
Intro
Index에 대한 이야기는 학부 시절에는 들어 본 적이 없었다. 백엔드 개발자 업무를 처음 할 때 가장 와닿았던 건 서버사이드 프로그래밍이 이렇게 어렵구나 보단 DB를 어떻게 활용하느냐에 따라 내가 짜야 할 코드의 양이 줄어들 수 있느냐였다.
Index 포스팅 시작하도록 하겠다.
Index?
데이터베이스 테이블의 검색 속도를 향상 시켜주는 자료구조라고 할 수 있다 .
어렵게 생각 할 건 없다. 우리가 도서관에서 책을 찾는다고 가정 해 보자.
해리포터 시리즈를 사려면 어떻게 해야할까? 소설 섹션에서 ㅎ 로 시작하는 책들을 뒤져봐야 할 것이다. 굳이 도서관의 입구부터 책을 하나하나 뒤져 볼 필요는 없다. 흔히 말하는 선형 탐색을 시작부터 할 필요는 없다는 것이다.
책 안에서 특정한 내용을 찾을때도 마찬가지다. 책의 시작부터 마치 for문 돌리듯이 내용들을 훑어봐도 답은 찾을 수 있다. 하지만 목차에서 특정 내용과 관계 된 내용들을 찾아서 탐색해도 답은 나온다. 오히려 훨씬 빠르게 답을 찾을 수 있다.
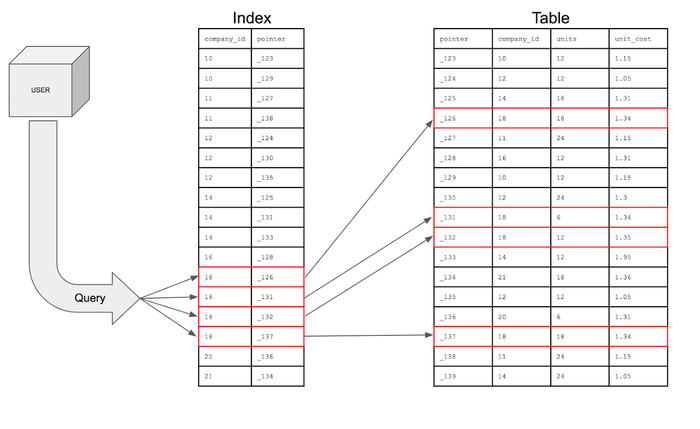
Index 또한 마찬가지다. 이름 그대로 어떠한 데이터의 위치를 확인하여 데이터를 검색하면 훨씬 빠른 시간에 데이터를 검색 해 낼 수 있다. 이로 인해 SELECT, UPDATE, DELETE 등 데이터를 조회하는 연산의 성능을 크게 올릴 수 있다. Index를 쓰지 않는다면 앞서 말했듯 For문을 처음부터 돌리는, 즉 Full Scan을 해야한다. 데이터의 갯수가 엄청나게 많다면? 당연히 조회 성능이 떨어진다.
| USER_ID | USERNAME | CLASS | SPEC |
|---|---|---|---|
| 20160111 | USER01 | WARRIOR | FURY |
| 20160222 | USER02 | DRUID | BALANCE |
| 20160321 | USER03 | PALADIN | PROTECTION |
SELECT * FROM USERTABLE WHERE CLASS = 'PALADIN'흔히 40만번의 연산 이후부터는 컴퓨터의 성능에 따라 결과를 도출하는 속도가 달라진다고 한다. Index의 적절한 사용은 성능 문제를 해결하기 위해 큰 비용을 치루지 않도록 도울 수 있다.
CREATE INDEX USER_TABLE_INDEX ON USER(USER_ID)Index의 특징
반드시 데이터가 오룸자순으로 정렬되어있어야 한다. 서점에서든 도서관에서든 책의 목차든 정렬되지 않은 데이터를 통해 데이터를 검색할 수는 없는 노릇이다.
정렬 되어있다는 장점으로 인해 WHERE 절, ORDER BY 절, MIN, MAX 연산에 대해 효율적인 처리가 가능하다. 또한 시스템의 부하를 줄여 줄 수 있다.
하지만 인덱스를 관리하기 위해 DB의 저장공간을 사용해야 하고 추가 작업이 필요하다. 그리고 오히려 성능이 저하되는 경우가 있는데, CREATE, DELETE, UPDATE가 빈번한 속성에 인덱스를 거는 경우 오히려 인덱스의 크기만 커지고 성능은 떨어지는 경우가 생긴다.
그러므로 규모가 적당히 크고 INSERT, UPDATE, DELETE가 자주 발생하지 않으며, JOIN이나 WHERE, ORDER BY 에 자주 사용되는 컬럼, 데이터의 중복도가 낮은 칼럼 등에 인덱스를 걸어 주어야 한다.
Index의 자료구조
크게 Hash Table과 B+ Tree를 사용한다.
Hash Table은 다들 잘 알겠지만 Key, Value로 데이터를 저장한다. key값을 통해 고유한 index를 생성하고, 그 Index에 저장 된 값을 꺼내오는 방식으로 동작한다.
O(1)의 성능을 보이지만, 부등호 연산 등에 취약하다. 오직 equal 연산에 최적화 되어있는 자료구조 형태기 때문이다.
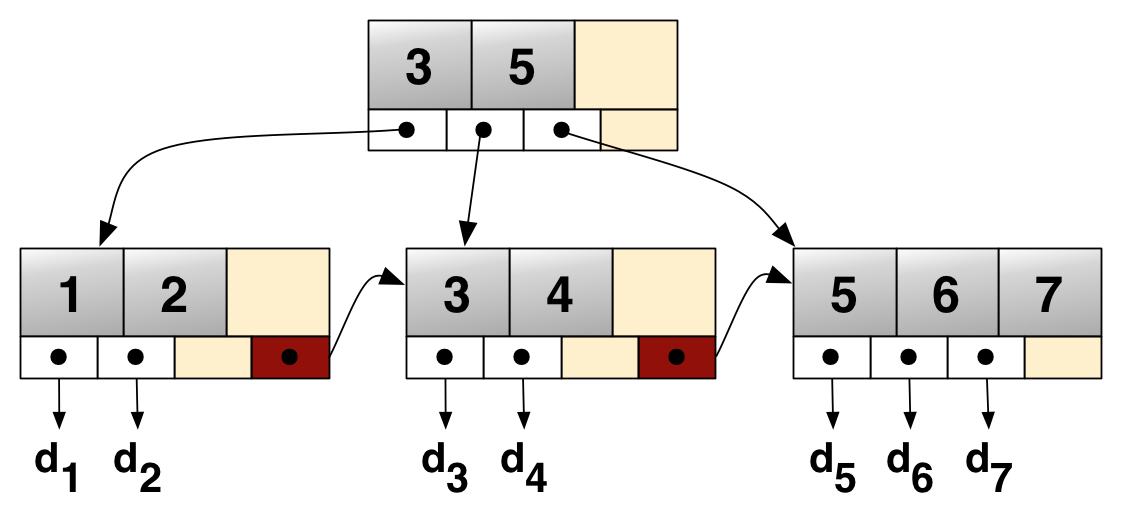
B+ Tree는 Binary Tree와 비슷하지만 다르다. Leaf 노드만 인덱스와 함께 데이터를 가지고 있고 나머지 노드들은 데이터를 위한 Key만 가지고있다. Leaf 노드들은 Linked List로 연결되어 있으며 데이터 노드의 크기는 인덱스 노드의 크기와 같지 않아도 된다.
부등호를 활용한 순차 검색 연산이 일어날 때 LinkedList를 통해 해당 연산을 용이하도록 최적화 한 자료구조다.
Outro
Index에 대해 짧게 알아보았다. Index의 개념과 원리, 검색 성능을 높이기 위해 사용되지만, 데이터의 규모가 충분히 크며 INSERT, UPDATE, DELETE가 자주 발생하지 않으며, JOIN이나 WHERE, ORDER BY 에 자주 사용되는 컬럼, 데이터의 중복도가 낮은 칼럼 등에 인덱스를 걸어 주어야 한다는 사실에 대해 알아보았다.
다음 포스팅의 주제는 API에 대해 다뤄 보도록 하겠다.
Reference
https://ko.wikipedia.org/wiki/B%2B_%ED%8A%B8%EB%A6%AC
https://choicode.tistory.com/27
https://mangkyu.tistory.com/96
https://tecoble.techcourse.co.kr/post/2021-09-18-db-index/
