Title: Evaluating Object Hallucination in Large Vision-Language Models
- Authors: Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, Ji-Rong Wen
- Accepted to EMNLP 2023
- Citation Count: 532 (as of Nov. 15, 2024)
- Paper Access: https://arxiv.org/abs/2305.10355
1. Overview
background
- success of LLM derives more powerful multi-modal models based on LLMs
- ex) GPT-4 (OpenAI, 2023)
- Vision-Language Pretrained Model (VLPM) + LLM = Large-Vision Language Model (LVLM)
- reuse vision encoder in VLPM
- replace language encoder with LLMs
- proceed vision-language pretraining & vision instruction tuning
- both LLMs & VLPMs suffer from hallucination
Goal
- evaluate object hallucination of LVLMs
Contribution
- conduct an empirical study on object hallucination for LVLMs
- disclose potential reasons behind object hallucination for LVLMs
- propose object hallucination evaluation approach called POPE
2. Background
Large Vision-Language Model
- VLPM + LLM = LVLM
- LVLM = vision encoder + language encoder (LLM) + cross-modal alignment network
- Training
- 1) pretrain vision encoder & language encoder respectively
- 2) align encoders through image-text alignment pre-training -> enable LLM to generate meaningful caption
- 3) finetune model on image-text instructions
Object Hallucination
- Object Hallucination: the model generating descriptions or captions that
contain objects which are inconsistent with or even absent from the target image
1) coarse-grained object hallucination: object level
2) fine-grained object hallucination: attributes or characters of objects (ex. position, number, attribute)

- effect of object hallucination:
- result in unexpected consequences
- hinder safe use of LVLM in real-world deployment (ex. autonomous driving system)
3. Object Hallucination Evaluation in LVLMs
Caption Hallucination Assessment with Image Relevance (CHAIR)
- Object Hallucination in Image Captioning, EMNLP 2018
- calculate the proportion of objects that appear in the caption but not the image
- CHAIR_I: evaluate hallucination degree at object instance level
- CHAIR_S: evaluate hallucination degree at sentence level

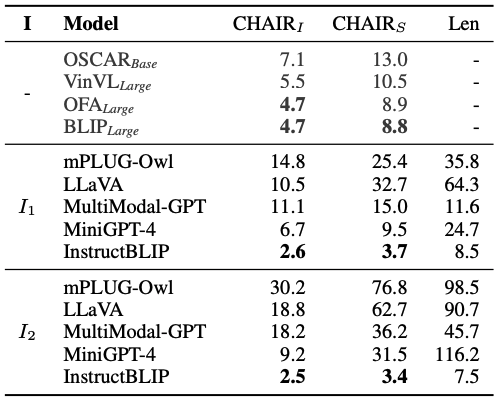
• I1: Generate a short caption of the image.
• I2: Provide a brief description of the given image
• dataset: MSCOCO
Evaluation Results
- most instruction-tuned LVLMs suffer from the object hallucination problem, even more serious than small models
- InstructBLIP hallucinates less than other LVLMs.
- its visual instructions are collected from a wide variety of publicly available datasets, which are relatively short. (other LVLMs mostly employ the visual instructions generated by unimodal LLMs, which are longer and more informative, but may involve unexpected descriptive information - hallucination inherent from LLMs)
- Disadvantages of CHAIR
- instability of the CHAIR metric when different instructions are employed
- needs complex human-crafted parsing rules to perform exact matching, which has not been adapted to the special generation styles of LVLMs and may lead to misclassification errors.
4. Influence of Instruction Data on Object Hallucination
Hypothesis
(1) LVLMs are prone to hallucinate frequently appearing objects in the visual instruction datasets.
(2) LVLMs are prone to hallucinate objects that frequently co-occur with ground-truth objects in the image.
- Qualitative Analysis
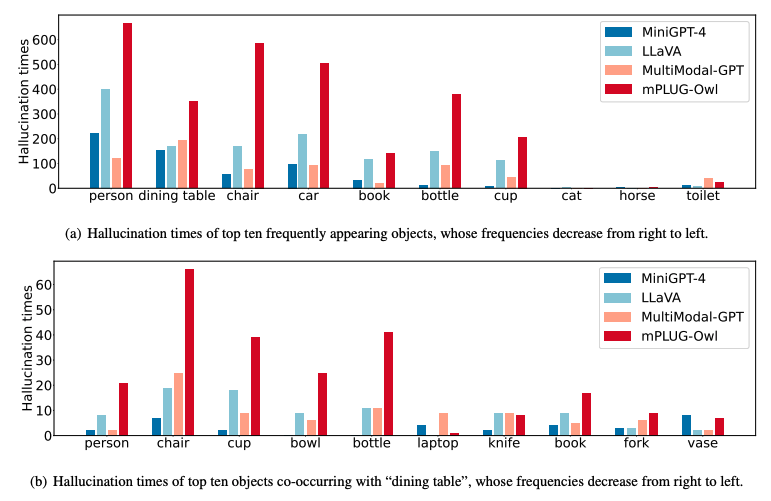
- reveals that the frequently appearing and co-occurring objects in the visual instruction dataset are indeed more likely to be hallucinated by LVLMs
- Quantitative Analysis
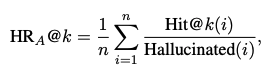
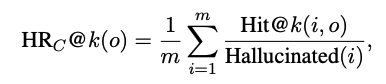
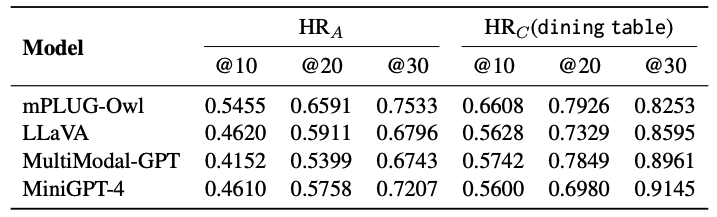
- approximately half of the hallucinated objects in each image belong to the top 10 frequently appearing COCO objects, while more than half are among the top 10 frequently co-occurring objects with the objects already present in the image.
5. Polling-based Object Probing Evaluation (POPE)
Overview
- POPE formulates the evaluation of object hallucination as a binary classification task that prompts LVLMs to output “Yes” or “No”, e.g., “Is
there a chair in the image?” - by sampling objects that LVLMs are prone to hallucinate, we can construct a set of hard questions to poll LVLMs.
- Advantages
- As standard answers to these questions are just “Yes” or “No”, we can easily identify them without complex parsing rules
- avoid the influence of instruction designs and caption length
- -> guarantee stability, fairness and flexibility
Definition
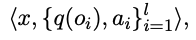
-
construct a set of triplets: image, multiple questions, and their answers (“Yes” or “No”).
-
ground-truth : nonexistent objects = 1 : 1
-
sampling strategies for questions with the answer “No”
1) Random Sampling: randomly sample the objects that do not exist in the image.
2) Popular Sampling: select the top-k most frequent objects in the whole image dastaset that do not exist in the current image (k=l/2)
3) Adversarial Sampling: rank all objects according to their co-occurring frequencies with the ground-truth objects, and then select the top-k frequent ones that do not exist in the image.
-
-
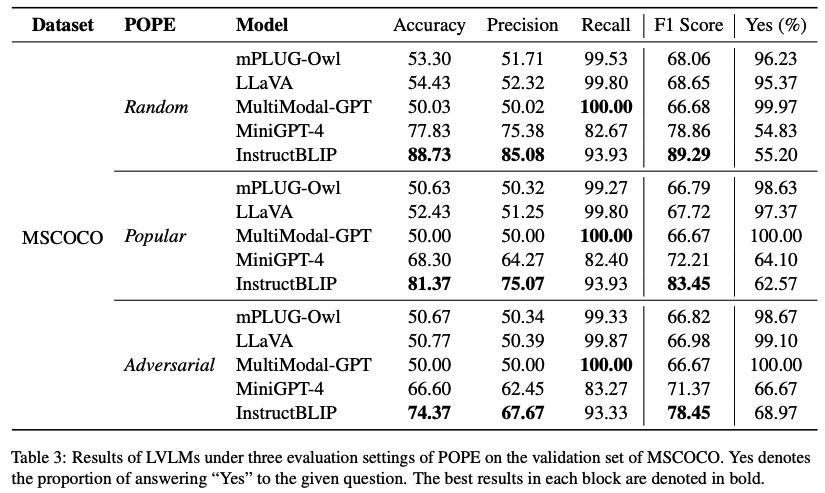
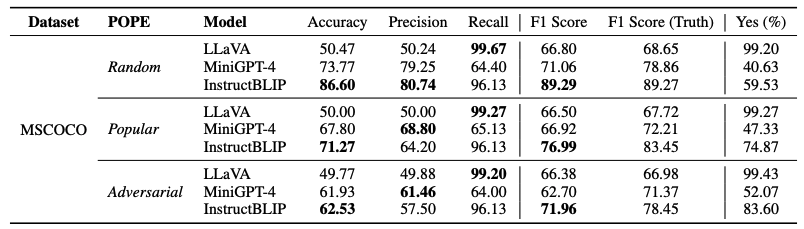
Evaluation on MSCOCO
- Setting
- randomly selected 500 images from MSCOCO validation set with more than 3 ground-truth objects in the annotations
- construct 6 questions for each image
- metrics: Accuracy, Precision, Recall, F1 Score
- Result
- InstructBLIP performs the best, while LLaVA,MultiModal-GPT and mPLUG-Owl suffer more severe hallucination problem.
- LLaVA, MultiModal-GPT, mPLUG-Owl -> overconfident, extremely prone to answer “Yes” (near 99%)
- performance decreases, from random settings, to popular and adversarial -> LVLMs are prone to hallucinate the frequently appearing and co-occurring objects.
- Setting
Advantage of POPE
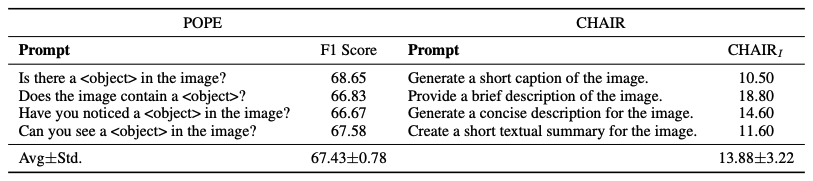
- Stability - test the effect of variations in prompt templates
- method: calculate the standard deviation of the F1 score
- result: standard deviation of the F1 score is significantly lower than CHAIR_I -> confirm that POPE exhibits higher stability when faced with different prompts.
- Scalability - show POPE can be easily extended to datasets without annotations
- method: adopt SEEM (Zou et al., 2023) to annotate images from three datasets (i.e., MSCOCO, A-OKVQA (Schwenk et al., 2022) and GQA (Hudson and Manning, 2019)) and build POPE based on the segmentation results.
- result: performances of all LVLMs mostly follow the same trend as annotation-based POPE -> when combined with automated segmentation tools, POPE can evaluate unannotated datasets effectively
- Consistency - prove whether the Yes/No responses of LVLMs genuinely reflect their perception of objects
- method: measure the consistency between the POPE responses and captions generated by LVLMs
- examine if objects that receive "No" responses seldom appear in the captions & if objects frequently mentioned in captions usually receive "Yes" answers
- result:
- out of the 1303 and 1445 objects that are given "No" responses by InstructBLIP and MiniGPT-4, merely 0 and 5 of those objects were referenced
in captions. - out of the 664 and 1034 objects mentioned in the captions by these models,
664 and 961 respectively received a "Yes" verdict. - -> underscore a robust correlation between objects’ presence in captions and Yes/No responses in POPE questions about them
- out of the 1303 and 1445 objects that are given "No" responses by InstructBLIP and MiniGPT-4, merely 0 and 5 of those objects were referenced
Impact of Hallucination on VQA
- compare performances in VQA and image captioning
- Datasets:
- A-OKVQA: A knowledge-based VQA dataset
- GQA: A structured question-answering dataset
- Models:
- InstructBLIP, MiniGPT-4, LLaVA
- Result:
- InstructBLIP: demonstrated the least hallucination issues & the highest performance in VQA
- MiniGPT-4: higher POPE F1 scores than LLaVA & poorer VQA performance compared to LLaVA -> MiniGPT-4 was primarily trained on image caption datasets, limiting its VQA capabilities.
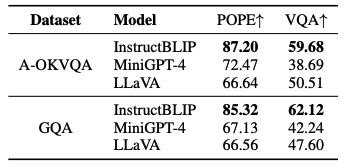
- Key Findings
- no clear correlation between POPE results and VQA performance
- models experiencing less hallucination do not necessarily perform better in VQA tasks
6. Conclusion
- Research Objective:
- Investigated the issue of object hallucination in Large Vision-Language Models (LVLMs)
- Proposed a new evaluation method, POPE (Polling-based Object Probing Evaluation), to address the limitations of existing evaluation approaches.
- Research Findings:
- LVLMs suffer from significant object hallucination issues, as evidenced by experiments on the MSCOCO dataset.
- A major cause of hallucination is identified as the imbalanced object distribution in visual instruction datasets.
- POPE demonstrated superior stability and reliability compared to the traditional CHAIR evaluation metric.
- Contributions:
- conducted a systematic evaluation of object hallucination in LVLMs and analyzed its underlying causes.
- introduced POPE
7. Limitations
- Focus on Object Hallucination:
- specifically focused on object hallucination and did not assess the overall performance of LVLMs
- a high score in POPE does not necessarily indicate a model's superiority in other aspects
- Evaluation Data Constraints:
- results might be influenced by the specific data distribution (evaluations were conducted on a subset of MSCOCO validation data)
- Limitations of POPE:
- LVLMs may fail to provide explicit "Yes" or "No" answers, potentially leading to inaccuracies
- when using automatic segmentation tools (e.g., SEEM), discrepancies between tool-generated labels and human annotations may impact the results
- Restricted Model Scope:
- did not include recently released or closed-source LVLMs
8. Application
For Image-Tabular MLLM VQA Model,
- Evaluate Object Hallucination in Multimodal Models:
- Problem: image-tabular VQA model might experience object hallucination when combining image and tabular data, where the model could generate explanations that include objects not present in the image or data.
- Application: can assess and mitigate hallucinations in multimodal model by utilizing the POPE
For Sketch Generation Model,
- Object Hallucination in Sketch Generation:
- Problem: when generating sketches, the model may hallucinate objects that aren't present in the prompt, leading to misleading or incorrect outputs.
- Application: POPE, combined with VQA guidance, can help ensure that the generated sketches are grounded in the actual content of the prompt, avoiding hallucination.
For both studies,
- Balance out Data:
- Problem: imbalanced object distribution in training datasets leads to hallucinations.
- Application: incorporate balanced sampling strategies to address potential data imbalances.
