Finetune like you pretrain: Improved finetuning of zero-shot vision models 논문을 읽는데 in-distribution(ID)와 out-of-distribution(OOD)라는 용어가 나왔다.
본문에 이 개념의 정의가 설명되어 있을 줄 알았는데, 안 되어 있었다. 그 말인 즉슨 설명 없이도 당연히 알고 있어야 하는데 내가 모르고 있었다는 뜻이다. 잠시 반성의 시간을 가지고,
⏰...
in-distribution(ID)와 out-of-distribution(OOD)이 각각 무엇인지에 대해 알아보도록 하겠다.
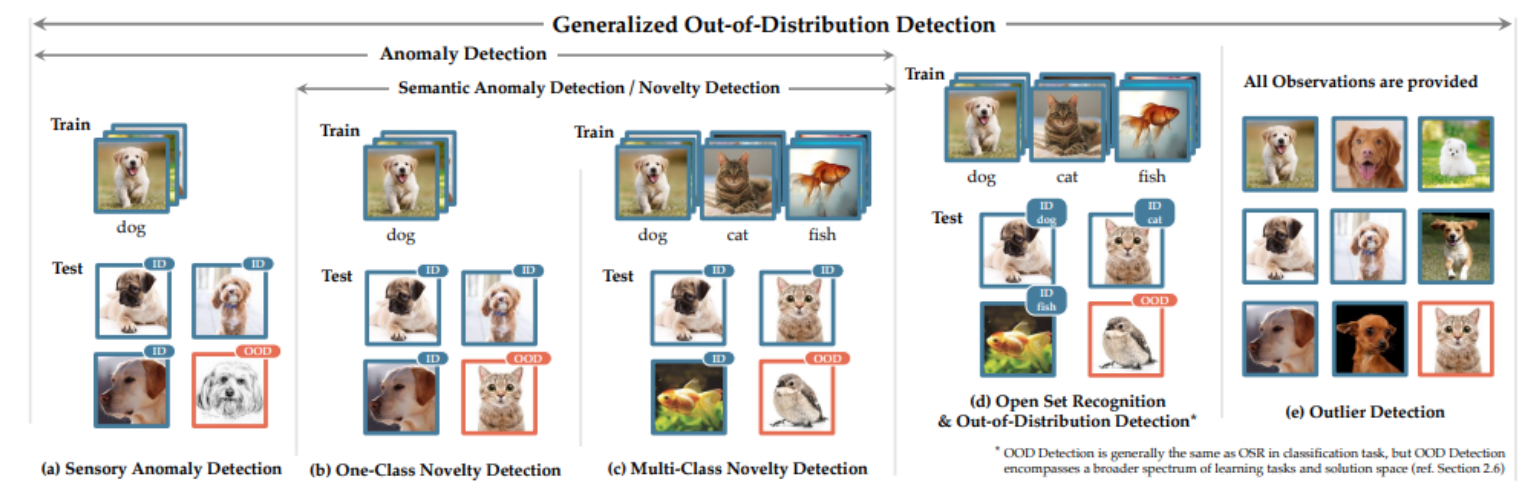
일단, 이 두 용어는 (특히 ODD는) Anomaly detection 연구에서 많이 등장하는 용어이다.
out-of-distribution(OOD)
out-of-distribution(ODD) 데이터는, classifier가 학습된 데이터의 분포와는 다른 분포를 갖는 데이터를 의미한다. OOD 데이터는 모델이 학습 중에 본적이 없기 때문에 "unseen" 데이터라고도 불린다. 즉 classification 문제에서 ODD는 학습 데이터에 포함되지 않은 class를 가진 데이터를 의미한다. 예를들어 CIFAR-10을 분류하는 모델 입장에서 SVHN 데이터는 ODD라고 할 수 있다. 이런 ODD 데이터를 탐지하는 것은 딥러닝 모델의 안정성에 있어서 굉장히 중요한 문제이다.
in-distribution(ID)
OOD의 정의는 많이 나와있지만, in-distribution(ID) 데이터가 무엇인지에 대해서 명확히 정의하고 있는 문서는 비교적 적었다.
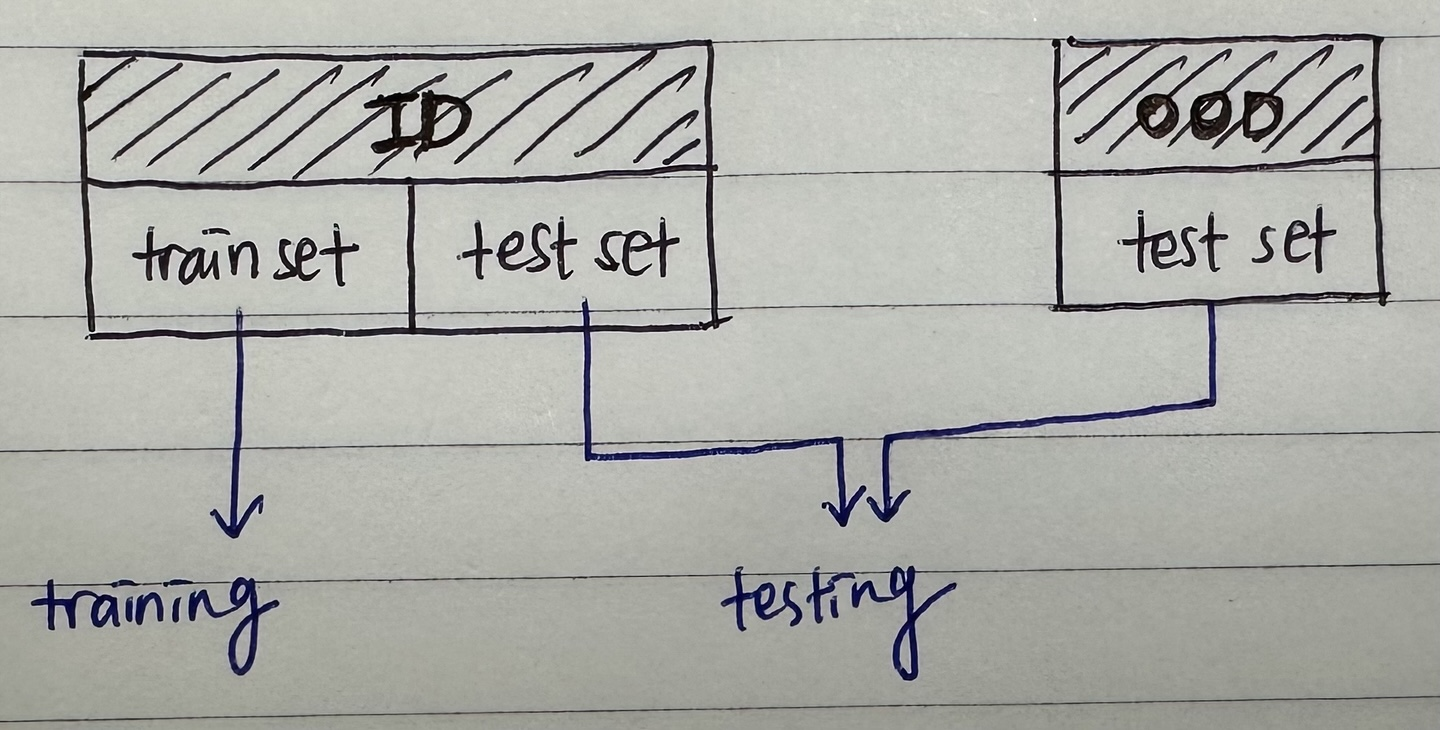
ID 데이터셋은 간단히 말해서 training data가 속해있는 데이터셋이라고 생각하면 될 것 같다.
ID 데이터셋으로 network를 학습시킨 뒤, test 단계에서 ID 데이터셋과 OOD 데이터셋을 test set으로 사용을 하게 된다. 당연한 이야기지만, 학습에는 ID 데이터셋만 사용하게 된다.
reference
http://dsba.snu.ac.kr/seminar/?mod=document&uid=246
https://gbjeong96.tistory.com/60
https://paperswithcode.com/task/ood-detection
https://hoya012.github.io/blog/anomaly-detection-overview-2/
