Data Engineering
Resilient Distributed Dataset
-
RDD Transformation & Action
-
Transformation
- 결과값으로 새로운 RDD를 반환
- Lazy Execution(지연 실행)
- Narrow와 Wide가 존재
- output으로 RDD를 반환
- map(), flatMap(), filter(), distinct(), reduceByKey(), groupByKey() 등
-
Actions
- 결과값을 연산하여 출력하거나 저장
- list나 Object 결과값 출력
- Eager Execution(즉시 실행)
- collect(), count(), countByValue(), take(), top() 등
-
-
Narrow Transformations
- 1:1 변환
- filter(), map(), flatMap(), sample(), union()
- 1열을 조작하기 위해 다른 열/ 파티션의 데이터를 쓸 필요가 없음
- 정렬이 필요하지 않은 경우
- 즉 한 열에서 다른 열로 변환될 수 있는 경우에만 사용
-
Wide Transformation
- Shuffling
- Intersection and join, distinct, cartesian, reduceByKey(), groupByKey()
- 아웃풋 RDD의 파티션에 다른 파티션의 데이터가 들어갈 수 있음
- 데이터가 다른 파티션도 왔다 갔다 하기 때문에 많은 리소스 요구
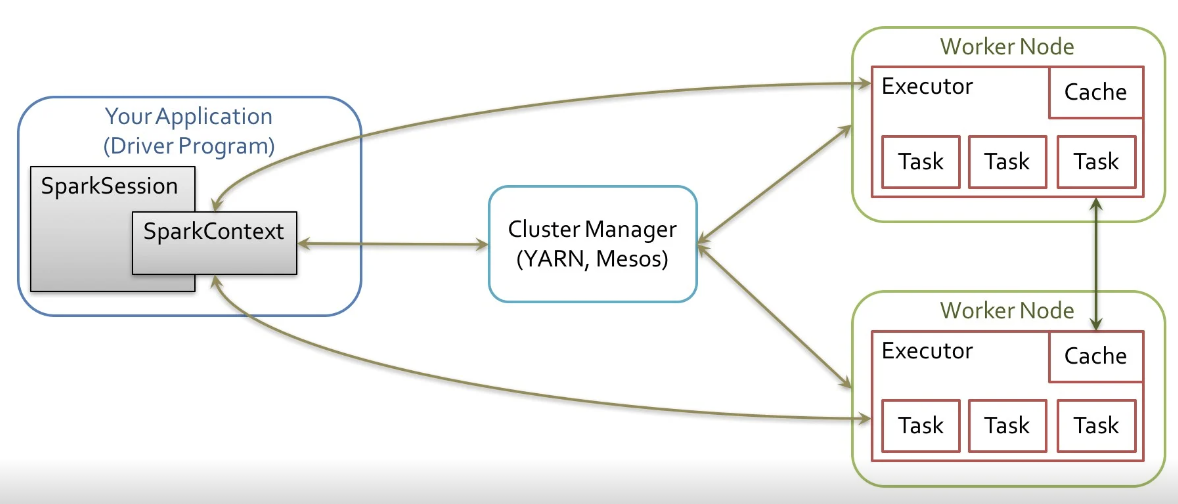
Spark Topology
-
Cluster Topology
-
Spark Topology
- Spark는 Master와 Worker로 나뉘어져 있음
-
Spark
-
Spark는 항상 데이터가 여러 곳에 분산되어 있음
-
Spark는 같은 연산이어도 여러 노드에 걸쳐서 실행됨
-
Driver Program(노드)은 개발자나 유저가 프로그램과 상호작용을 할 수 있는 프로그램이고 실제 작업은 Worker Node에서 실행
-
Driver Program과 Worker Node는 Cluster Manager를 통해 communication 진행
-
Cluster Manager는 수행되는 작업의 스케쥴링과 자원 관리를 수행 (yaml 등)
-
-
실행 과정
1. Driver Program이 SparkContext를 생성
2. Spark Application 만들어짐
3. SparkContext가 Cluster Manager에 연결
4.Cluster Manager는 자원 할당
5. Cluster Manager가 Cluster에 있는 노드들의 Executor를 수집하고 Executor는 연산을 수행하고 데이터 저장
6. SparkContext가 Executor에게 실행할 task 전송
7. 전송된 Task의 결과값을 DriverProgram에 보냄
-

안녕하세요! 공부한 내용을 기록하는 공간입니다.