메모리 가상화
메모리 주소
초기에는 프로그램을 실제 메모리에 직접 올려서 사용, 하지만 컴퓨터는 time sharing, multiprogramming을 하기 때문에 이보다 발전된 방법이 필요하다!
메모리 가상화 : 실제 메모리는 하나지만,OS는 프로세스에게 프로세스가 마치 자신만의 메모리를 갖고 있는 것 같은 illusion을 준다.
OS는 메모리를 추상화해서 프로세스들에게 배분한다. address space로 메모리를 추상화!!
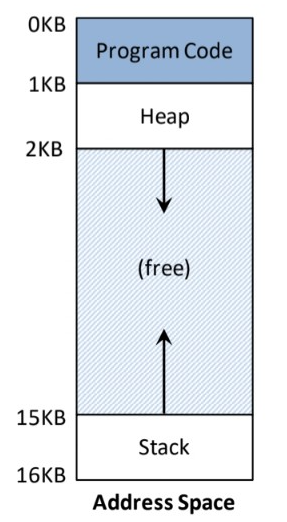
주소 공간에 할당된 주소가 실제 메모리의 주소가 아니다!
주소 공간의 주소를 OS가 변환하여 실제 메로리 주소로 바꾼 후 사용한다. -> address translation
주소 변환
OS는 프로그램이 자신에게 할당된 메모리에만 접근하도록 제어한다!
Virtual memory address -> Physical memory address
Dynamic Relocation
base 레지스터 ,bounds 레지스터 를 활용하여 Virtual Address -> Physical Address
실제 메모리 주소 = 가상 메모리 주소 + base
bounds 레지스터는 bounds보다 큰 가상 메모리 주소를 변환하려고 하면 오류를 발생시킨다!
MMU : 주소 변환을 돕는 프로세서 부분
문제점 : 주소 공간을 통째로 실제 메모리에 매핑하다 보니 heap과 stack 사이의 빈 공간이 낭비된다!! 실제 64bit 리눅스에서는 128TB 주소 공간을 할당하기 때문에 실제 메모리에 매핑하기도 곤란하다.
Segmentation
CPU의 MMU에 base 레지스터, bounds 레지스터가 하나만 존재하는 것이 아니라 base 레지스터와 bounds 레지스터가 쌍으로 segment(code, heap, stack)를 표현한다!
code, stack, heap 별로 물리 메모리로 매핑
=> stack과 heap 사이의 공간 낭비 x
=> 사용하는 메모리만 할당
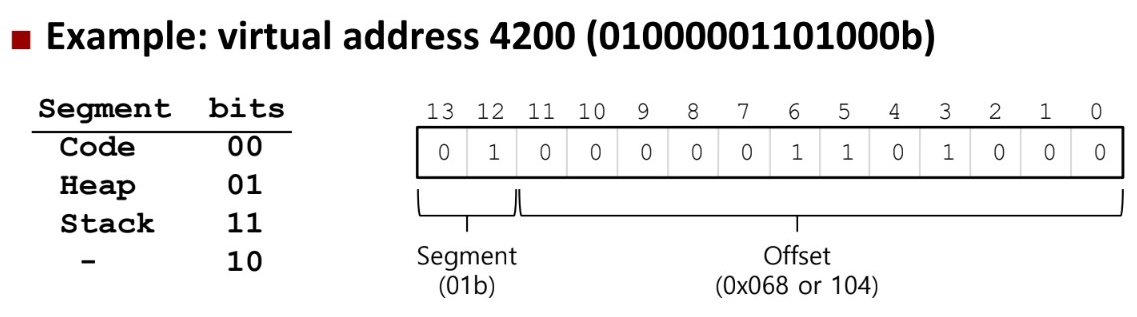
제일 앞에 있는 2bit로 segment를 판별한다! -> segment table에서 base를 가져옴
-> offset + base = 실제 메모리 주소
segment table : 각 프로세스 별로 segment table을 가지고 있으며, segment 별 base, bounds 유지
문제점 : External Fragmentation
External Fragmentation : 메모리를 할당/해제를 반복하다 보면, 사용가능한 메모리 공간의 합이 할당할 프로세스가 필요한 메모리보다 큼에도, 나뉘어져 있어 프로세스를 할당하지 못하는 경우 -> 메모리 공간이 파편화되어있다!
free space를 관리하는 여러 방법도 있지만, optimal solution이라고 볼 수 있는 방법은 딱히 없다.
compaction : 파편화된 메모리 공간을 하나로 합치는 과정 -> 그러나 cost가 너무 크다!!
Paging
- 가상 주소 공간을 일정한 크기의
page로 나눈다. - 실제 주소 공간을 일정한 크기의
page frame으로 나눈다. - 프로세스 별로 가지고 있는
page table를 활용해page를page frame에 할당
Paging의 장점
- 고정 크기로 메모리를 다루기 때문에 고려해야할 것들이 줄어듬
- 여유 공간이 단순해진다 ->
external fragmentation방지
문제점
1. Internal fragmentation : page size보다 작은 데이터를 할당하면 page 안에 남는 공간이 발생한다!!
2. Page table에 접근하고, 거기서 얻은 PTE를 통해 실제 메모리로 접근한다. -> 총 2번의 메모리 접근 -> 성능 저하!
3. 매우 큰 page table
Translation Lookaside Buffers(TLB)
MMU의 한 부분, VPN과 PFN이 쌍으로 존재하는 cache!
주소 변환을 할 때, page table(메모리)을 확인하기 전에 TLB를 먼저 확인!
TLB를 사용하여 paging 속도를 높일 수 있다
TLB를 사용해 paging의 속도를 높이려고 할 때 고려할 Issue
- TLB도 다른 캐시와 마찬가지로
Cache Miss가 발생한다!Cache Miss를 어떻게 처리할 것인가..
1.Hardware: page table의 위치와 내용을 정확히 알아야 한다! 빠르지만, intelligent하지 못하다(victim 선정), 그리고 비싸다!
2.OS: TLB miss -> trap -> kernel mode -> page table -> TLB update -> return-from-trap -> retry
-> 하드웨어로 처리하는 방식보다는 느리지만, CPU가 단순해진다. Context Switch
- 여러 프로세스가 실행되다보면, TLB table 상에 같은 VPN을 사용하는 TLB entry가 겹칠 수 있다!
- 프로세스를 구별하기 위해 추가 비트 사용(ASID)!
Page table의 크기를 줄이는 방법은 없을까?
- Page의 크기를 늘리면?
- Page table은 줄어들지만,internal fragmentation이 발생할 가능성 높아짐!! - segmentation + paging
- 각 segment(code, heap, stack)별로 page table을 유지한다!
- 하지만 segmentation을 사용하기 때문에 segmentation이 가지고 있는 문제점이 그대로 나타난다 - Multi-level Paging
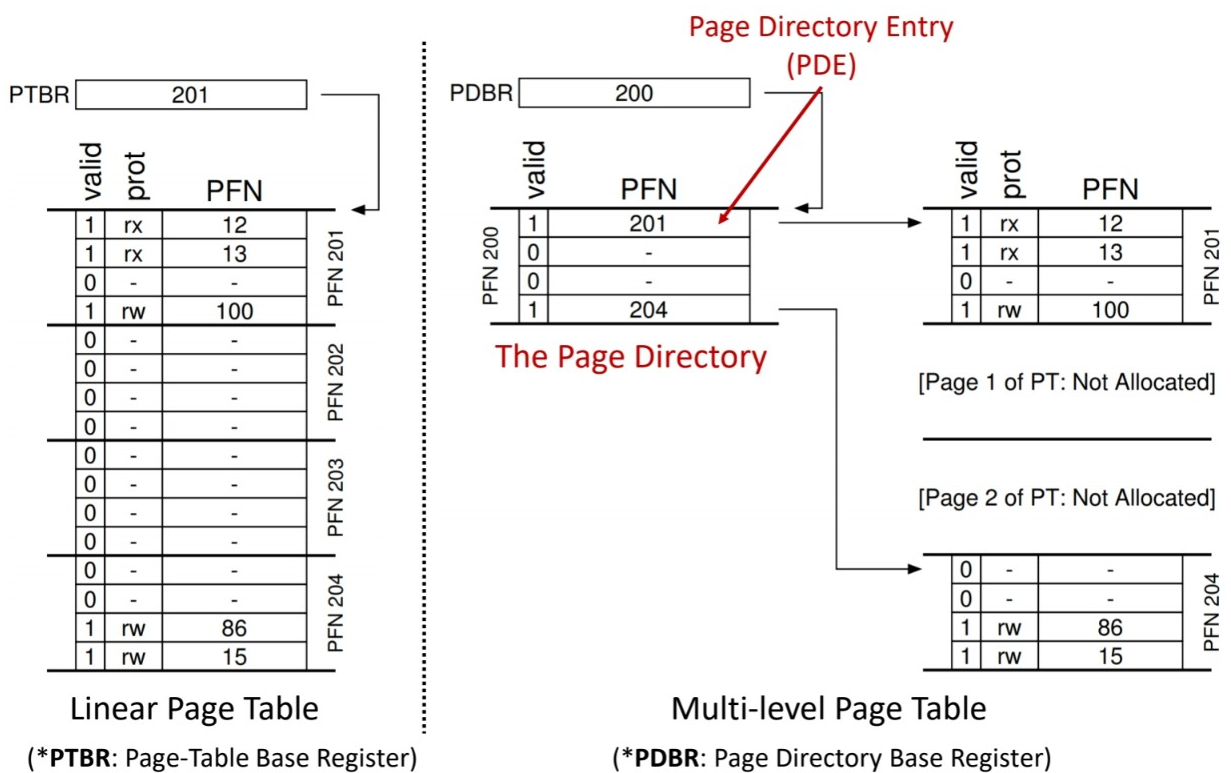
-page directory를 유지하여 page table을 계층적으로 만들고, 사용하지 않는 page table은 제거한다!
- page table이 차지하는 공간을 줄여주지만, TLB miss가 발생했을 때의 메모리 접근 횟수가 더 늘어남
Swapping
메모리 크기보다 큰 프로세스를 실행하려고 한다면? -> 더 큰 저장공간이 필요하다!
프로세스의 모든 페이지가 메모리에 존재하는 것은 아니다! -> memory + 디스크(스왑 공간)
스왑 공간을 사용하려면, page가 메모리에 있는지 디스크에 있는지 알아야 한다! -> present bit
page hit: 페이지가 메모리에 존재할 때page fault: 페이지가 메모리에 없을 때 -> PTE에서 page의 disk 주소를 알아낸다 -> page 를 메모리에 할당 -> TLB에 기록Thrashing: 실행 중인 프로세스들이 요구하는 메모리의 크기가 실제 보다 클때, OS는 계속 page fault를 발생시킴
