
테이블 변경 및 조작을 공부하기 전, 실습용 테이블을 먼저 만들어보자!
<도서 테이블>
| 번호 | 제목 | 가격 |
|---|---|---|
| 정수 | 가변길이 문자열 최대길이 = 30 | 정수 |
use 도서관;
create table 도서(번호 int, 제목 varchar(30), 가격 int);
select * from 도서;
▶ 테이블 변경
▷ 열 추가 / 삭제
이미 테이블을 생성한 후 구조를 어떻게 수정할 수 있을까?
① 열 추가
alter table 도서 add 구입일자 datetime default "2023-10-23";
② 열 삭제
alter table 도서 drop 구입일자;
▷ 제약조건 추가/삭제
① 기본 키 추가
alter table 도서 add primary key (번호);② 기본 키 삭제
alter table 도서 drop primary key;③ 외래키 추가
alter table 도서 add constraint fk_name forign key (번호) reference 참조테이블(참조번호);④ 외래 키 삭제
alter table 도서 drop foreign key fk_name;⑤ 데이터 무결성 제약조건 추가
alter table 도서 add constraint chk_price check(가격>=0);⑥ 데이터 무결성 제약조건 삭제
alter table 도서 drop constraint chk_price;▷ 열 정의 변경
① 열 정의만 변경
/* ALTER TABLE 테이블_이름
MODIFY 열_이름 새_열_정의; */
alter table 도서 modify 구입일자 date;② 열 이름과 정의 동시 변경
/* ALTER TABLE 테이블_이름
CHANGE 이전_열_이름 새_열_이름 새_열_정의; */
alter table 도서
change 번호 도서코드 int not null;새 열 정의는 생략할 수 없다.
▷ 열 기본값 변경
① 열 기본 값 변경
alter table 도서 alter 구입일자 set default "2023-09-22";② 열 기본값 삭제
alter table 도서 alter 구입일자 drop default;▷ 이름 변경
① 테이블 이름 변경
ALTER TABLE 도서 RENAME TO book ;② 열 이름 변경
ALTER TABLE 도서 RENAME COLUMN 번호 TO 도서코드 ;▷ 테이블 제거
DROP TABLE [ IF EXISTS ] 테이블이름 [ RESTRICT | CASCADE ] - 테이블의 정의 및 모든 내용 삭제
- MySQL에서는 RESTRICT와 CASCADE는 아무 효과 없음.
(호환을 위해 문법만 허용)
▷ DB 제거
DROP { DATABASE | SCHEMA } [ IF EXISTS ] 데이터베이스이름 ;▶ 데이터 삽입 및 삭제
▷ 데이터 삽입
/* NSERT INTO 테이블이름 [ (열_이름_리스트) ]
VALUES ( 열_값_리스트 ) ; */
INSERT INTO 도서(번호,제목,가격) VALUES
( 101, ‘데이터구조’, 15000 ), ( 102, ‘자바’, 20000 ),
( 103, ‘C프로그래밍’, 20000 ), ( 104, ‘확률통계’, 13000 ) ;- 열이름리스트를 생략하는 경우는 테이블 정의의 열 순서대로 데이터를 나열한다.
▷ 데이터 삭제
① 모든 레코드 삭제
DELETE FROM 도서;- 삭제된 행 개수를 리턴한다.
TRUNCATE [TABLE] 도서 ;– 삭제된 행 개수가 필요치 않다면 TRUCATE가 속도가 더 빠르다.
▶ SQL의 테이블
- 폐쇄 시스템
- 테이블 처리 결과가 또 다시 테이블이 되는 시스템
- 중첩 질의문을 구성할 수 있는 이론적 기초
- SQL의 테이블
- SQL과 이론적 관계 모델은 차이가 있다.
- 기본 키를 반드시 가져야 하는 것은 아니다.
- 한 테이블 내에 똑같은 행 중복 가능하다.
- 이론상 SQL의 테이블은 튜플의 집합이 아니다.
- 같은 원소의 중복을 허용하는 다중 집합 (multiset) 또는 백(bag)
▶ 데이터 검색
- 기본 형식
SELECT 열_리스트 FROM 테이블_리스트 ;- 열 이름 별칭 사용 (AS는 생략 가능)
SELECT 제목, 가격-500 [AS] 할인가 FROM 도서;- 중복 행 제거
- ALL(기본값): 중복 행 포함하여 매칭된 모든행 리턴
- DISTINCT: 결과집합에 중복된 행 제거
- 여러 칼럼을 SELECT하더라도 DISTINCT 키워드는
SELECT 다음에 한 번만 사용함
- 여러 칼럼을 SELECT하더라도 DISTINCT 키워드는
SELECT [ALL | DISTINCT] 제목 FROM 도서;
- 정렬
- ASC: 오름차순, DESC: 내림차순
- 별도로 지정되지 않으면 오름차순(ASC)으로 정렬된다.
- 여러 열에 대해 지정된 경우, 순서대로 우선 정렬된다
SELECT * FROM 도서 ORDER BY 가격 ASC ; SELECT * FROM 도서 ORDER BY 가격 DESC, 번호 ASC ;
-
검색 건수 지정
- 결과집합(result set)의 처음 3개
SELECT * FROM 도서 ORDER BY 가격 LIMIT 3 ;
- 결과집합의 4번째 행부터 2개 행 검색 (첫번째 행 번호 : 0)
SELECT * FROM 도서 ORDER BY 가격 LIMIT 3, 2 ;
- 조건에 맞는 데이터 검색
- 간략화 된 일반 형식
/* SELECT 열리스트 FROM 테이블리스트 WHERE 조건; */ SELECT * FROM 도서 WHERE 번호 = 100 ; SELECT 제목, 가격 FROM 도서 WHERE 제목 = ‘확률통계’ ; SELECT * FROM 도서 WHERE 가격 > 13000; SELECT * FROM 도서 WHERE 가격 > 13000 ORDER BY 제목;
- 간략화 된 일반 형식
▶ 연산자
▷산술 연산자
– +, -, *, /, % %: 나머지 연산자
▷ 논리 연산자
AND, OR, NOT, &&, ||, !
▷ 비교 연산자
– =, <, <=, >, >=, <>, !=
/* BETWEEN~AND */
SELECT * FROM 도서
WHERE 가격 BETWEEN 15000 AND 20000;
/* IS NULL, IS NOT NULL */
SELECT * FROM 도서
WHERE 가격 IS NOT NULL;
/* IN, NOT IN */
SELECT * FROM 도서
WHERE 가격 IN (13000, 15000);▷ 문자열 비교 연산자
% : 와 매칭(0개 이상)
_ : 정확히 하나의 문자와 매칭
SELECT * FROM 도서 WHERE 제목 LIKE ‘데이터%’ ;
SELECT * FROM 도서 WHERE 제목 LIKE ‘%프로그래밍’ ;
SELECT * FROM 도서 WHERE 제목 LIKE ‘%프로%’ ;
SELECT * FROM 도서 WHERE 제목 LIKE ‘자_’ ;
SELECT * FROM 도서 WHERE 제목 LIKE ‘__통%’ ;▶ 함수
▷ 숫자 함수
- ABS(X): 절대값
- CEILING(X), CEIL(X): X보다 큰 값 중 가장 작은 정
수(올림)- CEILING(1.23) → 2 CEILING(-1.23) → -1
- FLOOR(X): X보다 작은 값 중 가장 큰 정수(내림)
- FLOOR(1.23) → 1, FLOOR(-1.23) → -2
- ROUND(X), ROUND(X,D): X를 반올림. (D자리까지)
- ROUND(1.58) → 2 ROUND(1.298, 1) → 1.3
- TRUNCATE(X, D): X를 D자리까지 남기고 버림
- TRUNCATE(1.999, 1) → 1.9 TRUNCATE(122, -2) → 10
-
POW(X,Y), POWER(X,Y): XY
-
RAND(), RAND(X): 난수(random number)
0 ≤ 𝑣 < 1 (실수) 리턴- 𝑖 ≤ 𝑅 < 𝑗 범위에서 임의의 정수 𝑅을 얻으려면:
𝐹𝐿𝑂𝑂𝑅(𝑖 + 𝑅𝐴𝑁𝐷() ∗ (𝑗 − 𝑖))- 무작위 순서로 데이터 추출:
SELECT * FROM 도서 ORDER BY RAND();- X: 시드(seed) 값
▷ 문자열 함수
- LENGTH(str), BITLENGTH(str), CHAR_LENGTH(str) : 길이
- LENGTH(‘text’) → 4 // 바이트 길이 단위
- BIT_LENGTH(‘text’) → 32 // 비트 길이 단위
- CHAR_LENGTH(‘text’) → 4 // 문자 길이 단위
- CONCAT(str1, str2, …) : 문자열 연결
- CONCAT(‘결과는 ‘, 120, ‘입니다.’) → ‘결과는 120입니다.’
- FORMAT(X,D): 숫자 X의 형태를 #,###,###.## 로 변환하고 D의 아래자리에서 반올림한 문자열을 리턴함
- FORMAT(12332.123456, 4) → ‘12,332.1235’
- FORMAT(12332.2, 0) → ‘12,332’
- LOWER(str), UPPER(str): 소문자/대문자로 변환
- LOWER(‘함수Test’) → ‘함수test’
- UPPER(‘함수Test’) → ‘함수TEST’
- LTRIM(str), RTRIM(str): 왼쪽/오른쪽 공백 제거
- LTRIM(‘ bar’) → ‘bar’ RTRIM(‘bar ‘) → ‘bar’
- LPAD(str, len, padstr), RPAD(: 결과 문자열의 길이가 len이 될 때까지 str의 왼쪽/오른쪽에 padstr을 덧붙임
- LPAD(‘함수’, 5, ‘?!’) → ‘?!?함수’ LPAD(‘함수’, 1, ‘?!’) → ‘함‘
- RPAD(‘함수’, 5, ‘?’) → ‘함수???’ RPAD(‘함수’, 1, ‘?’) → ‘함
- LOCATE(substr, str, pos), POSITION(substr
IN str)- str의 pos에서 시작해서 substr이 처음으로 나오는 포지션을 리턴
- LOCATE(‘bar’, ‘foobarbar’) → 4
- LCOATE(‘bar’, ‘foobarbar’, 5) → 7
- REPLACE(str, from_str, to_str)
- str의 from_str을 to_str로 대체
- REPLACE(‘www.mysql.com’, ‘w’, ‘Ww’)
→ ‘WwWwWw.mysql.com’
- SUBSTRING(str, pos, len)
- 문자열 str의 pos에서 시작하여 len개의 문자를 리턴
- SUBSTRING(‘데이터베이스 시스템’, 6, 3)
→ ‘스 시’ - SUBSTRING(‘데이터베이스 시스템’, -3, 3)
→ ‘시스템’
▷ 암호화 함수
- MD5(문자열)
- 길이가 32인 16진수 문자열
- 예: MD5(‘sungkyul’) →
ce19cb3fcf8b9cbbe99e6af3f3cbfdf2
- SHA1(문자열), SHA(문자열)
- 길이가 40인 16진수 문자열
- SHA2(문자열, 해싱 길이)
- 해싱 길이: 비트 단위(224, 256, 384, 512)
- 해싱 길이가 224로 설정되면, 결과값의 길이는 56
▷ UNHEX 함수
- UNHEX(문자열)
- 16진수 형태의 문자열(암호화된 문자열)을 그 숫자로 표현되는 바이트(이진 문자열)로 변환
- 예:
- UNHEX('ce19cb3fcf8b9cbbe99e6af3f3cbfdf2’)
→ ��?ϋ���j����� - 이진 문자열의 길이는 16진수 형태의 문자열의 길이의 절반
- UNHEX('ce19cb3fcf8b9cbbe99e6af3f3cbfdf2’)
▷ 날짜/시간 함수
- CURDATE(): 현재의 날짜
- CURDATE() → ‘2009-11-12’
- CURTIME(): 현재 시간
- CURTIME() → ‘17:30:25’
- NOW(): 현재의 날짜/시간
- NOW() → ‘2009-11-12 17:30:25’
- YEAR(date): 년도
- YEAR((‘2009-11-12’) → 2009
- MONTH(date): 월 DAY(date): 일
- MONTHNAME(date): 월 이름
- MONTHNAME(‘2009-11-12’) → ‘November’
- DAYNAME(date): 요일 이름
- DAYNAME(‘2009-11-12’) → ‘Thursday’
- DAYOFWEEK(date): 요일 인덱스
- DAYOFWEEK(‘2009-11-12’) → 5
(1:일, 2:월, …, 7:토)
- DAYOFWEEK(‘2009-11-12’) → 5
- WEEKOFYEAR(date): 1년 중 몇번째 주인가?(1~53)
- WEEKOFYEAR('2009-11-12‘) → 46
- DAYOFYEAR(date): 1년 중 몇번째 날인가?(1~366)
- LAST_DAY(date): 해당 월의 마지막 날짜
- LAST_DAY('2009-11-12') → ‘2009-11-30’
- HOUR(time): 시간 HOUR(‘10:05:03’) →
10- MINUTE(time): 분 SECOND(time): 초
- MAKEDATE(year, dayofyear): 주어진 연도
의 해당 일짜 생성- MAKEDATE(2009, 365) → ‘2009-12-31’
- MAKETIME(h, m, s): 시간 값 생성
- MAKETIME(14, 15, 30) → ‘14:15:30
- DATE_ADD(date, INTERVAL expr unit),
DATE_SUB(date, INTERVAL expr unit)- 날짜를 더하거나 뺀다
- DATE_ADD('2009-11-12 17:30:25‘, INTERVAL 1
DAY)
→ '2009-11-13 17:30:25‘ - DATE_ADD('2009-11-12 17:30:25‘, INTERVAL 1
HOUR)
→ '2009-11-12 18:30:25‘ - DATE_SUB('2009-11-12 17:30:25‘, INTERVAL 1
WEEK)
→ '2009-11-05 18:30:25‘
- DATEDIFF(expr1, expr2): 날짜 차이(expr1
- expr2)
- DATEDIFF(‘2009-11-10’, ‘2009-11-09’) → 1
- DATEDIFF(‘2009-11-10’, ‘2009-11-20’) → -10
▷ 변환 함수
SELECT 제목, 구입일자, CAST(구입일자 AS DATE) FROM 도서;- CAST(expr AS type)
- expr을 type으로 데이터 타입을 변환시킴
- CAST(‘2009-11-12’ AS DATETIME) → 2009-11-12 00:00:00
- CAST('2009-11-12 12:45:20' AS TIME) → 12:45:20
- CAST(0.123 AS CHAR(3)) → ‘0.1’
▷ 흐름 제어 함수
- IF(expr1, expr2, expr3)
- expr1이 참이면 expr2를, 아니면 expr3를 리턴
- IFNULL(expr1, expr2)
- eExpr1이 null이면, expr2를 리턴; null이 아니면, expr1을 리턴
▶ 비밀번호 칼럼
▷ 필요한 이유
- 육안으로 식별할 수 있는 문자열 타입으로
저장하면 안됨- 암호화 필요
- 사용자가 입력한 비밀번호 값(문자열)과 테이블에 저장되어 있는 비밀번호 칼럼의값이 일치하는지 확인 가능해야 함
- BINARY 타입 이용
▷ 과정
- 테이블 생성
- BINARY 타입으로 도메인 설정
- 비밀번호 삽입
- 사용자가 입력한 비밀번호(문자열)를 암호화하여 저장
- 문자열 → 암호화(16진수 문자열) → 이진 문
자열
- 비밀번호 비교
- 이진 문자열 간의 비교
▷ 테이블 생성
-
길이는 암호화 함수에 따라 달리 설정
- MD5: BINARY(16)
- SHA1: BINARY(20)
- SHA2: BINARY(28) ~ BINARY(64)
REATE TABLE 회원( 아이디 VARCHAR(30) NOT NULL, 비밀번호 BINARY(16) NOT NULL, 이름 VARCHAR(10) NOT NULL, PRIMARY KEY(아이디));
▷ 비밀번호 삽입
INSERT INTO 회원 VALUES
(‘abcd’, UNHEX(MD5(‘sku1234’)), ‘홍길동’);- 테이블 스키마에 맞춰 암호화 함수 사용
- MD5, SHA1, SHA2
- 이진 문자열로 변환하기 위해 UNHEX 함수
적용
▷ 비밀번호 일치 확인
- 아이디 ‘abcd’를 사용하는 사용자가 비밀번호
를 ‘xyz’로 입력한 경우
SELECT 아이디, 이름 FROM 회원
WHERE 아이디 = ‘abcd’ AND
비밀번호 = UNHEX(MD5(‘xyz’));기본 키는 하나밖에 존재하지 못하지만, 외래키는 여러개 존재가 가능하다.
따라서 외래키를 삭제할 때 이름을 추가해야한다.
DEFAULT NULL,// 기본값을 null로 설장한다는 의미
select 제목, 가격,가격-1000 from stdt106.도서;
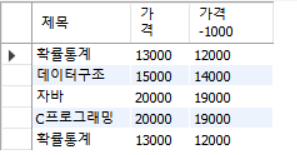
as를 사용하여 칼럼의 이름 별칭 붙여서 사용 가능
select 제목, 가격 as 원가, 가격-1000 as 할인가 from stdt106.도서;정렬
select * from 도서 order by 가격 desc, 제목;
가격을 기준으로 내린 차순으로 정렬하되 가격이 동일할 땐 제목을 기준으로 오름차순 정렬을 하고 싶을 때 위와같이 입력
검색결과 개수
select *from 도서 limit 3;
이를 응용
select *from 도서 order by 가격 desc limit 3;
페이징
4번째 행부터 시작해서 2번째 행을 뽑아내는 예시
select *from 도서 order by 가격 desc limit 3,2 ;
= 쓰면 완전히 똑같을 때만 검색이 됨
select * from 도서 where 제목 = '데이터';
따라서 부분 매칭을 하려고 할 땐 like 사용
select * from 도서 where 제목 like '데이터%';
제목의 문자열이 데이터로 사적허눈 모든 데이터를 검색하라.
프로라는 문자열이 어디있는지 모를 때 문자열 내에 이터라는 문자열이 있으면 검색
select * from 도서 where 제목 like '%데이터%';
앞에 두 문자가 있고 다섯 번째가 통이다, 그 다음 문자가 있을수도 없을수도 있다.
select * from 도서 where 제목 like '____조%';
▶ 기타 명령어
▷ DB 삭제 [DROP, DELETE]
- DROP은 폴더 자체를 삭제하고, DELETE 는 폴더의 내용을 삭제 한다.
형식
DROP DATABASE;
예를들어 "설정" 테이블에서 값이 "500m"인 행을 삭제하려면
DELETE FROM 설정
WHERE search_radius = '500m';▷ 수정 [UPDATE]
▷ 검색 [SELECT]
형식
SELECT 출력하고자하는열 FROM 테이블명 WHERE 조건;모든 열을 검색하고자 하는 경우 출력하고자 하는 열에 *을 사용한다.
SELECT * FROM 테이블명 WHERE 조건;예시
SELECT 번호,제목 FROM 도서;