📌 Amazon EMR이란?

- *Amazon EMR (Elastic MapReduce)는 AWS에서 제공하는 클라우드 기반의 분산 빅데이터 처리 서비스이다. Apache Hadoop, Spark, Hive, HBase 등의 오픈소스 빅데이터 프레임워크를 손쉽게 활용해 페타바이트 규모의 데이터를 빠르고 효율적으로 처리**할 수 있도록 지원한다.


"EMR의 'MapReduce'는 Google에서 개발한 분산처리 기술에서 유래되었다."
📊 사용 사례
- 고객 구매 기록 분석 (e.g. Amazon)
- 실시간 교통 데이터 처리 (e.g. Uber)
- 로그 및 이벤트 분석
- 머신러닝 데이터 전처리 등
데이터 양이 단일 서버로 감당할 수 없는 수준일 때, EMR의 분산 처리 성능이 필요하다.
🏗️ EMR의 구조
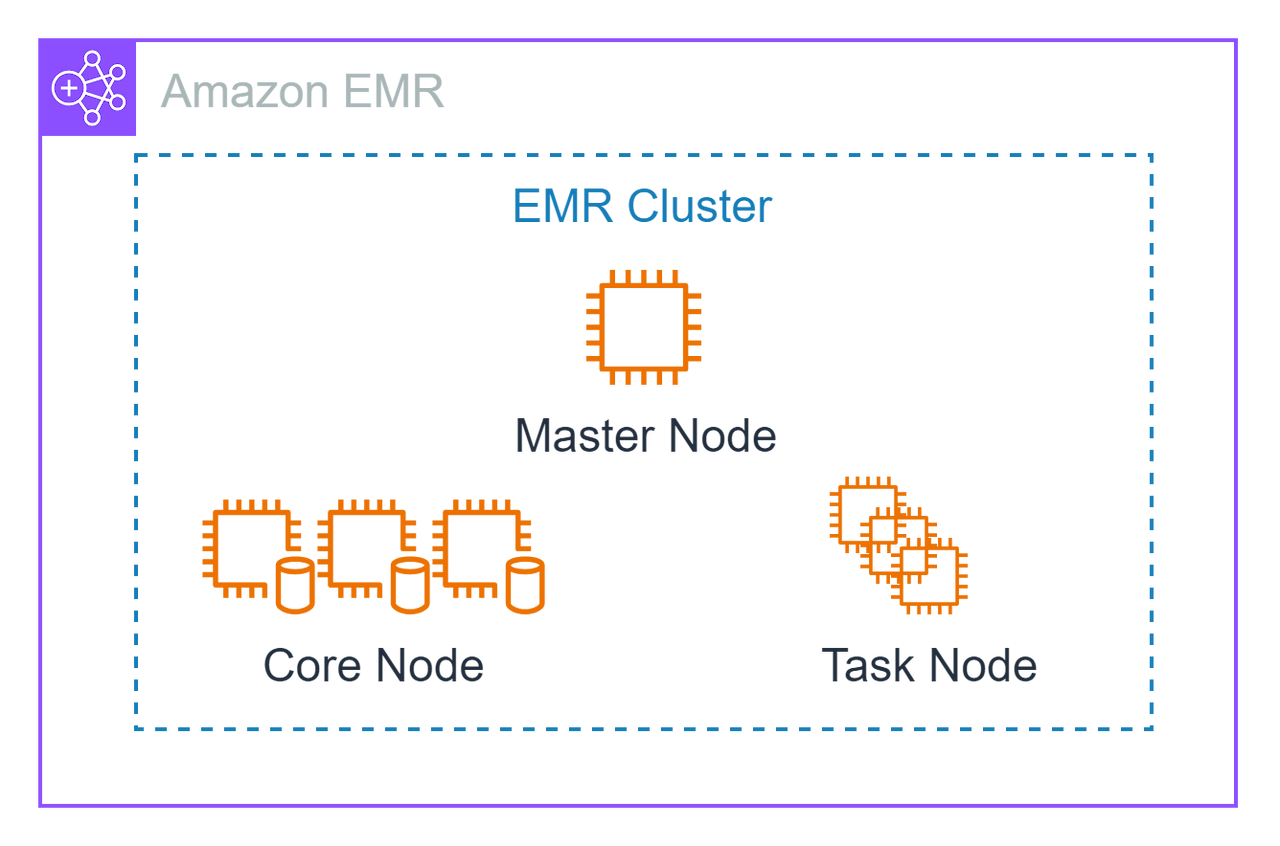
EMR 클러스터는 EC2 인스턴스를 기반으로 다음 3가지 노드로 구성된다:
| 노드 종류 | 역할 |
|---|---|
| Master Node | 클러스터 제어 및 작업 스케줄링 역할 |
| Core Node | 데이터 연산 및 HDFS 저장소 기능 수행 |
| Task Node (선택사항) | 연산 전용, 저장소는 없음 (즉시 확장 가능) |
코어/태스크 노드는 자동 또는 수동 스케일링이 가능하다.
🗂️ EMR의 파일 시스템: HDFS vs EMRFS
| 파일 시스템 | 설명 |
|---|---|
| HDFS (Hadoop Distributed File System) | 클러스터 내부 노드에 저장. 클러스터 종료 시 데이터 소실 |
| EMRFS (EMR File System) | Amazon S3를 백엔드 스토리지로 사용. 클러스터 종료 후에도 데이터 유지 가능 |
대부분의 실무에서는 EMRFS + S3 조합이 권장된다. S3의 버전 관리, 암호화, 내구성도 보장된다.
⚙️ 주요 특징 요약
- 분산 처리 기반의 빅데이터 플랫폼 (Hadoop, Spark 등)
- 다양한 오픈소스 프레임워크 지원
- EC2 인스턴스를 통한 유연한 스케일링
- Amazon S3와 통합하여 안전한 데이터 보관 가능
- 분석, 로그 처리, 기계학습 등 다양한 워크로드 지원
🧠 시험 포인트 (SAA-C03)
Q. Amazon EMR 클러스터에서 처리한 결과를 S3에 저장할 때 사용하는 기능은?
- A. EMRFS ✅
- 오답: EBS, EFS, HDFS (데이터 보존 불가 or 목적 부적합)
✅ 마무리 정리
| 항목 | 내용 |
|---|---|
| 핵심 개념 | 클라우드 기반 빅데이터 분석 플랫폼 |
| 분산 처리 | 다수의 노드로 데이터 병렬 처리 |
| 저장 방식 | HDFS (임시) / EMRFS (지속) + S3 연동 |
| 활용 사례 | 대규모 로그 분석, ML 전처리, 실시간 처리 |
| 시험 포인트 | EMRFS, 클러스터 노드 구조, S3 연계 |

Backend Developer / Cloud Engineer