책에서 딥러닝 파트도 간결하게 정리가 정말 잘 되어있습니다. 딥러닝 관련 내용이므로 넘어가고 가치 기반 에이전트에 대해 알아보겠습니다.
여전히 model free상황이고 상태 공간과 액션 공간이 너무 커서 밸류를 일일이 테이블에 담지 못하는 상황에서의 해결책을 다룹니다. 이를 위해 딥러닝과 강화학습의 결합이 목표입니다.
강화학습과 neural network를 결합하는 방법은 크게 2가지가 있습니다. 하나는 가치함수 나 를 neural network으로 표현하는 방법이고 다른 하나는 정책 함수를 neural network로 표현하는 것입니다.
RL Agent의 분류
-
가치 기반(value-based) 에이전트는 가치함수에 근거하여 액션을 선택합니다. model-free상황에서는 만 가지고 액션을 정할 수 없기 때문에 가치 기반 에이전트는 를 필요로 합니다. SARSA, Q-learning이 이에 속합니다.
-
정책 기반(policy-based) 에이전트는 정책 함수를 보고 액션을 선택합니다. 밸류를 보고 액션을 선택하지 않으며, 가치함수를 따로 두지 않습니다. 만 있으면 에이전트는 MDP내에서 경험을 쌓을 수 있고, 이 경험을 이용해 학습 과정에서 를 강화합니다.
-
액터 크리틱(actor-critic)은 가치 함수와 정책 함수 모두 사용합니다. actor는 행동하는 주체, critic은 가치함수를 나타냅니다.
value network의 학습
정책 가 고정되어 있을 때 neural network를 이용해 를 학습하는 모델 를 벨류 네트워크라고 부릅니다.
가치함수의 정답을 라고 가정하고 손실함수는 간단하게 MSE를 사용하겠습니다. 그러면 아래와 같은 식으로 표현할 수 있습니다.
모든 상태 s에 대해 를 최소화 하기는 불가능하기 때문에 아래와 같이 기댓값을 이용할 수 있습니다.
그라디언트를 계산하여 아래와 같이 구합니다. 2는 상수라서 를 통해 조절가능해서 없애줘도 무방합니다.
파라미터를 아래와 같이 업데이트 합니다. 실제로는 여러번의 경험을 바탕으로 평균값으로 업데이트 합니다.
정답을 로 가정했지만 아직 값을 모르기때문에 위의 식을 적용할 수 없습니다. 그래서 이전에 했던 방식인 MC, TD중 하나를 택하여 적용해서 구해볼 수 있습니다.
MC return
MC를 이용해 테이블 업데이트를 했던 식을 다시 보겠습니다.
의 기댓값이 곧 실제 가치 함수의 정의이기 때문에 정답에 를 사용할 수 있습니다. 그러면 자리에 를 대입한 식을 보겠습니다.
손실함수를 정의했으니 파라미터 업데이트도 방식도 동일하게 이루어집니다.
테이블 방식에서 뉴럴넷으로만 바뀌었을 뿐 MC방법론의 특성은 동일하게 가지고 있습니다. 여전히 에피소드가 끝날 때까지 많은 확률적 요소가 결합되어 있어 정답지의 분산이 크고, 하나의 에피소드가 끝나야 업데이트가 가능합니다.
TD target
TD방식도 아주 간단합니다.
대신 TD target인 를 대입해주면 됩니다.
강화학습 구현시 는 반드시 상수 취급을 해서 편미분시 값을 0으로 만들어 주어야합니다. 실제로 변수가 있지만 목적지의 값을 고정해야 모델 학습시 안정적으로 학습이 가능하기 때문입니다.
DQN
가치 기반 에이전트는 명시적인 정책(explicit policy)이 따로 없습니다. 대신 를 통해 가치가 높은 액션을 선택하여 정책 함수처럼 사용합니다. 이런 경우 정책 함수를 내재된 정책(implicit policy)이라고 합니다. 이번에 알아볼 DQN은 를 내재된 정책으로 사용합니다.
이론적 배경
Q-learning을 한번 다시 보면서 넘어 가겠습니다.
이 Q-learning내용을 뉴럴 네트워크로 확장하기만 하면 됩니다.
2015년 구글 딥마인드 팀에서 쓴 논문 DQN을 발표했습니다. 위에서 말한 것처럼 뉴럴 네트워크를 이용해 Q함수를 강화하는 것입니다.
논문에서는 학습을 안정화하고 성능을 끌어올리기 위해 2가지 특별한 방법론을 도입했습니다.
Experience Replay
강화학습은 에이전트가 겪은 경험으로 강화를 하는 과정입니다. Experience Replay라는 단어 그대로 겪었던 경험을 재사용하면 어떨까?라는 아이디어에서 출발합니다. 경험은 여러 개의 에피소드로 이루어져있고, 에피소드는 여러 개의 상태 전이(transition)으로 이루어져 있습니다. 상태 전이는 (으로 표현할 수 있습니다. 하나의 상태전이는 하나의 데이터 입니다.
이런 낱개의 데이터를 사용하기 위해 논문에서 replay buffer라는 개념을 사용합니다. 버퍼에 가장 최근의 데이터 n개를 저장해 놓자는 아이디어 입니다.예를 들어 가장 최근에 발생한 100만개의 데이터를 버퍼에 들고 있다가, 새로운 데이터가 들어오면 가장 오래된 데이터를 제거함으로써 최신 데이터를 유지합니다. 그리고 학습할 때는 버퍼에서 임의의 데이터를 여러개 뽑아서 미니 배치를 만들어 학습합니다. 랜덤하게 뽑다보면 각각의 데이터는 재사용 될 수 있어서 이는 데이터의 효율성을 높여줍니다.
100만개의 데이터에서 랜덤한 데이터를 뽑으면 미니 배치 안에 서로 다른 게임에서 발생한 데이터들이 섞이게 됩니다. 다양한 데이터로 학습을 하면 한 게임 안에서 발생한 연속된 데이터를 사용할 때 보다 각각의 데이터 사이 상관성이 작아서 더 효율적으로 학습할 수 있다고 합니다. 논문에서 이 상관성을 깨는 부분이 성능 개선에 큰 역할을 했다고 말합니다.
(상관성을 줄여서 학습이 잘 되는 것은 이해가지만 이미 학습한 데이터를 한번 더 학습하는 것에 대해서는 효율성이 늘어나거나 학습이 더 잘되는 것은 이해가 안되네요...)
experience replay를 사용할 때 off-policy알고리즘에만 사용할 수 있다는 점을 주의해야합니다. 조금만 생각해보면 당연한 얘기입니다. 과거의 정책들의 데이터를 가져와 학습을 하기 때문입니다.
Cycle GAN논문을 읽을 때 replay buffer개념을 가져와 discriminator 여러개를 사용하는데 드디어 뭔지 정확히 알게되었습니다. 알고 나면 쉬운 개념이었네요
Target Network
DQN을 향상시키는 다른 아이디어는 별도의 타깃 네트워크를 두는 것입니다.
손실 함수 를 통해 정답과 추측 사이의 차이를 줄이는 방향으로 가 업데이트됩니다. 그런데 Q-learning에서는 이 정답으로 사용되기 때문에 에 의존적입니다. 그래서 가 업데이트 될 때마다 정답에 해당하는 값이 계속 변하게 됩니다.
딥러닝에서 모델이 가야할 true value값이 바뀌는 것은 학습의 안정성을 매우 떨어뜨립니다. 그래서 논문에서는 정답을 계산할 타깃 네트워크와 학습을 시킬 Q네트워크 두 개의 모델을 준비합니다. 그리고 정답을 계산할 네트워크의 파라미터를 고정시켜두고 정답을 계산합니다. 그러면 정답이 안정적인 분포를 가지게 됩니다. 그 Q네트워크는 계속 업데이트 하다가 일정 주기마다 얼려둔 정답 모델의 파라미터를 최신 파라미터로 교체해 줍니다. (이 아이디어와 이 방법으로 인해 생기는 문제가 GAN이랑 유사한 것 같네요)
이제 2가지 트릭을 포함해서 DQN을 구현해 보겠습니다.
DQN code
풀고자 하는 문제는 CartPole입니다.

카트폴은 OpenAI 단체에서 만든 OpenAI Gym이라는 라이브러리 안에 포함된 하나의 환경입니다. 카트는 일정한 힘으로 왼쪽이나 오른쪽으로 미는 2가지 액션만 가지고 있습니다. 그리고 스텝마다 +1의 보상을 받습니다. 막대가 수직으로 15도 이상 기울어지거나 카트가 화면 밖으로 나가면 종료됩니다.(공식문서를 읽어보면 종료조건이 다릅니다.)
카트의 상태 s는 길이 4의 벡터(카트 위치, 카트 속도, 막대 각도, 막대 각속도)입니다.
카트폴 환경은 최적 정책이 간단해 cpu환경으로도 빠르게 학습 결과를 볼 수 있습니다.
환경 설정 및 코드 입니다. mac에서는 정상작동하고 linux는 [all]을 설치하면 오류가 생겨서 [classic-control]옵션으로 설치해야했습니다.
책이랑 코드는 동일하지만 gym라이브러리가 아닌 업그레이드 된 gymnasium을 사용합니다.
pyenv local 3.9.16
pipenv --python 3.9.16
pipenv install "gymnasium[all]" torch numpyimport collections
import random
import gymnasium as gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
hyper_parmas = {
'lr': 0.0005,
'gamma': 0.98,
'buffer_limit': 50000,
'batch_size': 32
}deque라이브러리를 이용해 replay buffer를 쉽게 구현할 수 있습니다.
class ReplayBuffer:
def __init__(self):
self.buffer = collections.deque(maxlen=hyper_parmas['buffer_limit'])
def put(self, transition):
self.buffer.append(transition)
def sample(self, n):
mini_batch = random.sample(self.buffer, n)
s_lst, a_lst, r_lst, s_prime_lst, done_mask_lst = [], [], [] ,[] ,[]
for transition in mini_batch:
s, a, r, s_prime, done_mask = transition
s_lst.append(s) # (32, 4)
a_lst.append([a]) # shape을 (32, 1)로 맞추기 위해 리스트안에 감싸서 넣음
r_lst.append([r]) # shape을 (32, 1)로 맞추기 위해 리스트안에 감싸서 넣음
s_prime_lst.append(s_prime) # (32, 4)
done_mask_lst.append([done_mask]) # shape을 (32, 1)로 맞추기 위해 리스트안에 감싸서 넣음
s_lst = np.array(s_lst)
a_lst = np.array(a_lst)
r_lst = np.array(r_lst)
s_prime_lst = np.array(s_prime_lst)
done_mask_lst = np.array(done_mask_lst)
return torch.tensor(s_lst, dtype=torch.float32), torch.tensor(a_lst),\
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float32),\
torch.tensor(done_mask_lst)
def size(self):
return len(self.buffer)모델은 아주 간단합니다. 일반 딥러닝 모델 만드는 것처럼 만들면 됩니다.
class Qnet(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(4, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, 2)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def sample_action(self, obs, epsilon):
coin = random.random()
if coin < epsilon:
return random.randint(0, 1)
else:
out = self.forward(obs)
return out.argmax().item()Q 모델을 구현하는 2가지 방식이 있는데 하나는 s, a를 동시에 인풋으로 받아 그 밸류를 리턴하는 형태, 다른 하나는 s만 인풋으로 받아 모든 액션에 대한 밸류값을 한번에 리턴하는 형태입니다. 구현상의 차이만 있을 뿐 의미는 동일하다고 합니다. 위의 코드는 후자의 방식을 택했습니다.
마지막 학습 부분 코드입니다.
def train(q, q_target, memory, optimizer):
for _ in range(10):
s, a, r, s_prime, done_mask = memory.sample(hyper_parmas['batch_size'])
q_out = q(s) # 모델 결과값 도출
q_a = q_out.gather(1, a) # axis=1, a 액션 value 가져오기
max_q_prime = q_target(s_prime).max(1)[0].unsqueeze(1)
target = r + hyper_parmas['gamma'] * max_q_prime * done_mask
loss = F.smooth_l1_loss(q_a, target) # 식은 제곱차이지만 코드에서는 smooth L1 loss로 정의되어있네요
optimizer.zero_grad()
loss.backward()
optimizer.step()def main():
# env = gym.make('CartPole-v1', render_mode="human")
# 실제 동작하는 것을 눈으로 보고 싶으면 위의 코드 주석을 해제하면 됩니다.
env = gym.make('CartPole-v1')
q = Qnet()
q_target = Qnet()
q_target.load_state_dict(q.state_dict())
memory = ReplayBuffer()
print_interval = 100
score = 0.0
optimizer = optim.Adam(q.parameters(), lr=hyper_parmas['lr'])
for n_epi in range(1, 10001):
epsilon = max(0.01, 0.08 - 0.01*(n_epi/200)) # 8% -> 1%
s = env.reset()[0]
# reset() 값 : tuple
done = False
while not done:
a = q.sample_action(torch.from_numpy(s).float(), epsilon)
s_prime, r, done, _, info = env.step(a)
done_mask = 0.0 if done else 1.0
memory.put((s, a, r/100.0, s_prime, done_mask))
s = s_prime
score += r
if done:
break
# env.render()
if memory.size() > 2000:
train(q, q_target, memory, optimizer)
if n_epi % print_interval == 0:
q_target.load_state_dict(q.state_dict())
print(f"n_episode: {n_epi} | socre: {score/print_interval:.1f} | n_buffer: {memory.size()} | eps: {epsilon*100:.1f}%")
score = 0.0
# env.close()
main()결과값은 아래와 같습니다
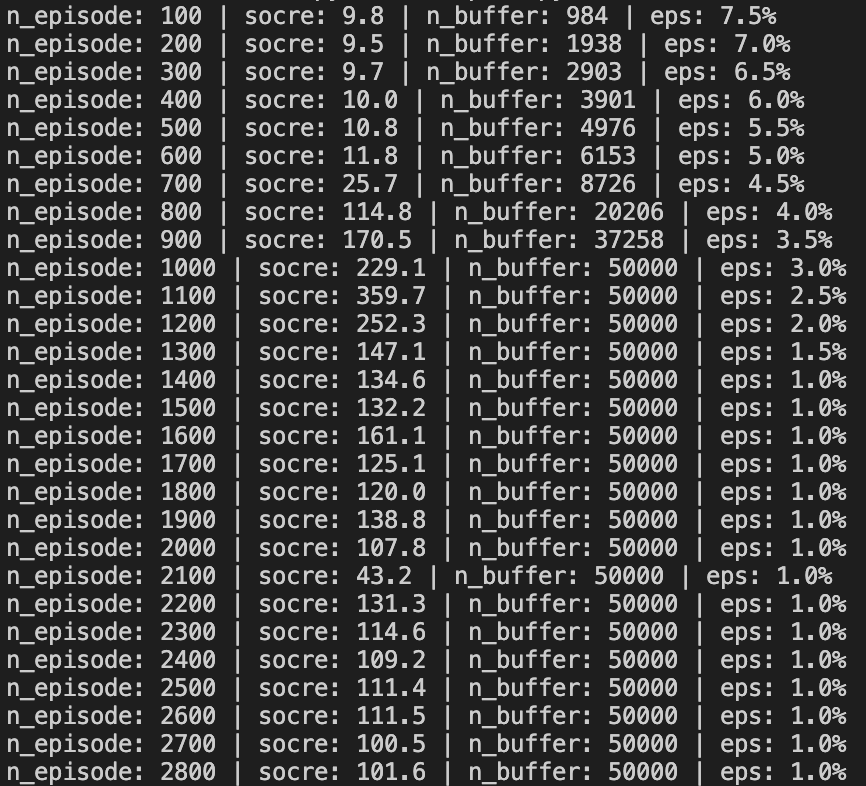
책에서 제공하는 코드 말고 pytorch tutorial 코드도 있습니다.
