DATABASE
DATABASE FUNCTION
- DATABASE FUNCTION
-
데이터 계산 수행
-
개별적 데이터 항목 수정
-
행의 그룹에 대해 결과 조작
-
출력을 위한 날짜와 숫자 형식 설정
-
열의 데이터 타입 변환
-
단일 행 함수
- 단일 행에서만 적용 가능하며 행별로 하나의 결과를 리턴
-
다중 행 함수
- 복수의 행을 조작하여 진행하는 함수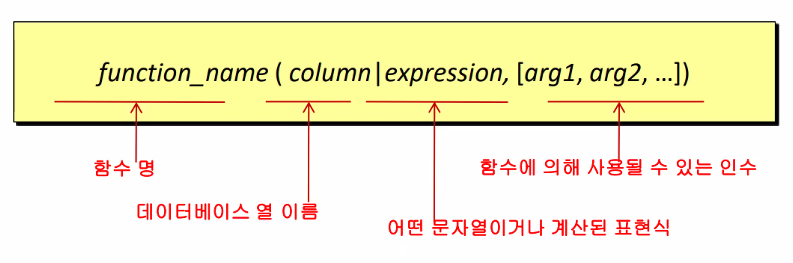
-
LOWER(), INITCAP(), UPPER()
- LOWER(), INITCAP(), UPPER()
-
소문자 변환, 첫 앞 글자만 대문자 변환, 대문자 변환
SELECT 'abcDEF', lower('abcDEF'), upper('abcDEF') FROM dual; /* dual이라는 테이블은 sys가 소유하는 오라클의 표준 테이블로서 오직 한 행에 한 컬럼만 담고 있는 dummy 테이블 일시적인 산술 연산이나 날짜 연산 등을 주로 사용 간단한 결과를 확인하기 위해서는 dual을 통해 확인 가능 */ SELECT last_name, lower(last_name), initcap(last_name), upper(last_name) FROM employees; SELECT last_name FROM employees WHERE lower(last_name) = 'austin'; --lower를 적용했을때의 조건의 값을 걸어서 실제 값을 조회 가능 --이걸로 대소문자에 관계 없이 값을 쉽게 조회할 수 있을듯
-
LENGTH(), INSTR()
- LENGTH(), INSTR()
-
LENGTH() : 문자의 길이를 출력
-
INSTR(문자, 찾고 싶은 문자) : 찾고 싶은 문자가 어디에 있는 지 출력해주며 없으면 0으로 나오고 1부터 시작
SELECT 'abcdef' AS ex, length('abcdef'), instr('abcdef', 'd') FROM dual; SELECT first_name, length(first_name), instr(first_name, 'c') FROM employees;
-
SUBSTR(), CONCAT()
- SUBSTR(), CONCAT()
-
SUBSTR(문자열, 시작 범위, 끝 범위) : 문자열 자르기
-
CONCAT(문자열, 문자열) : 문자열 합치기
SELECT 'abcdef' AS ex, substr('abcdef', 1, 4), concat('abcdef', 'ghi') FROM dual; SELECT first_name, substr(first_name, 1, 4), concat(first_name, last_name) AS 이름성 FROM employees;
-
LPAD(), RPAD()
- LPAD(), RPAD()
-
LPAD(문자열, 총 문자 개수, 채울 문자) : 좌측부터 지정 문자열로 채움)
-
RPAD(문자열, 총 문자 개수, 채울 문자) : 우측부터 지정 문자열로 채움)
SELECT lpad('abc', 10, '$$$') FROM dual; SELECT rpad('abc', 10, '$$$') FROM dual;
-
LTRIM(), RTRIM(), TRIM()
- LTRIM(), RTRIM(), TRIM()
-
공백 제거 함수
-
LTRIM(문자, 제거할문자), RTRIM(문자, 제거할문자) TRIM(문자, 제거할문자)
-
좌, 우, 양옆에 있는 특정 문자 제거
SELECT ltrim(' Lunch ', ' ') FROM dual; SELECT rtrim(' Lunch ', ' ') FROM dual;
-
REPLACE()
- REPLACE()
-
REPLACE(기준 문자열, 특정 문자, 바꿀 문자) 문자를 바꾸는 함수
SELECT replace('MY DREAM IS AS PRESIDENT', 'PRESIDENT', 'DOCTOR') FROM dual; SELECT replace('MY DREAM IS AS PRESIDENT', ' ', '') FROM dual; --공백제거 SELECT replace(replace('MY DREAM IS AS PRESIDENT', 'PRESIDENT', 'DOCTOR'), ' ', '') FROM dual; --president를 doctor로 변환한 것을 다시 replace함수를 사용해서 공백을 제거 SELECT replace(replace(concat('hello ', 'world!'), '!', '?'), ' ', '') FROM dual; --hello world!로 합치고 !를 ?로 변경하고 공백도 제거
-
NUMBER
- 숫자 함수
-
ROUND(), TRUNC(), ABS(), CEIL(), FLOOR(), MOD()
--ROUND(반올림, 반올림하고 싶은 위치) 원하는 반올림 위치를 매개값으로 지정 SELECT round(3.1254, 3), round(432.423, 0), round(45.923, - 1) FROM dual; --round의 함수에서 반올림하고 싶은 위치의 음수가 되면 정수자리로 올라감 --TRUNC(절사, 버리고 싶은 위치) 원하는 위치에서 값을 잘라냄 SELECT trunc(23.955, 2), trunc(23.955, 1), trunc(23.955, - 1) FROM dual; --ABS(절대값) SELECT abs(23.955), abs(- 23.955), abs(0) FROM dual; --CEIL(올림), FLOOR(내림) SELECT ceil(23.95), floor(23.955) FROM dual; --mod(나머지) SELECT 25 / 2, mod(25, 2) FROM dual;
-
DATE
- 날짜 함수
-
날짜를 이용하여 연산을 진행할 수 있음
--sysdate 시스템에 설정된 날짜를 출력해줌 SELECT sysdate FROM dual; --자세한 시간 출력 SELECT systimestamp FROM dual; --날짜도 연산이 가능 SELECT round(sysdate, 'month') FROM dual; --4월 22일에서 월을 기준으로 일이 22일이므로 반올림을 진행해서 5월 1일로 출력 --근속 연수를 구할 수 있음(올림 활용) SELECT first_name, ceil(sysdate - hire_date) FROM employees; --근속연수를 일, 주, 년으로 구할 수 있음(올림 활용) SELECT first_name, ceil(sysdate - hire_date) AS day, ceil((sysdate - hire_date) / 7) AS week, ceil((sysdate - hire_date) / 365) AS year FROM employees;
-
CASTING
- TO_CHAR()
-
문자로 변경하는 함수
-
TO_CHAR(값, 형식)
SELECT to_char(sysdate) FROM dual; SELECT to_char(sysdate, 'dd/mm/yy') FROM dual; SELECT to_char(sysdate, 'YYYY-MM-DD HH:MI:SS') FROM dual; SELECT to_char(sysdate, 'YY-MM-DD HH24:MI:ss') FROM dual; --TO_CHAR를 통해서 날짜를 문자열로 변환하고 내가 원하는 형식대로 바꿀 수 있음 SELECT first_name, to_char(hire_date, 'YY"년"-MM"월"-DD"일"') FROM employees; --TO_CHAR()에 들어가는 서식문자에 ""로 묶어 값을 삽입할 수 있음 --숫자를 문자로 변환 SELECT to_char(3094, '99999') FROM dual; --숫자를 자리수(9~~)에 맞게 문자열로 변환 SELECT to_char(3094.34, '99999.999') FROM dual; --실수도 가능 SELECT to_char(3094, '9,999') FROM dual; --원하는 방식대로 변경 가능 SELECT to_char(salary, 'L99,999') AS salary FROM employees;
-
- TO_NUMBER()
-
숫자로 변경하는 함수
-
TO_NUMBER(값, 형식)
SELECT '2000' + 2000 FROM dual; -- 자동 형 변환 --자동으로 형변환을 진행하여 4000이 출력 SELECT to_number('2000') + 2000 FROM dual; -- 명시적 형 변환 SELECT to_number('$3,300', '$9,999') + 2000 FROM dual; --숫자로 변환할 수 없는 문자는 형식에 포함하여 넣어주면 숫자로 변환 가능
-
- TO_DATE()
-
날짜로 변경하는 함수
-
TO_DATE(값, 형식)
SELECT to_date('2021-11-25') FROM dual; --DATE는 연산이 가능함으로 문자를 날짜로 변환해서 연산을 진행 가능 SELECT ceil(sysdate - to_date('2021-11-25')) FROM dual; --문자열로 구성된 날짜를 원하는 DATE형식으로 변환가능 --주어진 문자열을 모두 변환해야 함 SELECT TO_DATE('2020/12/25', 'YY-MM-DD') FROM dual; SELECT TO_DATE('2021-03-31 12:23', 'YYYY-MM-DD HH:MI') FROM dual; /* xxxx년 xx월 xx일 문자열 형식으로 변환해 보세요. 조회 컬럼명은 dateInfo로 하겠습니다. */ SELECT TO_CHAR(TO_DATE('20050102', 'YYYY MM DD'), 'YYYY"년" MM"일" DD"월"') AS datainfo FROM dual;
-
- NVL(), NVL2()
-
NULL 변경 함수
-
NVL(컬럼, 변환할 값)
-
NVL2(컬럼, null이 아닐 경우 값, null일 경우 값)
SELECT first_name, nvl(commission_pct, 0) FROM employees; --commission_pct에 있는 null값을 0으로 변환 SELECT first_name, nvl(to_char(commission_pct), '뽀나스 없지롱') FROM employees; -- NVL()는 만약 컬럼의 값이 숫자면 변환할 값도 숫자이고 컬럼의 값이 문자면 변환 값도 문자로 해줘야함 SELECT first_name, nvl2(to_char(commission_pct), '올~ 뽀나스 존재', '뽀나스 없지롱~') FROM employees; SELECT first_name, commission_pct, nvl2(commission_pct, salary +(salary * commission_pct), salary) AS real_salary FROM employees ORDER BY REAL_SALARY DESC; --commission_pct가 null이 아닌 사람은 commission을 포함한 salary를 보여주고 null이면 그냥 salary보여줌
-
DECODE()
- DECODE()
-
조건에 맞는 값이 있으면 특정 값 출력
-
DECODE(컬럼 혹은 표현식, 항목1, 결과1, 항목2, 결과2, ... default)
SELECT DECODE('A', 'A', 'A입니다.', 'B', 'B입니다', '모르겠어요') FROM dual; SELECT job_id, salary, decode(job_id, 'IT_PROG', salary * 1.1, 'FI_MGR', salary * 1.2, 'AD_VP', salary * 1.3, salary) AS result FROM employees;
-
- CASE()
-
조건에 맞는 값이 있으면 특정 값 출력
-
CASE, WHEN, THEN, END
SELECT first_name, job_id, salary, ( CASE job_id WHEN 'IT_PROG' THEN salary * 1.1 WHEN 'FI_MGR' THEN salary * 1.2 WHEN 'FI_ACCOUNT' THEN salary * 1.3 WHEN 'AD_VP' THEN salary * 1.4 ELSE salary END ) AS result FROM employees ORDER BY result DESC;
-
DATASET
- Union, Union all, Intersect, Minus
-
집합 연산자를 통해 2개의 조회 쿼리에 연산을 진행
-
UNION(합집합 중복X), UNION ALL(합집합 중복O), MINUS(차집합), INTERSECT(교집합)
-
비교하고자 하는 table의 위, 아래 column 개수가 정확하게 일치
SELECT employee_id, first_name FROM employees WHERE hire_date LIKE '04%' UNION SELECT employee_id, first_name FROM employees WHERE department_id = 20; --두개의 조회 쿼리를 합쳐서 조회 결과를 출력해줌 하지만 UNION은 중복된 결과는 제외함 SELECT employee_id, first_name FROM employees WHERE hire_date LIKE '04%' UNION ALL SELECT employee_id, first_name FROM employees WHERE department_id = 20; --중복 허용 SELECT employee_id, first_name FROM employees WHERE hire_date LIKE '04%' INTERSECT SELECT employee_id, first_name FROM employees WHERE department_id = 20; --각 조회 쿼리 결과에서 공통으로 겹치는 부분을 출력 SELECT employee_id, first_name FROM employees WHERE hire_date LIKE '04%' MINUS SELECT employee_id, first_name FROM employees WHERE department_id = 20; --위의 조회값을 기준으로 교집합 내용은 삭제
-
- GROUP BY
-
특정 컬럼 값을 그룹화
-
그룹 함수는 일반 컬럼과 동시에 출력할 수 없고 GROUP BY를 사용해야 조회 가능
-
그룹화 할 기준이 있어야함.
-
AVG(), MAX(), MIN(), SUM(), COUNT()
-
HAVING : 그룹화한 값에 조건을 걸어줄 수 있음
-
쿼리 진행 순서 : FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
-
쿼리 진행 순서로 인해서 SELECT에서 적용한 ALIAS를 사용할 수 없음
SELECT COUNT(*) FROM employees WHERE job_id = 'IT_PROG'; SELECT job_id, round(AVG(salary), 0) AS 평균급여, round(MAX(salary), 0), round(MIN(salary), 0), round(SUM(salary), 0), COUNT(salary) FROM employees WHERE salary >= 5000 GROUP BY job_id ORDER BY 평균급여 DESC; SELECT COUNT(*) FROM employees; SELECT COUNT(first_name) FROM employees; SELECT COUNT(commission_pct) FROM employees; /* commission_pct는 null값이 있는 컬럼이므로 'null은 값이 비어있다'라는 뜻이므로 count하지 않음 */ SELECT COUNT(commission_pct) FROM employees WHERE commission_pct IS NOT NULL; SELECT department_id, trunc(AVG(salary)) AS 평균급여 FROM employees GROUP BY department_id ORDER BY 평균급여 DESC; /*select에 그룹함수를 사용한 컬럼이 아닌 일반 컬럼이 있으면 GROUP BY 해야 조회 가능 즉, 그룹함수는 일반 컬럼과 동시에 그냥 출력할 수 없음 */ SELECT job_id, department_id, trunc(AVG(salary)) FROM employees GROUP BY department_id, job_id; --그룹함수를 사용할 때 같이 일반 컬럼을 1개 이상 쓰면 일반 컬럼은 GROUP BY에 전부 써야함 --HAVING SELECT department_id, SUM(salary) FROM employees GROUP BY department_id HAVING SUM(salary) > 100000; /* WHERE절에 group함수를 쓰면 GROUPBY보다 먼저 연산을 수행하기 때문에 에러가 남 그렇기 때문에 HAVING을 써서 그룹화 이후 조건을 걸어줌 */ SELECT job_id, COUNT(job_id), count(*) FROM employees GROUP BY job_id HAVING COUNT(job_id) >= 20; --job별 근무하는 직원 수가 20명 이상 일때 조회 -- 문제 부서 아이디가 50이상인 것들을 그룹화 시키고, 그룹 월급 평균 중 5000이상만 조회 SELECT department_id, AVG(salary) FROM employees WHERE department_id >= 50 GROUP BY department_id HAVING AVG(salary) >= 5000 ORDER BY department_id ASC;
-
Practice
- Exercise1
/* 문제 1 EMPLOYEES 테이블에서 이름, 입사일자 컬럼을 변경해서 이름순으로 오름차순 출력합니다. 조건1) 이름 컬럼은 first_name, last_name을 붙여서 출력합니다. 조건2) 입사일자 컬럼은 xx/xx/xx로 저장되어 있습니다. xxxxxx형태로 변경해서 출력합니다. */ SELECT first_name || ' ' || last_name AS 이름, replace(hire_date, '/', '') AS 입사일자 FROM employees ORDER BY 이름 ASC; SELECT concat(first_name, last_name) AS 이름, replace(hire_date, '/', '') AS 입사일자 FROM employees ORDER BY 이름 ASC; /* 문제 2 EMPLOYEES 테이블에서 phone_number 컬럼은 ###.###.###형태로 저장되어 있다 여기서 처음 세자리 숫자 대신 서울 지역번호(02)를 붙여 전화 번호를 출력하도록 쿼리를 작성하세요. */ SELECT replace(phone_number, substr(phone_number, 1, 3), '(02)') AS 전화번호 FROM employees; SELECT concat('(02)', substr(phone_number, 4, length(phone_number))) AS phone_number FROM employees; /* 문제 3 EMPLOYEES 테이블에서 JOB_ID가 it_prog인 사원의 이름(first_name)과 급여(salary)를 출력하세요 조건1. 비교하기 위한 값은 소문자로 입력 조건2. 이름은 앞 3문자까지 출력하고 나머지는 *로 출력 이열의 별칭은 name 조건3. 급여는 전체 10자리로 출력하되 나머지 자리는 *로 출력합니다. 이열의 열 별칭은 salary입니다 */ SELECT rpad(substr(first_name, 1, 3), length(first_name), '*') AS name, lpad(salary, 10, '*') AS salary FROM employees WHERE lower(job_id) = 'it_prog'; - Exercise2
/* 문제1 현재일자를 기준으로 EMPLOYEE테이블의 입사일자를 참조해서 근속년수가 15년 인상인 사원을 다음과 같은 형태의 결과를 출력하도록 쿼리를 작성하세요. 조건 1) 근속년수가 높은 사원 순서대로 결과가 나오도록 합니다. */ SELECT employee_id AS 사원번호, concat(first_name, last_name) AS 사원명, hire_date AS 입사일자, trunc((sysdate - hire_date) / 365) AS 근속년수 FROM employees WHERE ( sysdate - hire_date ) / 365 >= 15 ORDER BY 근속년수 DESC; --WHERE에 ALISA명을 적으면 조회가 안됨 --왜냐하면 SQL의 순서가 FROM -> WHERE로 진행되기 때문에 SELECT에서 ALISA한 것을 인식하지 못함 --ORDER BY에서 먹히는 이유는 맨 마지막에 실행되기 때문(SELECT이후) /* 문제2 EMPLOYEE 테이블의 manager_id 컬럼을 확인하여 first_name, manager_id, 직급을 출력합니다. department_id가 50인 사람들을 대상으로만 조회합니다. */ SELECT first_name, manager_id, ( CASE manager_id WHEN 100 THEN '사원' WHEN 120 THEN '주임' WHEN 121 THEN '대리' WHEN 122 THEN '과장' ELSE '임원' END ) AS 직급 FROM employees WHERE department_id = 50; SELECT first_name, manager_id, decode(manager_id, 100, '사원', 120, '주임', 121, '대리', 122, '과장', '임원') AS 직급 FROM employees WHERE department_id = 50;
