1. 개요
-
그래프 내의 모든 vertice를 연결하는 sub graph 가운데, edge의 weight 총합이 가장 작은 경우를 의미한다.
-
Cycle을 이루면 안되기 때문에 항상 tree의 형태를 가진다.
-
일반적인 spanning tree는 DFS, BFS로도 구할 수 있으나, MST는 다른 방법이 필요하다.
2. Greedy paradigm
-
항상 있는 일은 아니지만, 많은 경우 어떤 문제를 해결하려 할 때 대부분은 작은 문제에서 시작하여 차근차근 해결해나가다가 큰 문제의 해결에 이르는 경우들이 있다.
-
특정 알고리즘이 지엽적인 문제를 만났을 때, 그 지엽적인 문제에서 가장 효율적인 해결을 시도함을 반복한다면 greedy paradigm에 따른 greedy algorithm이라고 할 수 있다.
-
즉, 매번 선택의 갈림길에서 그 시점에서 최적의 선택을 하는 것이라고 볼 수 있다.
-
이하에서 다룰 Prim's algorithm이나 이전에 다룬 다익스트라 알고리즘을 대표적인 예시로 들 수 있다.
-
'최적의 해를 구한다'라는 목적에 입각하여 볼 때, greedy paradigm은 가장 쉽게 떠올릴 수 있는 해결책이다.
-
하지만 greedy paradigm은 지엽적인 수준에서는 최적해를 구하지만, 전체의 수준에서는 최적해를 구하지 못하는 경우가 종종 발생한다.
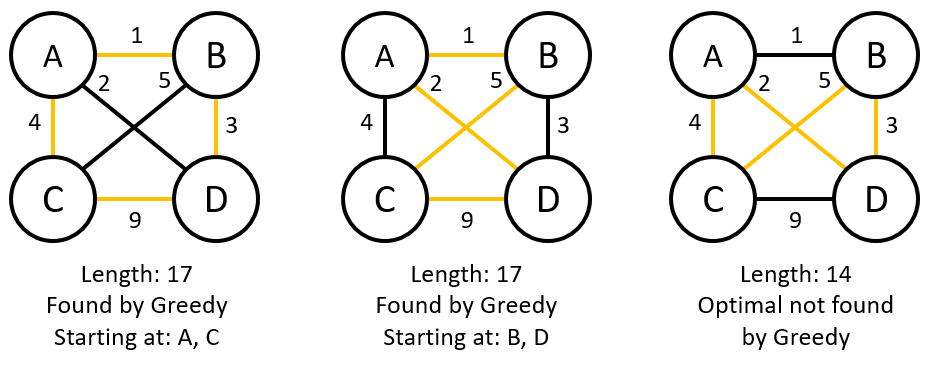
-
이상의 그림은 ABCD를 최적으로 순환 가능한 방법을 구한 것이다. 즉, 모든 도시를 들르면서, 최초의 도시로 돌아오는 최적해를 구해야 하는 것이다.
-
노란색 edge가 실제 spanning tree이다. 첫번째와 두번째 그림은 각각 greedy 알고리즘을 사용하여 A/C, B/D에서 출발하였을 때 도출하는 해답이고, 세번째 그림은 실제 해답이다. 첫번째와 두번째는 총 weight가 17이지만, 세번째는 14이다. 유감스럽게도, 순환을 목적으로하자 greedy는 바로 한계를 도출한다.
3. Prim's algorithm
-
일전에 다룬 다익스트라 알고리즘과 유사한 방법으로 MST를 구하는 알고리즘이다.
-
다익스트라 알고리즘에서 edge는 누적거리이지만, Prim에서는 누적하지 않는다는 차이점이 있을 뿐, 그 외는 거의 동일하다.
4. Kruskal's algorithm
-
MST를 구하는 다른 알고리즘으로, 이 또한 greedy paradigm을 이용한다.
-
Vertice를 따라 이동하는 Prim과는 다르게, 모든 edge를 PQ에 넣고, PQ에서 뽑혀나오는 최소 edge들을 이용하여 MST를 구축한다.
-
이때, PQ에서 나오는 최소 edge를 이용하는 경우, 경우에 따라 cycle을 이루는 경우가 있는데, 이를 배제해야 MST를 구할 수 있다.
-
이를 배제하기 위한 방법이 tree를 이용한 DisjointSet 구현이다.
-
모든 vertice를 자기 자신을 root로 하는 node로 재편하여 Disjointset에 넣는다.
-
PQ에서 edge가 뽑혀져 나오면, edge를 통해 연결되어있는 두 vertice의 root 값이 같은지, 다른지 판별한다. 이때, 같다면 edge를 ST에 더했을 경우 cycle을 이룬다는 의미이므로, 추가하지 않는다.
-
root가 다르다면 ST에 edge를 추가한다. 대신, DisjointSet에 존재하는 vertice를 어느 한 쪽을 root로 하여 묶어주어야 한다. 예를 들어, 최초의 edge가 C, D를 잇는다면, DisjointSet에는 C혹은 D를 root로 하도록 둘을 이어주어야 한다.
https://learning.edx.org/course/course-v1:GTx+CS1332xIV+2T2020/home
이상의 내용은 edx 플랫폼을 통해 GTx에서 제공하는 Data Structures & Algorithms 강의의 내용을 개인적으로 정리한 것입니다. 그렇기 때문에, 부정확한 내용 혹은 잘못 이해하고 있는 내용이 있을 수 있으니 양해 부탁드립니다.
