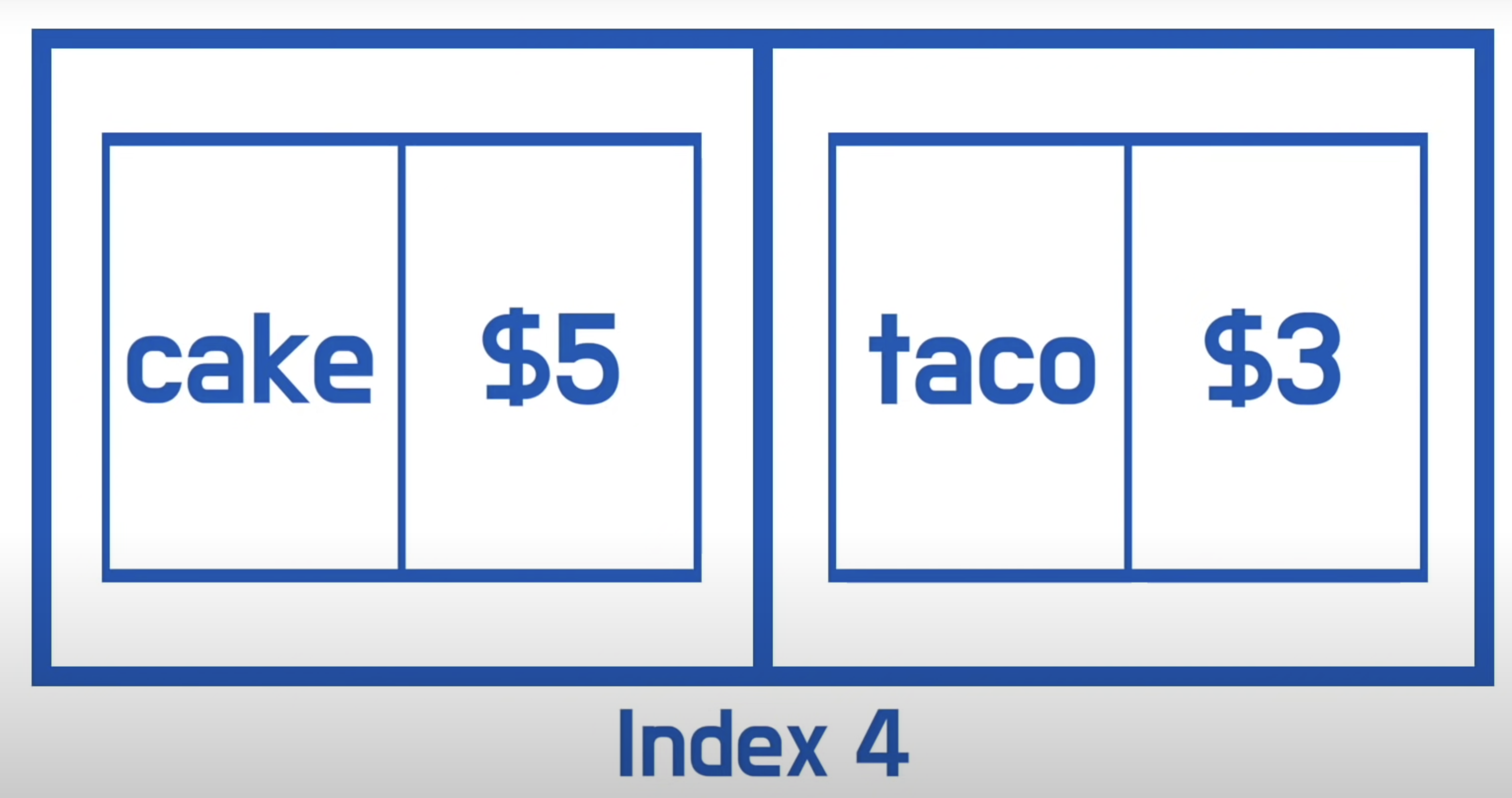
따라서 우리는 Hash Tables에 cake가격을 물으면, Cake = key라는 해시함수에 넣고 이는 '4'라는 숫자를 줄 것이고, 리스트의 4로 이동하여 선형검색을 할 것이다.
바로 이러한 이유 때문에 Hash Table은 언제나 상수 시간(0(1))은 아니다.!
왜냐하면 충돌이 있을 수 있고, 그 경우 선형검색을 해야하기 때문이다.
참고 자료 : 노마드코더 유튜브
