파일 시스템 (File System)
저장 장치에서 데이터를 관리하고 조직화하는 체계로, 운영체제가 파일을 생성, 읽기, 쓰기, 삭제 등의 작업을 할 수 있도록 지원
데이터가 파일 단위로 저장되고, 디렉토리를 통해 계층적으로 관리됨
파일
데이터의 집합, 저장 장치에 이름과 속성을 가지고 저장되는 단위
사용자는 파일을 통해 데이터를 저장하거나 읽을 수 있음
구성요소: 파일 이름, 데이터, 속성
파일 속성
파일에 대한 메타데이터, 파일의 상태와 동작 방식을 정의하는 정보
파일 이름, 크기, 유형, 위치, 권한, 생성/수정 날짜, 소유자 등의 속성을 지님
디렉토리
파일 및 디렉토리를 포함하는 구조, 파일을 체계적으로 관리하기 위한 공간
파일 그룹화로 파일을 논리적으로 정리하거나, 계층적 구조를 제공하고, 파일을 탐색할 수 있다.
파티션
저장 장치를 논리적으로 나눈 영역으로, 각 파티션에 파일 시스템을 생성하여 데이터를 저장
하나의 디스크를 여러 파티션으로 나눌 수 있음
운영체제, 사용자 데이터, 백업 등을 분리하여 관리할 수 있다.
파일 보호
파일에 저장된 데이터를 무단 접근, 수정, 삭제로부터 보호하기 위한 메커니즘
파일의 경우 여러 사용자가 사용할 수 있기 때문에 각 파일에 대해 누구에게 어떤 권한을 허용할 것인가가 필요
필요성
- 데이터 무결성 유지
파일이 구너한 없는 사용자에 의해 수정/삭제되는 것을 방지 - 정보 기밀성 보장
중요한 정보가 권한이 없는 사람에게 노출되지 않도록 보호
파일 권한 설정 방법
Access Control Matrix
사용자와 파일 간의 권한(Permissions)를 정의한 행렬 구조
사용자 및 파일 수가 많아질수록 행렬 크기가 커져 관리가 어려워짐
Grouping
사용자를 소유자(Owner), 그룹(Group), 기타(Other)로 구분
각 파일에서 세 그룹에 대한 권한을 설정 (그룹마다 3비트로 총 9비트로 표현)
r: 읽기, w: 쓰기, x: 실행
- Owner: rwx (읽기, 쓰기, 실행 가능)
- Group: rw- (읽기, 쓰기 가능)
- Other: r-x (읽기, 실행 가능)
Password
파일마다 비밀번호를 설정하고, 비밀번호를 아는 사람만 접근 가능
파일이 많아지면 비밀번호 관리가 힘들다는 단점이 있음
파일 할당 방식
연속 할당 (Continuous Allocation)
파일의 데이터를 연속된 블록에 저장
시작 블록 번호와 파일 크기를 기반으로 데이터의 저장 위치를 관리한다.
초기 파일 시스템에서 사용되었음
장점
- 빠른 접근 속도: 연속된 블록에 저장되어 랜덤 및 순차 접근 모두 빠름
- 구현 간단: 시작 위치와 크기만 알면 접근 가능
단점
- 외부 단편화: 파일 삭제 후 남는 공간이 사용되지 못하는 문제
- 파일 크기 확장 어려움: 기존 연속 블록 뒤에 여유 공간이 없으면 확장 불가
연결 할당 (Linked Allocation)
파일의 데이터를 임의의 빈 블록에 저장하고, 각 블록이 다음 블록을 가리키는 포인터를 포함. 포인터를 통해 파일의 데이터를 연결
장점
- 외부 단편화 문제 해결: 연속된ㄴ 공간이 필요하지 않음
- 파일 크기 확장 요이: 새로운 블록을 추가로 연결하면 됨
단점
- 랜덤 접근 속도 느림: 파일의 특정 위치에 접근하려면 처음 블록부터 포인터를 따라가야 함
- 포인터 오버헤드: 각 블록에 포인터 공간이 추가로 필요
색인 할당 (Indexed Allocation)
파일의 모든 블록 번호를 색인 블록(Index Block)에 저장
색인 블록은 파일 데이터를 가리키는 블록 번호의 리스트를 포함
Unix/Linux에서 쓰이는 방식
장점
- 랜덤 접근 속도 빠름: 색인 블록에서 블록 번호를 바로 확인 가능
- 외부 단편화 문제 없음: 데이터는 임의의 빈 블록에 저장
단점
- 색인 블록 오버헤드: 색인 블록을 위한 추가 저장 공간 필요
- 큰 파일의 색인 제한: 색인 블록 크기가 고정적이면 큰 파일 관리가 어려움
디스크 관리
하드 디스크의 데이터 구성 요소
데이터 구조
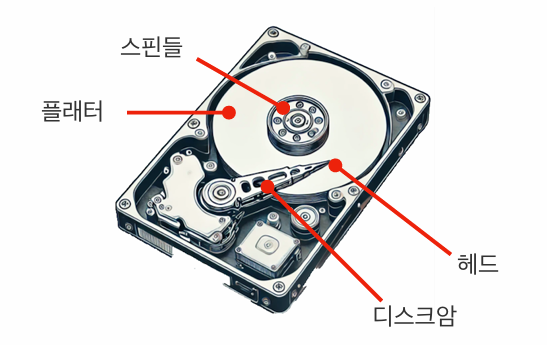
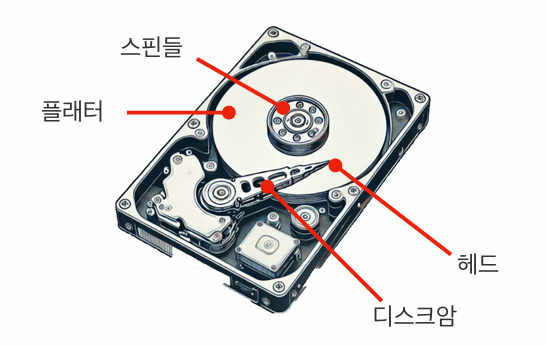
- 트랙(Track): 플래터 표면에 도넛 모양으로 나뉜 데이터 저장 구역
- 섹터(Sector): 트랙을 더 작은 데이터 블록으로 나눈 구역 -> 데이터는 섹터 단위로 읽거나 써짐
- 실린더(Cylinder): 층층이 쌓인 플래터에서 걸쳐 동일한 트랙 번호를 연결한 3차원적인 구조
데이터 접근 시간 = 탐색 시간 + 회전 지연 시간 + 데이터 전송 시간
- 탐색 시간: 디스크 암을 움직여 특정 트랙으로 헤더를 이동시키는 시간
- 회전 지연 시간: 디스크가 회전하여 헤더가 읽기/쓰기 대상이 되는 섹터 위에 위치하게 되는 시간
- 데이터 전송 시간: 읽기/쓰기 헤드가 데이터를 실제로 읽거나 쓰는데 걸리는 시간
데이터 접근 시간 최적화
- 상대적으로 가장 길로 통제 가능한 탐색 시간을 줄이는 것이 핵심 (암의 움직임 최소화)
- 가능한 동일한 실린더에 데이터를 적재하여 탐색 시간을 줄임
- 연속적으로 데이터에 접근할 때 적절한 스케줄링 기법을 사용하여 탐색 시간을 최소화
디스크 스케줄링 기법
탐색 시간을 최소화하는 것이 핵심
I/O 요청을 처리하기 위해 어떤 순서로 트랙에 접근할지를 결정하는 알고리즘
FCFS (First Come First Serve)
요청 순서대로 처리
장점: 구현이 간단
단점: 헤드 이동 거리가 길어질 수 있음 -> 비효율적
SSTF (Shortest Seek Time First)
현재 헤드 위치에서 가장 가까운 요청을 먼저 처리
장점: 헤드 이동 최소화
단점: 기아(Starvation) 가능성 (가까운 요청만 처리, 먼 요청은 무한 대기)
SCAN (Elevator Algorithm)
디스크 헤드가 한쪽 끝으로 이동하며 요청을 처리한 뒤, 방향을 바꿔 반대쪽 끝으로 이동하며 처리
장점: 헤드 이동이 균형 있게 이루어짐
단점: 끝에 있는 요청은 대기 시간이 길어질 수 있음
C-SCAN (Circular SCAN)
SCAN과 비슷하지만, 한쪽 끝에 도달하면 반대쪽 끝으로 바로 이동해 처리
장점: 요청 대기 시간이 균등해짐
단점: 끝으로 이동하는 동안 낭비가 발생
LOOK
SCAN과 유사하지만, 끝까지 가지 않고 요청이 있는 범위까지만 이동
장점: 불필요한 헤드 이동 감소
단점: 요청 분포에 따라 성능 차이
C-LOOK
C-SCAN과 유사하지만, 요청이 있는 범위까지만 이동한 뒤 반대쪽 끝으로 이동
장점: 헤드 이동이 최소화되고, 대기 시간 균등
