이글은 하이퍼 커넥트 Tech Blog-고성능 ML 백엔드를 위한 10가지 Python 성능 최적화 팁 #4을 참조하였습니다.
들어가기 전에 아래 내용먼저 보고 본론을 보겠습니다.
WSGI & ASGI
WSGI
web server gateway interface의 약어로 파이썬 애플리케이션 서버를 동작시키기 위한 인터페이스입니다.
관련 내용에 대해서는 아래 링크들과 같이 잘 설명된 것이 있어 간단하게 넘어가겠습니다.
ASGI
WSGI가 나온 이후로 python의 비동기코드를 처리할 수 있도록 개선한 인터페이스입니다.
더 많은 내용은 이 블로그에 잘 정리되어 있습니다
Gunicorn & Uvicorn
Gunicorn
guicorn은 위에서 설명한 wsgi중 하나입니다.
gunicorn design에서 관련내용을 볼 수 있습니다.
prefork
테크 블로그의 글과 gunicorn design글에서 pre fork라는 말이 나오는데 이는 미리 자식 프로세스를 여러개 띄워서 처리하는 방식입니다.
prefork 기반 웹서버가 요청을 동시에 처리할 수 있는 이유에서 자세한 설명을 참고할 수 있었습니다.
Uvicorn
uvloop와 httptools을 이용해 만든 ASGI입니다. V8엔진에서 사용하는 libuv를 기반으로하고 Cython으로 구현되어 있습니다.
muliprocess 환경에서 num_thread 조정
백엔드 서버는 여러 요청을 동시에 처리하기 위해 하드웨어의 멀티 코어를 사용을 자주 사용합니다. Python 에서도 gunicorn과 같은 pre-forked worker model을 통해 멀티프로세싱을 지원하는 서버를 손쉽게 만들어낼 수 있습니다.
하이퍼커넥트의 추천 API 서버도 gunicorn을 이용하여 하나의 pod에 pre-forked unvicorn process(Web Worker) 다수를 미리 만들어둔 후, 동시에 여러 요청이 들어왔을 때 다수 process에서 동시에 요청을 처리하며 CPU 자원을 병렬적으로 사용할 수 있도록 활용하고 있다고 합니다.
최신의 CPU는 대부분 여러 개의 코어를 가지고 있기 때문에, 일반적으로 병렬성을 이용하면 CPU의 utility를 높여 더 빠른 응답속도와 처리량을 갖는 서버를 구성할 수 있습니다. 하지만 백엔드 어플리케이션에서 PyTorch나 Numpy를 사용하고 있다면, 성능이 나빠진 수 있기 때문에 gunicorn처럼 병렬로 웹 요청을 처리하는 서버를 사용할 때 유의해야 합니다.
글이 읽기 쉽게 정리되어 있어 덧붙일 말이 없는 것 같습니다.
PyTorch나 Numpy는 기본적으로 내부 연산을 멀티스레딩으로 수행합니다. (참고로 여기서의 멀티스레딩은 Python multithreading이 아닌, C-level에서의 멀티스레딩입니다!) 다시 말하면, 이 두 라이브러리에서는 현재 환경에서 가용한 CPU 자원을 최대한으로 사용합니다. vCPU가 4인 VM이나 Container, K8S Pod에서는 PyTorch에서 4개의 스레드를 사용해서 내부 연산을 처리한다는 말이죠. 이 점을 간과한 채 vCPU가 4인 pod에서 gunicorn을 사용해서 4개의 web worker (혹은 pre-forked process)를 띄운다면, 하나의 vCPU가 하나의 worker에서만 독립적으로 사용되지 않고, worker마다 서로 모든 CPU를 사용하려고 싸우며, interleaving 되는 시나리오가 발생할 수 있습니다. 이는 context-switching 오버헤드를 증가시키고, L1/L2 cache-miss를 발생시키며, 결과적으로 성능을 저하시키게 됩니다.
interleaving 시나리오가 조금 헷갈렸는데 지속적인 context switch 발생을 뜻하는 것 같습니다. 검색하면 메모리 인터리빙 말고는 나오지 않는데, 직역하면 끼워넣다가 되니 context-switch와 맞아 떨어집니다.
Context-Switching
context switch는 멀티 프로세스, 멀티 스레드, 혹은 비동기 작업에 대해서 인터럽트 요청에 의해 다음 우선 순위의 작업이 실행되어야 하는 경우 실행하던 내용을 각각 PCB, TCB에 저장하고 우선 순위의 작업으로 교체하여 실행하는 것을 뜻합니다.(비동기 작업 같은 경우는 함수 스택을 저장할텐데 어디에 저장하지는 잘 모르겠네요... 아마 스레드 어딘가 해놓지 않을까 싶습니다)
Cache miss/hit
CPU, GPU 등 컴퓨터 리소스는 대부분 캐시 저장소를 가지고 있습니다. 캐시 저장소는 연산하는 장치와 메모리가 저장된 공간 가까우면 가까울수록 더 빠르게 정보를 가져올 수 있습니다. 이에 사용하고자 하는 정보가 캐시에 담겨 있으면 hit, 없다면 miss입니다.
위에서 말한 context-switch를 계속하면 캐시에 들어갈 수 있는 용량에는 한계가 적기 때문에 금방 새로운 내용으로 바뀝니다. 그래서 cache miss가 더 많이 발생하고 이로 인해 성능이 저하된다고 말합니다.
Code Example
import numpy as np
import torch
numpy_a = np.empty(shape=(10000, 10000))
numpy_b = np.empty(shape=(10000, 10000))
numpy_a @ numpy_b
torch_a = torch.from_numpy(numpy_a)
torch_b = torch.from_numpy(numpy_b)
torch_a @ torch_bOS가 ubuntu이고 CPU코어가 40개인 서버에서 돌려봤는데 htop을 통해서 확인하면 아래와 같은 결과를 볼 수 있었습니다. 코어 수가 많아서 그런지 전체 코어는 사용하지 않는 것으로 보였고 사용되는 코어 넘버는 계속 바뀌었습니다.
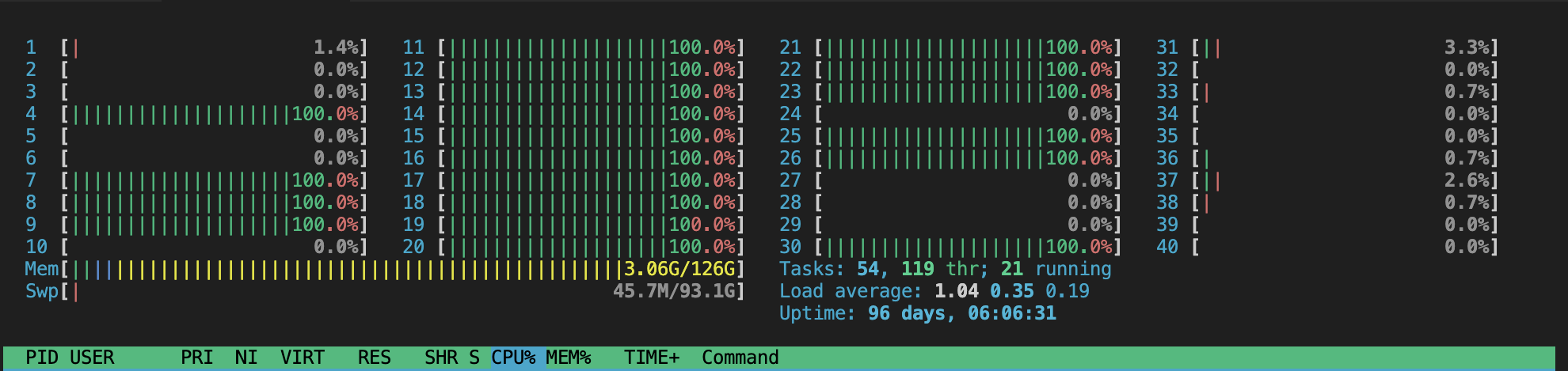
하이퍼 커넥트의 경우에는 하이퍼 스레드 기술이 사용되어 16개의 코어를 가지지만 8개의 코어를 사용한다고 합니다. 이러한 하이퍼 스레드기술로 만들어진 코어는 논리적인 가짜 코어로 볼 수 있습니다. 하이퍼 스레드는 행렬 곱 연산처럼 거의 완벽한 수준의 instruction level parallelism이 구현된 라이브러리의 경우에는 별 도움이 되지 않는다고 합니다.
실제 서버에서는 위와 같은 문제를 어떻게 해결할까요? FastAPI와 PyTorch를 사용해서 행렬곱(matmul)을 하는 예시입니다. 실제 FastAPI는 아니지만 프로세스를 사용해서 서버를 띄우기 때문에 거의 동일하다고 볼 수 있습니다.
import os
import time
import multiprocessing as mp
import torch
def foo(i: int) -> None:
matrix_a = torch.rand(size=(1000, 1000))
matrix_b = torch.rand(size=(1000, 1000))
# warm up
for _ in range(10):
torch.matmul(matrix_a, matrix_b)
start_time = time.perf_counter()
for _ in range(100):
torch.matmul(matrix_a, matrix_b)
print(i, time.perf_counter() - start_time)
if __name__ == "__main__":
# 특정 pid를 가지는 프로세스를 실행할 수 있는 cpu코어의 개수
num_processes = len(os.sched_getaffinity(0))
print("num_processes: ", num_processes)
with mp.Pool(num_processes) as pool:
pool.map(foo, range(num_processes))코어가 40개 정도라 출력의 일부만 올리겠습니다.
33 11.426629900932312
6 12.509334267117083
34 12.735929041169584
15 13.404642578214407
37 13.542089831084013
29 13.499001455493271
3 13.772453321143985
36 13.871894866228104
0 14.012006905861199
1 13.81653778348118
10 13.40723427478224
8 13.524374637752771
25 14.12644547317177
7 13.637029951438308아래는 OMP_NUM_THREADS=1을 통해 스레드 개수를 1로 제한을 두고 실행한 결과입니다. (이 예시는 OMP_NUM_THREADS를 통해 프로세스 당 스레드를 제한했지만 torch를 사용할 때는 torch.set_num_threads(1) 메서드를 호출하여 제한할 수도 있습니다)
13 6.027606325224042
16 6.09168167412281
30 6.017044412903488
33 6.018002468161285
39 5.91914439573884
1 6.1490017315372825
29 6.0204807836562395
9 6.127565494738519
12 6.046798218972981
26 6.057520775124431
21 6.0107248006388545
32 6.023716802708805
5 6.1606452921405435
0 6.164908490143716하이퍼 커넥트의 경우는 6배이지만 저는 코어수가 많아서 그런지 2배정도 빨라진 것을 볼 수 있습니다.
블로그에서 친절하게 왜 최대 CPU사용하는 것이 기본 설정인지까지 보여줍니다
왜 PyTorch와 Numpy는 최대한의 CPU를 사용하는 것이 기본 설정일까요? 왜냐하면 이들 라이브러리는 데이터 분석과 모델 학습이 주된 사용처이기 때문입니다. 데이터 분석과 모델 학습시에는 백엔드 서버처럼 동시에 여러 작업을 수행할 일이 드물고, 그렇다면 가용한 CPU를 모두 사용하는 것이 더 빠른 속도를 보여주기 때문입니다.
하이퍼커넥트에서는 모델서버에서 PyTorch 스레드를 1로 제한하는 설정을 추가하여 Latency와 Throughput이 각각 최대 3배 이상까지 개선되는 경험을 했다고 합니다.
