개요
스프링 부트는 웹서버 어플리케이션 구조에 대해 잘 몰라도, 뚝딱 웹서버 어플리케이션을 만들게 도와줍니다. 하지만 한번씩 궁금증이 들 때가 있습니다. 이게 왜 되지..?
스프링, 이거 왜지? 시리즈 1탄으로 스프링부트 다중처리요청에 대해 알아보겠습니다.
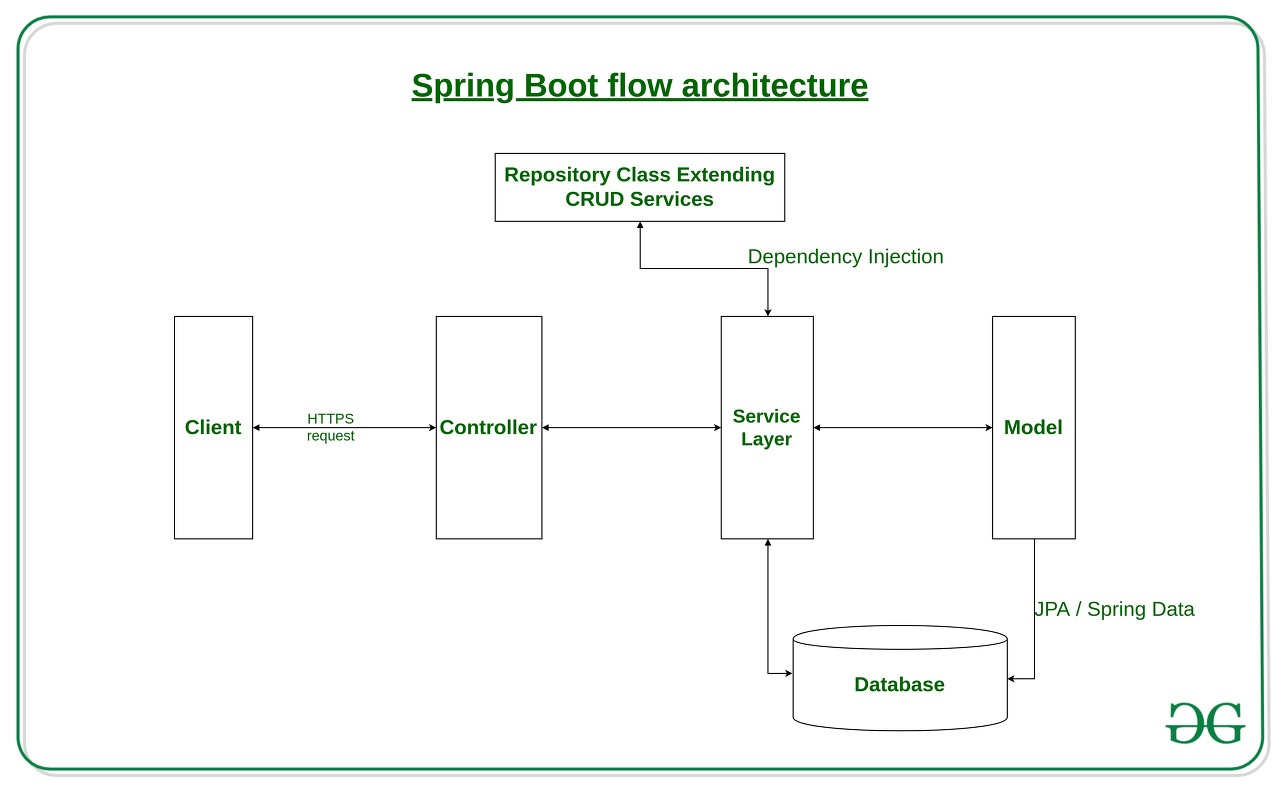
스프링부트의 flow를 찾아보면 흔히 나오는 MVC 흐름도 그림인데... 한 유저의 요청이 어떻게 처리되는지에 대한 내용은 많지만 여러 유저의 요청이 어떻게 처리되는지에 대한 내용은 잘 없습니다.
추측컨데, MVC는 스프링부트를 사용하는 개발자가 직접 구현해야하는 부분이고, 다중요청처리는 스프링부트가 알아서 해주고 있는 부분이니 상대적으로 관심도가 덜한 것이라 여겨집니다.
그래서 입문자를 위해 쉽게 설명된 자료가 잘 없는 것 같아서, 학습하며 배운 점을 공유하고자 합니다!
사실 스프링부트가 다중요청을 처리하는 것이 아니라, 스프링부트에 내장되어있는 서블릿 컨테이너(Tomcat)에서 다중요청을 처리해줍니다. 서블릿 컨테이너에 대해 잘 모르신다면 서블릿 컨테이너 키워드로 검색하시면 좋은 자료를 많이 찾을 수 있습니다.
핵심 키워드는 Tomcat Thread Pool, NIO Connector, Embeded Tomcat 입니다.
결론부터!
- 스프링부트는 내장 서블릿 컨테이너인 Tomcat을 이용합니다.
스프링부트 2.5.4 기준으로 9.0.52버전의 Tomcat을 내장하고 있습니다.
- Tomcat은 다중 요청을 처리하기 위해서, 부팅할 때 스레드의 컬렉션인 Thread Pool을 생성합니다.
- 유저 요청(HttpServletRequest)가 들어오면 Thread Pool에서 하나씩 Thread를 할당합니다. 해당 Thread에서 스프링부트에서 작성한 Dispatcher Servlet을 거쳐 유저 요청을 처리합니다.
- 작업을 모두 수행하고 나면 스레드는 스레드풀로 반환됩니다.
1번부터 차례대로 내용을 확인해보겠습니다.
스프링부트와 내장 톰캣
스프링과 스프링부트의 주요한 차이점 중 하나는, 스프링 부트에선 내장 서블릿 컨테이너(Tomcat)을 지원한다는 것입니다.
그럼으로써 application.yml 혹은 application.properties (Spring Environment)에 설정을 주는 것만으로 간편하게 Tomcat의 설정을 바꾸어줄 수 있습니다. 다음은 서버의 설정을 바꾸어주는 예시입니다.
# application.yml (적어놓은 값은 default)
server:
tomcat:
threads:
max: 200 # 생성할 수 있는 thread의 총 개수
min-spare: 10 # 항상 활성화 되어있는(idle) thread의 개수
max-connections: 8192 # 수립가능한 connection의 총 개수
accept-count: 100 # 작업큐의 사이즈
connection-timeout: 20000 # timeout 판단 기준 시간, 20초
port: 8080 # 서버를 띄울 포트번호이 밖에도 많은 옵션을 과거 xml방식의 복잡한 설정에서 벗어나 간단하게 옵션을 변경할 수 있습니다. 만약 설정을 주지 않는다면, SpringBoot AutoConfiguration에서 정의한 디폴트값을 주입하게 됩니다. 해당 디폴트 값은
org.springframework.boot.autoconfigure.web.ServerProperties 클래스에서 확인할 수 있습니다. (인텔리제이를 사용하신다면 스프링부트 스타터 의존성을 주입받은 뒤, shift + shift 단축키 + 클래스명으로 확인할 수 있습니다.)
스레드풀(Thread Pool) 설정
위에 예시로 들어둔 yml파일에 적어놓은 값들이, Tomcat ThreadPoolExcutor와 Connector에 줄 수 있는 옵션들입니다.
ThreadPoolExcutor와 Connector는 나중에 다시 알아보고, 우선 Thread Pool이 무엇인지 알아보겠습니다.
스레드풀이란
Thread Pool은 프로그램 실행에 필요한 Thread들을 미리 생성해놓는다는 개념입니다.
(Thread는 cpu의 자원을 이용하여 코드를 실행하는 하나의 단위 입니다. 스레드에 대해 잘 모르신다면스레드 키워드로 검색해보세요.)
Tomcat 3.2 이전 버전에서는, 유저의 요청이 들어올 때 마다 Servlet을 실행할 Thread를 하나씩 생성했습니다. 요청이 끝나면 destory했고요. 이 방침은 두 가지 문제를 야기했습니다.
- 모든 요청에 대해 스레드를 생성하고 소멸하는 것은 OS와 JVM에 대해 많은 부담을 안겨준다.
- 동시에 일정 이상의 다수 요청이 들어올 경우 리소스(CPU와 메모리 자원) 소모에 대한 억제가 어렵다. 즉 순간적으로 서버가 다운되거나 동시다발적인 요청을 처리하지 못해서 생기는 문제가 야기될 수 있다.
해당 문제를 해결하기 위해, 톰캣은 스레드풀을 활용하기 시작합니다.
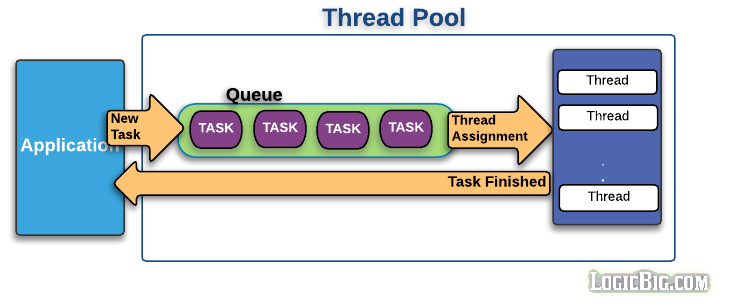
스레드풀의 기본 플로우는 다음과 같습니다.
- 첫 작업이 들어오면, core size만큼의 스레드를 생성합니다.
- 유저 요청(Connection, Server socket에서 accept한 소캣 객체)이 들어올 때마다 작업 큐(queue)에 담아둡니다.
- core size의 스레드 중, 유휴상태(idle)인 스레드가 있다면 작업 큐에서 작업을 꺼내 스레드에 작업을 할당하여 작업을 처리합니다.
3-1. 만약 유휴상태인 스레드가 없다면, 작업은 작업 큐에서 대기합니다.
3-2. 그 상태가 지속되어 작업 큐가 꽉 찬다면, 스레드를 새로 생성합니다.
3-3. 3번과정을 반복하다 스레드 최대 사이즈 에 도달하고 작업큐도 꽉 차게 되면, 추가 요청에 대해선 connection-refused 오류를 반환합니다. - 태스크가 완료되면 스레드는 다시 유휴상태로 돌아갑니다.
4-1. 작업큐가 비어있고 core size이상의 스레드가 생성되어있다면 스레드를 destory합니다.
한줄요약 : 스레드를 미리 만들어놓고 필요한 작업에 할당했다가 돌려 받는다.
2번의 Connection, Server socket에서 accept한 소캣 객체가 이해 안 가신다면 자바 소켓 프로그래밍 로 검색해보세요. 구체적인 구현 보다, 개념적으로 서버와 클라이언트가 어떻게 연결되는지에 대해 알아보세요.
스레드는 많으면 너무 많은 스레드가 cpu의 자원을 두고 경합하게 되므로 처리속도가 느려질 수 있고, 적으면 cpu자원을 최적으로 활용하지 못하여 마찬가지로 처리속도가 느려질 수 있습니다. 스레드는 적절한 수로 유지되는 것이 가장 좋습니다.
스레드 풀은 최대한 core size를 유지하려고 합니다. 이와 관련해 어떤 전략이 있는지는, 스레드풀 전략 으로 검색해보세요.
적절한 스레드의 개수로는 적정 스레드 개수로 검색해보세요.
스레드풀 생성 (ThreadPoolExecutor)
위에 설명한 스레드풀을 자바에서 구현한 구현체가 ThreadPoolExecutor입니다. 앞서 application.yml에서 주었던 설정 중 일부를 보겠습니다.
server:
tomcat:
threads:
max: 200 # 생성할 수 있는 thread의 총 개수
min-spare: 10 # 항상 활성화 되어있는(idle) thread의 개수
accept-count: 100 # 작업 큐의 사이즈이 두가지 설정은 스레드 최대 사이즈 및 core size 를 변경할 수 있도록 해줍니다. 톰캣 9.0의 디폴트 옵션은 각각 200개, 25개 인데 스프링부트(ServerProperties)에선 200개, 10개를 디폴트 값으로 잡았습니다.(core size 기본값을 25개를 10개로 변경한 이유에 대해선 모르겠네요... ^^;)
accept-count는 작업큐의 사이즈 입니다. 스프링 부트에선 아무 옵션을 안주면 Integer.MAX, 즉 21억 블라블라를 줬습니다. 이는 무한 대기열 전략 으로, 아무리 요청이 많이 들어와도 core size를 늘리지 않는다는 정책입니다. 무한 대기열 전략에선 작업큐가 꽉 찰 일이 없으므로, 스레드풀의 max사이즈가 의미가 없습니다.
그럼 설정을 주어 max값을 변경하는 건 아무 의미 없을까요? 뒤에서 다시 알아보겠습니다.
아래는 ThreadPoolExecutor의 생성자에 브레이크 포인트를 찍어놓고 디버그 모드로 실행한 결과입니다. SpringBoot 실행 시, 톰캣을 initalize하고, ThreadPoolExecutor을 상속한 ScheduledThreadPoolExecutor를 생성함을 볼 수 있습니다. 이 때 Environment에 설정한 값이 있다면 해당 값이 주입되고, 없으면 기본값이 주입됩니다.
스레드풀 테스트
지금까지 알아본 바에 의하면, 유저 요청이 들어올 때(Connection)마다 스레드가 하나씩 할당될 것이고, 작업큐가 가득차면 스레드가 늘어날 것이고, 스레드도 가득 차면 유저 요청이 거절되겠죠? 저도 그렇게 생각했고, 간단한 실험을 하나 해봤습니다.
스프링 프로젝트를 하나 만들고, application.yml에 다음과 같이 옵션을 주었습니다.
server:
tomcat:
threads:
max: 2
min-spare: 2
accept-count: 1
port: 5000그 후 3초를 대기하는 api를 하나 만들었습니다.
@Controller
public class HelloController {
private Logger log = LoggerFactory.getLogger(HelloController.class);
@RequestMapping("/hello")
public ResponseEntity<Void> hello() throws InterruptedException {
log.info("start");
Thread.sleep(3000);
log.info("end");
return ResponseEntity.ok().build();
}
}이 프로젝트가 감당할 수 있는 요청은 동원할 수 있는 스레드 2개, 그리고 작업큐 1개에서 대기할 요청까지 최대 3개입니다.
이를 확인하기 위해 또 다른 스프링 프로젝트를 만들어, 요청을 5번 보내보기로 했습니다.
@Controller
public class PowerSmashController {
private Logger log = LoggerFactory.getLogger(PowerSmashController.class);
@GetMapping("/")
@ResponseBody
public ResponseEntity<Void> 요청5개쏘는메소드() {
RestTemplate restTemplate = new RestTemplate();
for (int i = 0; i < 5; i++) {
Thread thread = new Thread(() -> {
log.info("발사!");
String result = restTemplate
.getForObject("http://localhost:5000/hello", String.class);
log.info(result);
});
thread.start();
}
return ResponseEntity.ok().build();
}
}해당 코드는 밀리세컨드 단위로 5번의 요청을 한번에 보내게 됩니다. 2개의 요청이 두개의 활성 스레드에서 각각 3초동안 block되고, 3번째 요청은 작업 큐에서 대기할 것이므로 4, 5번째 요청은 거절되어야 합니다.
결과는..
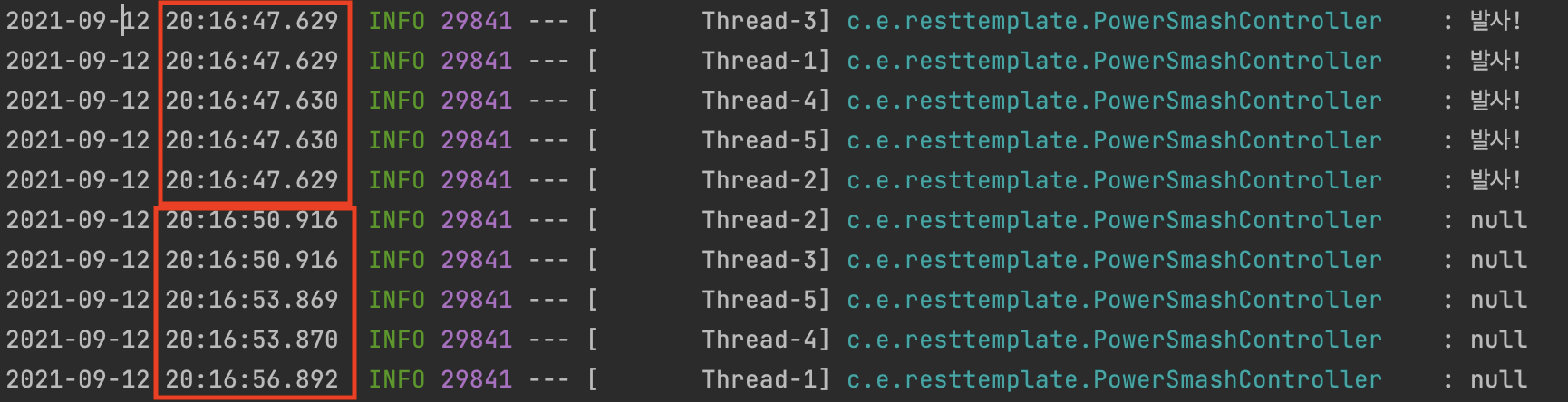
요청은 동시에 갔지만, 응답은 3초단위로 텀을 두고 순차적으로 처리되는 모습을 볼 수 있습니다.
서버측도 확인해보겠습니다.
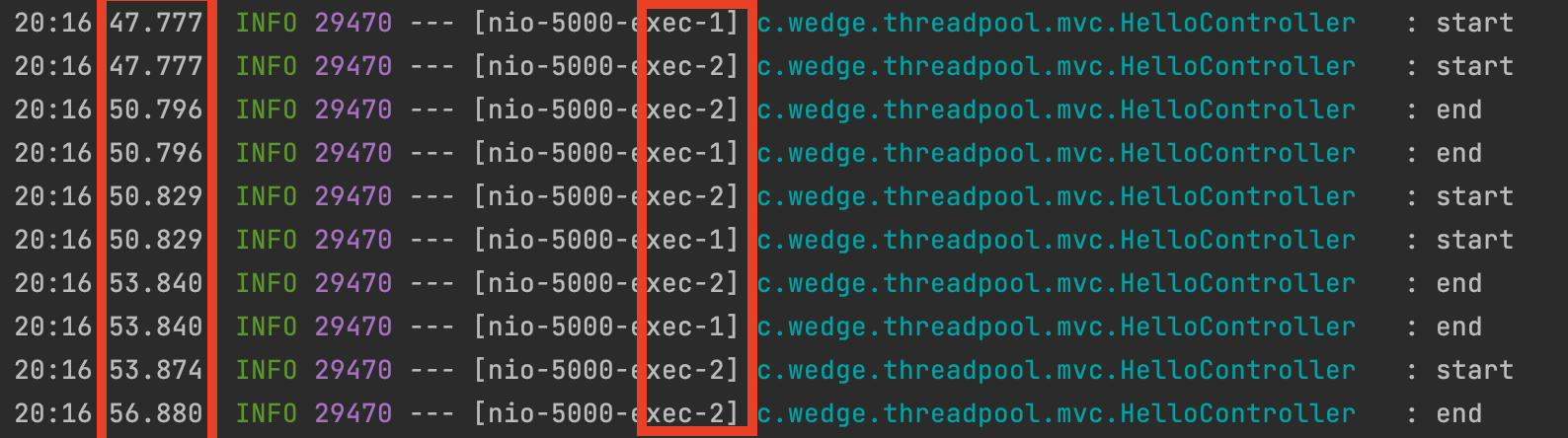
2개의 활성 스레드가 차근차근, 3초 간격으로 작업을 처리한 걸 볼 수 있습니다. 작업큐는 1칸 이므로 두 개의 4,5번 째 요청은 받을 수 없었을텐데 어떻게 이게 가능했을까요?
BIO Connector와 NIO Connector
비밀은 Connector에 있습니다. 위의 이야기는 BIO(Blocking I/O) Connector일 때 유효한 이야기입니다. 그러나 톰캣 8.0부터 NIO(NonBlocking I/O) Connector이 기본으로 채택되고, 9.0부터는 BIO Connector이 deprecate 됨 으로써 위의 설명과는 다른 방식으로 진행되게 됩니다. 하나씩 알아보겠습니다.
Connector
Connector는 소켓 연결을 수입하고 데이터 패킷을 획득하여 HttpServletRequest 객체로 변환하고, Servlet 객체에 전달하는 역할을 합니다.
- Acceptor에서 while문으로 대기하며 port listen을 통해 Socket Connection을 얻게 됩니다.
- Socket Connection으로부터 데이터를 획득합니다. 데이터 패킷을 파싱해서 HttpServletRequest 객체를 생성합니다.
- Servlet Container 에 해당 요청객체를 전달합니다. ServletContainer는 알맞은 서블릿을 찾아 요청을 처리합니다.
BIO Connector
BIO Connector는 Socket Connection을 처리할 때 Java의 기본적인 I/O 기술을 사용합니다. thread pool에 의해 관리되는 thread는 소켓 연결을 받고 요청을 처리하고 요청에 대해 응답한 후 소켓 연결이 종료되면 pool에 다시 돌아오게 됩니다.
즉, conneciton이 닫힐 때까지 하나의 thread는 특정 connection에 계속 할당되어 있을 것입니다.
이러한 방식으로 Thread 를 할당하여 사용할 경우, 동시에 사용되는 thread 수가 동시 접속할 수 있는 사용자의 수가 될 것입니다. 그리고 이러한 방식을 채택해서 사용할 경우 thread들이 충분히 사용되지 않고 idle(아무것도하지않는) 상태로 낭비되는 시간이 많이 발생합니다. 이러한 문제점을 해결하고 리소스(thread)를 효율적으로 사용하기 위해 NIO Connector가 등장했습니다.
NIO Connector
NIO Connector는 I/O가 아니라 Http11NioProtocol을 사용하는데, 해당 내용에 대해 이해하기 위해선 NIO에 대해 이해해야 합니다. 해당 내용에 대해선 자바 NIO 키워드로 검색해보세요.
NIO Connector에선 Poller라고 하는 별도의 스레드가 커넥션을 처리합니다. Poller는 Socket들을 캐시로 들고 있다가 해당 Socket에서 data에 대한 처리가 가능한 순간에만 thread를 할당하는 방식을 사용해서 thread이 idle 상태로 낭비되는 시간을 줄여줍니다.
NIO Connector의 흐름은 다음 그림과 같습니다.
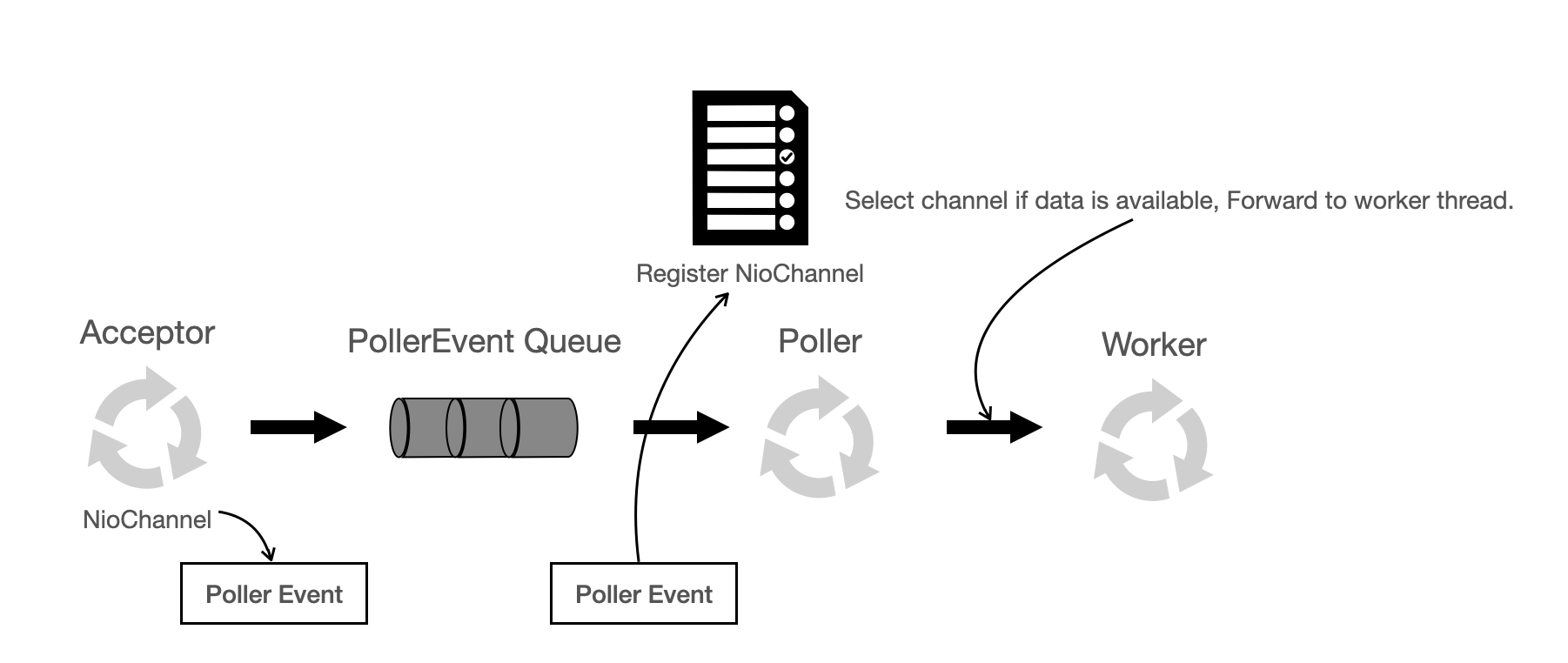
Acceptor는 이름 그대로 Socket Connection을 accept합니다. serverSocket.accept() 방식을 사용하고 있습니다. 소켓에서 Socket Channel 객체를 얻어서 톰캣의 NioChannel 객체로 변환합니다. 그리고 추가로 NioChannel 객체를 PollerEvent라는 객체로 한번 더 캡슐화해서 event queue에 넣게 됩니다. Acceptor는 event Queue의 공급자, Poller thread는 event Queue의 사용자입니다.
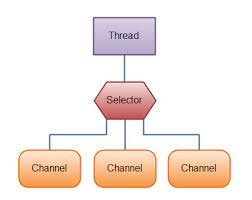
Poller는 NIO의 Selector를 가지고 있습니다. Selector에는 다수의 채널이 등록되어 있고, select 동작을 수행하여 데이터를 읽을 수 있는 소켓을 얻습니다. 그리고 Worker Thread Pool에서 이용할 수 있는 Woker Thread를 얻어서 해당 소켓을 worker thread에게 넘기게 됩니다.
Java Nio Selector를 사용해서 data 처리가 가능할 때만 Thread를 사용하기 때문에 idle 상태로 낭비되는 Thread가 줄어들게 됩니다.
Poller에선 Max Connection까지 연결을 수락하고, 셀렉터를 통해 채널을 관리하므로 작업큐 사이즈와 관계 없이 추가로 커넥션을 refuse하지 않고 받아놓을 수 있습니다.
스레드 또한 모자라다면 max사이즈 까지 스레드를 추가하는 것을 볼 수 있었는데, 해당 이유에 대해선 확인 후 보충하겠습니다!
8.0 버전의 Connector 구현체들입니다. 링크
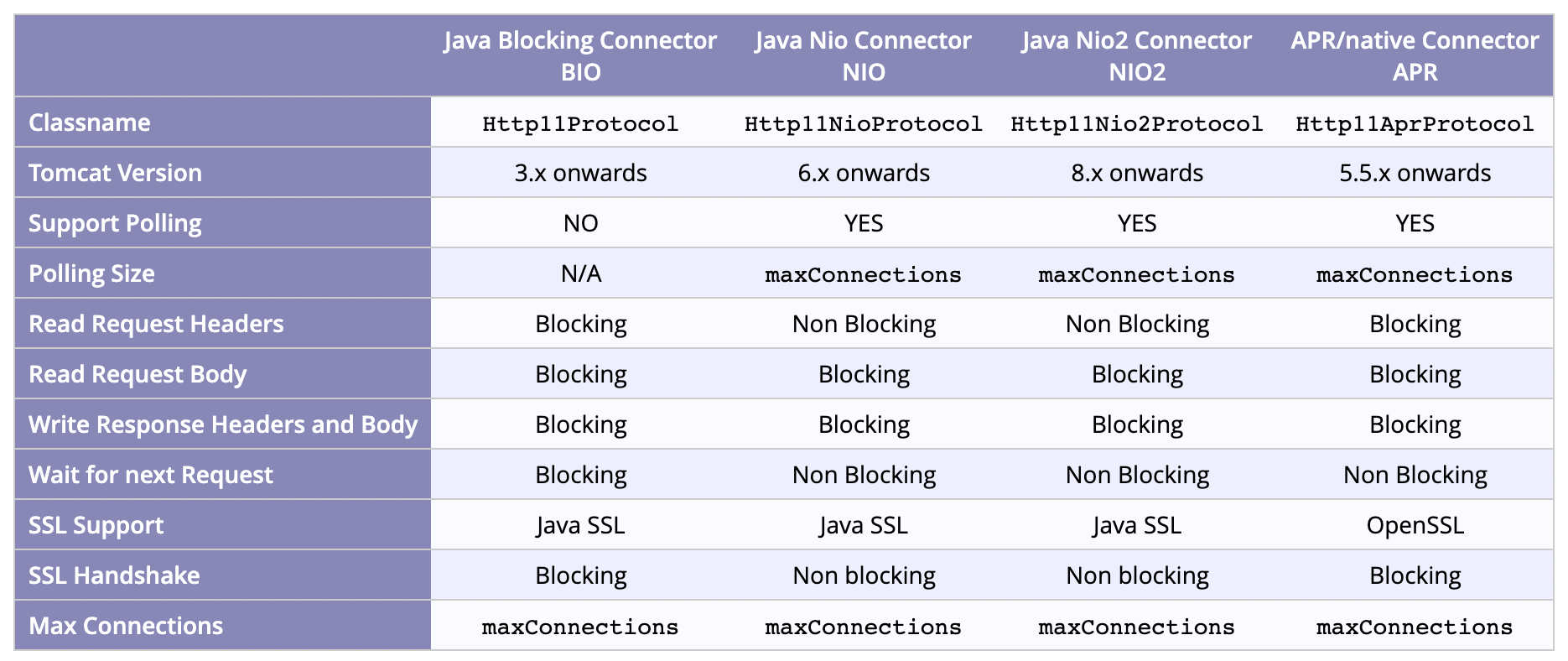
요약
NIO 기반의 Connector는 하나의 Connection이 하나의 스레드를 할당받는 BIO Connector에 비해, Selector를 활용해 Socket을 관리하므로 더 적은 스레드를 사용합니다. 또한 max-connections값까지 접속을 유지하고, 스레드가 모자라다면 max 사이즈까지 스레드를 추가합니다. time-wait시간 안에 처리가 가능하다면 처리할 수 있습니다.
정리
스프링부트가 유저 요청 다중 처리를 위해 활용하는 Tomcat의 스레드풀과 Connector의 개념에 대해 알아보았습니다! 더이상 Bio Connector는 활용되지 않을 것 같지만, 개인적으로 NIO가 너무 어렵기도 하고, 변화한 흐름을 따라가니 학습이 더 용이했던 것 같습니다. 추가적으로 보충할 내용이 있다면 수정하겠습니다~!

9개의 댓글



게시글 잘 읽었습니다. 보통 입문자를 대상으로 하는 강의나 자료엔 구체적인 구현방법만 백과사전식으로 나온 경우가 많아요. 그래서 프레임워크의 구조와 원리에 대한 기초를 이해하기 어려웠습니다. 하지만 작성자님의 정리 덕분에 새로운 프레임워크를 접하고 이해하는데 큰 도움 받고 갑니다. 감사합니다.



좋은 글 감사합니다.
https://github.com/spring-projects/spring-boot/issues/36087
위 이슈와 함께 읽어보면 더욱 좋을 것 같습니다.
두 글을 읽어보고 정리해보면,
NIO 기반으로 동작하는 임베디드 톰캣에서는 설정한 대기열이 꽉 차더라도, connectionTimeout 이 나기 전까지는 요청에 대해 대기하다가, 유휴 스레드가 나오면 작업을 할당 시킨다. timeout 에 의존하므로 사실 상 unbounded queue 로 동작한다.
이 정도로 정리할 수 있을 것 같네요.
springboot 3.x 에 server.tomcat.threads.max-queue-capacity 옵션이 추가 예정이고, 해당 옵션 설정을 0으로 설정하면 bounded queue 로 동작되도록 개선한다고 하네요. :)


Thread Pool 개념 정리에 좋은 참고가 되었습니다 감사합니다!
다만 글을 읽다가 한가지 의문이 있는데요 글 내용중에 "accept-count는 작업큐의 사이즈 입니다. 스프링 부트에선 아무 옵션을 안주면 Integer.MAX, 즉 21억 블라블라를 줬습니다." 해당 부분을 보고 제가 테스트해보니 accept-count를 따로 설정하지 않아도 Integer.MAX값이 아닌 100으로 설정되는 것을 확인했습니다.
Spring Enviroment 영역으로 볼 수 있는 Tomcat in ServerProperties 클래스를 까보면 acceptCount = 100이라고 설정되어 있는것도 확인되구요 답변주시면 감사하겠습니다.
정말 내용이 너무너무너무 좋네요! 잘읽고 갑니다 큰 도움 되었습니다 :)