
🖐️ 시작하며
Next.js는 React 기반 대표적인 프레임워크중의 하나로 SSR을 통해 SEO 최적화에 유리해서 많은 사랑을 받고 있는 프레임워크 입니다. 특히 서버컴포넌트의 활용성이 무궁무진해서 CSR, SSR, SSG 등 개발자가 원하는 방식으로 렌더링 최적화가 가능하기 때문에 강점이 매우 돋보이는 프레임워크입니다.
최근 프로젝트 캠프를 수료하면서 진행했던 프로젝트에서 Next.js의 App router 기반 온라인 스터디 서비스를 제작했었습니다. 프로젝트를 진행하면서 가장 많이 고찰했던 부분 중 하나가 next app router 환경에서의 데이터 페칭 관련 내용이었습니다.
next.js에서는 기본적으로 데이터 페칭용 fetch 함수를 제공합니다. react-query의 대표적인 강점인 caching, refetching 등도 동일하게 지원합니다. 그렇다고 서버컴포넌트 환경에서는 react-query나 swr등의 데이터 페칭 라이브러리가 필요 없는 것일까요?
저는 마냥 정답이 아니라고 생각했습니다. fetch 함수의 강점도 있지만 react-query의 장점 또한 무시할 수 없고 서버컴포넌트 환경이 100퍼센트 안정된 상태가 아니라고도 생각했기 때문입니다. 프로젝트를 진행하면서 위 내용에 대해 어떤 부분들을 고민했는지에 대해 공유해보려 합니다.
서버컴포넌트? fetch?
React Server Component(RSC)는 react 18버전에 도입된 기술로 서버에서 렌더링을 마친 이후 브라우저로 넘어오는 컴포넌트를 의미합니다. 이와 반대되는 개념인 클라이언트 컴포넌트는 기존 리액트에서 사용하던 컴포넌트들을 의미합니다.
RSC가 해결해주는 기존의 문제점은 크게 2가지가 있습니다.
- 기존 클라이언트 컴포넌트의 데이터 페칭 waterfall 현상
- 데이터 페칭 라이브러리 도입으로 인한 번들 사이즈 증가
위와 같은 문제점들을 해결하기 위해 서버컴포넌트는 서버에서 데이터 페칭이 이루어지고 이후에 렌더링이 이루어지게 함으로써 waterfall 현상을 최소화하고, 자체적인 데이터 페칭 함수인 fetch 함수를 제공함으로써 라이브러리 도입 없이도 데이터 페칭이 이루어지게 구성했습니다.
더 자세한 내용은 공식문서에서 확인하실 수 있습니다.
Next.js에서의 데이터 페칭
Next.js의 app router는 위에서 알아본 서버컴포넌트 개념을 기반으로 데이터 fetching이 이루어집니다.
async, await를 활용해 fetch 함수로 데이터를 비동기적으로 fetching하는 기본 구조를 가지고 있습니다. 아래 코드는 기본적인 next.js app router 데이터 fetching 로직입니다.
// app/page.tsx
async function getData() {
// 해당 url은 존재하지 않는 api url이므로 url을 바꿔서 테스트하시기 바랍니다.
const response = await fetch("https://api.url.com/");
if(!res.ok){
throw new Error("data fetch error");
}
const data = await response.json();
return data;
}
export default async function Page(){
const data = await getData();
return (
<div>
<h1>{data.title}</h1>
</div>
)
}또한 데이터 fetching 과정에서의 강점인 caching과 revalidate 지정을 통한 자동 refetch 기능도 제공합니다.
caching
const response = await fetch("https://api.url.com/", { cache: "force-cache" | "no-store" });force-cache (기본값) - 데이터 캐시에서 일치하는 요청을 찾습니다
- 일치하는 항목이 있고 최신 데이터 상태이면 캐시에서 반환합니다
- 일치하는 항목이 없거나 오래된 항목인 경우 원격 서버에서 리소스를 가져와 다운로드한 리소스로 캐시를 업데이트 합니다.
no-store - 캐시를 확인하지 않고 모든 요청을 원격 서버에서 리소스를 가져오고, 다운로드한 리소스로 캐시를 업데이트하지 않습니다.
revalidate
const response = await fetch("https://api.url.com/", { next: { revalidate: false | 0 | number });false - 리소스를 무기한 캐시합니다.
0 - 리소스가 캐시되는 것을 방지합니다.
number - 리소스의 캐시 수명이 최대 number초임을 지정합니다.
이와같이 RSC에서 제공하는 fetch 함수는 react-query가 지원하던 데이터 fetching의 장점들을 지원해줍니다.
하지만 fetch 함수가 react-query를 완벽히 대체할 수 없을 뿐더러 axios의 모든 부분들 대체해줄 수도 없습니다. 다만 대부분의 사용 방식은 동일하게 지원하기에 어느정도 일임할 수는 있음을 알 수 있습니다.
그럼 react-query 필요 없는거 아냐?
결론부터 말씀드리자면 고도화 되지 않은 mvp 버전의 서비스라던지, 기능이 가벼운 서비스에서는 next.js에서 제공하는 fetch 함수만 사용해서 구현하는게 훨씬 간단하고 편리합니다.
하지만 조금 더 다양한 기능들을 사용자에게 제공하고 서비스의 최적화를 원한다면 react-query의 선지도 고민해볼만 합니다. 대표적으로 아래 예시의 경우에는 react-query를 고려해봐도 괜찮을 거 같습니다.
- 개인화된 GET 요청이 잦은 서비스
- 무한 스크롤, 낙관적 업데이트가 포함된 서비스
- api 요청 이후 상황별 fallback UI의 선언적 사용이 필연적인 서비스
개인화된 GET 요청
서버컴포넌트에서 제공하는 fetch의 기본 캐시 옵션인 force-cache는 api 요청의 응답을 원격 서버에 캐싱하여 제공합니다. 덕분에 동일한 엔드포인트 기준 api 요청은 캐싱되어 결과를 제공하지만 개인화된 요청에서는 모든 사용자에게 동일한 결과값을 반환하게 됩니다.
예시로 로컬스토리지에 액세스 토큰을 가지고 있는 서비스에서는 api 요청시 액세스 토큰으로 사용자가 누군지 판별합니다. 그렇기에 당연히 A 유저와 B 유저의 액세스 토큰은 다른 값을 가지고 있고 만약 유저가 좋아요를 누른 게시물을 조회하는 api 요청에서는 다른 결과값이 반환되어야 합니다.
하지만 fetch의 force-cache 옵션 사용 시 A 유저든 B 유저든 처음 해당 엔드포인트로 요청한 결과값이 캐싱되고 이후에는 revalidate 타임이 지나기 전까지 항상 동일한 결과값을 반환하게 됩니다.
물론 no-store 옵션을 사용해서 캐싱을 막고 사용자마다 다른 api 요청 값을 반환할 수 있지만, 이 경우 새로 고침이나 캐시 만료시마다 api 호출이 추가적으로 발생하고 비용이 늘어나게 됩니다.
그렇기에 이런 케이스에서는 react-query의 캐싱을 사용해서 유저마다 개인화된 api 요청 자체를 캐싱해놓고 추가 비용 소모 없이 사용하는게 더 유리하기에 react-query의 도입을 고려해볼만 합니다.
추가적으로 react-query와 fetch의 캐싱 차이점을 간단히 알려드리겠습니다.
react-query와 fetch의 캐싱
fetch와 react-query 모두 caching을 지원합니다. 하지만 이 캐싱이 같은 캐싱은 아닙니다. 자세히 찾아보지 않은 상태에서 그저 캐싱이란 단어만 인지하면 "아 둘 다 똑같은 기능 제공하나보다!" 라고 생각하기 쉽지만 캐싱의 목적이 일부 상이합니다.
궁극적인 목적은 동일합니다. react-query와 fetch 모두 동일한 api 엔드포인트를 기준으로 요청이 무수히 일어나면 자원 낭비가 매우 심하기 때문에 캐싱을 사용합니다.
다만 react-query는 클라이언트 사이드에서 일어나는 데이터 fetching 문제를 해결하기 위해서라면 fetch 함수는 데이터 공유가 어려운 서버컴포넌트의 특성에서 오는 데이터 fetching 문제를 해결하기 위함에 초점을 맞춥니다.
| server component fetch | react-query | |
|---|---|---|
| 캐싱의 목적 | 데이터 공유가 어려운 서버컴포넌트에서의 데이터 fetching 문제를 해결하기 위해 | 클라이언트 사이드 데이터 fetching 과정에서의 비용 절감 |
| 데이터 상태 관리 방식 | 엔드포인트와 옵션을 기준으로 관리 | queryKey를 기준으로 관리 |
| 캐싱 스토어 | 서버 store | 클라이언트 query store |
무한 스크롤, 낙관적 업데이트
무한 스크롤과 낙관적 업데이트는 react-query를 사용한다면 간단하게 적용할 수 있는 기술들입니다.
우선 무한 스크롤은 react-query에서 제공하는 infiniteQuery와 JavaScript에서 제공하는 intersection Observer api를 사용하면 쉽게 구현할 수 있습니다. 또한 suspenseInfiniteQuery도 제공하기 때문에 무한 스크롤 과정에서의 로딩 처리도 깔끔히 처리할 수 있습니다.
낙관적 업데이트도 react-query에서 제공하는 getQueryData, setQueryData와 cancelQueries를 사용하면 유저에게 더 좋은 사용자 경험성을 제공할 수 있습니다.
무한 스크롤과 낙관적 업데이트가 메인 주제가 아니기에 자세한 내용은 무한 스크롤 공식 문서와
낙관적 업데이트 공식 문서를 참고하시기 바랍니다.
물론 react-query를 사용하지 않는다고 두 기능들의 구현이 불가능한건 아닙니다. 써드 파티 라이브러리 없이 충분히 react로만 구현 가능하다는 점을 꼭 잊지 마시기 바랍니다.
api 요청의 상황별 fallback UI
해당 장점은 제가 react-query 사용하면서 가장 크게 와닿았던 장점 중 하나입니다. react-query 도입 이전에는 하나의 컴포넌트에서 사용자에게 상황별 ui를 제공하기 위해 최소 3개의 state가 필요했습니다.
- api 요청 이후 사용자에게 보여줄 state
- api 요청 과정에서의 로딩 처리 관련 state
- api 요청 과정에서 에러 관련 state
해당 state들로 사용자에게 data를 제공할 컴포넌트 코드 예시를 보여드리겠습니다.
import { useState, useEffect } from "react";
const Component = () => {
const [isLoading, setIsLoading] = useState(false);
const [data, setData] = useState();
const [error, setError] = useState();
useEffect(() => {
async () => {
try {
setIsLoading(true);
const { data } = await fetch("https://api.url.com");
setData(data.json());
setError(null);
setIsLoading(false);
} catch (error){
setData(null);
setError(error);
setIsLoading(false);
}
}();
}, []);
if(isLoading){
return <Loading />
}
if(error){
return <Error error={error}/>
}
return <Data data={data} />
}
export default Component추가적인 코드 없이 딱 loading, error, success 상황 별 ui를 제공하는 코드임에도 이정도의 코드가 필요했습니다. 여기서 간단한 로직이 하나씩 추가 된다면 장황한 코드의 컴포넌트가 하나 탄생하게 됩니다.
또한 제가 선호하는 코드 로직 방식은 비즈니스 로직은 custom hook에서 관리하고 컴포넌트에는 UI 로직을 관리하는 방식입니다. 원하는 방식으로 커스텀이 어려울뿐더러 재사용성은 전혀 없는 코드에다가 react 함수형 컴포넌트에서 권장하는 코드도 아니기도 합니다.
위 코드를 react-query와 suspense, error-boundary를 사용해 리팩토링 하면 다음과 같은 코드가 나옵니다.
import { useState, Suspense } from "react";
import { ErrorBoundary } from "react-error-boundary"
const Component = () => {
const { data } = useQuery("data", () => axios("/api.url").then((res) => res.data));
return (
<h1>
{data.name}
</h1>
);
};
const Page = () => (
<ErrorBoundary FallbackComponent={Error}>
<Suspense fallback={<Loading />}>
<Component />
</Suspense>
</ErrorBoundary>
);
export default Page;큰 차이가 없는거 아니야? 라고 느끼는 분들이 있으실 수 있지만 정말 간단한 컴포넌트 구성으로 예시를 들었기에 강점을 못느끼실 수도 있습니다. 하지만 고도화된 서비스일수록 페이지수가 늘어나고 기능이 늘어나면서 컴포넌트 수는 기하급수적으로 늘어나게 됩니다.
대형 프로젝트를 경험해볼수록 로직 분리와 컴포넌트 관리의 어려움을 느끼시는 분이 많을거라 생각하고 그렇기에 선언형 컴포넌트는 선택이 아닌 필수가 되게 됩니다. 재사용 가능한 컴포넌트와 hook을 고려하는 분들에게는 더 필요하게 됩니다.
그래서?
지금까지 말씀드린 경우의 수들이 꼭 react-query를 사용해야만 구현이 가능한 부분들은 절대 아닙니다. 다만 점점 고도화될 서비스를 생각하면 최적화면이나 더 좋은 사용자 경험 등의 이유를 고려해서 선택할 수 있는 확장성이라고 생각하시면 좋을 거 같습니다.
프로젝트가 최종 목표인 개발자는 당연히 없다고 생각합니다. 프로젝트도 결국 실무에서 사용할 기술들을 학습하는 단계이기에 저희의 최종 단계는 결국 실무에서의 서비스 구축입니다. 많은 사용자들이 사용할 서비스를 만들어야하는게 개발자의 숙명이기에 처음에 말씀드렸던 mvp 단계 서비스, 기능이 가벼운 서비스가 최종 단계는 아니라고 생각했습니다.
그렇기에 해당 프로젝트를 진행하면서 next app router와 react-query의 결합을 고려했고 적용하기로 결심했습니다.
서버 컴포넌트에서의 react-query
React-query는 기본적으로 hook 기반 api를 제공하기 때문에 일반적인 방법으로는 서버컴포넌트에서 사용할 수 없습니다. hook은 클라이언트 컴포넌트에서만 사용할 수 있기 때문입니다.
react-query 공식문서에서는 이 문제점을 해결하기 위해 서버컴포넌트에서 데이터를 prefetch하는 패턴을 권장합니다.
서버에서 query를 prefetch하여 데이터를 포함한 상태로 렌더링을 진행합니다. 이후 해당 데이터를 dehydrated하고 클라이언트단에서 해당 데이터를 cache를 사용해서 rehydration하는 방식으로 사용하는 방식입니다.
공식문서에서 제공하는 예제 코드를 보면서 좀 더 자세하게 설명드리겠습니다. 우선 queryClient를 생성하고 QueryClientProvider로 서비스를 감싸줘야 합니다.
// getQueryClient.ts
import {
isServer,
QueryClient,
defaultShouldDehydrateQuery
} from "@tanstack/react-query";
const DEFAULT_STALE_TIME = 60 * 1000;
function makeQueryClient() {
return new QueryClient({
defaultOptions: {
queries: {
// staleTime을 60초로 잡아서 즉시 refetch 방지
staleTime: DEFAULT_STALE_TIME,
},
dehydrate: {
shouldDehydrateQuery: (query) =>
defaultShouldDehydrateQuery(query) || query.state.status === "pending",
},
},
});
}
let browserQueryClient: QueryClient | undefined = undefined;
export function getQueryClient() {
if (isServer) {
// 서버단에서는 항상 queryClient를 새로 생성
return makeQueryClient();
} else {
// 브라우저에서는 queryClient가 없는 경우 새 queryClient 생성
// 이미 queryClient가 있는 경우 해당 queryClient 사용
// 기존 queryClient를 사용해 caching이 이루어져야 하기 때문
if (!browserQueryClient) browserQueryClient = makeQueryClient();
return browserQueryClient;
}
}
// provider.tsx
"use client";
import type { PropsWithChildren } from "react";
import { QueryClientProvider } from "@tanstack/react-query";
import { getQueryClient } from "@/apis/getQueryClient";
export function QueryProvider({ children }: PropsWithChildren) {
const queryClient = getQueryClient();
return (
<QueryClientProvider client={queryClient}>
{children}
</QueryClientProvider>
);
}// layout.tsx
import QueryProvider from "@/components/provider/QueryProvider";
export default function RootLayout({
children,
}: Readonly<{
children: React.ReactNode;
}>) {
return (
<html lang="ko">
<head />
<body>
<ClientProvider>
{children}
</ClientProvider>
</body>
</html>
);
}이후 query 데이터를 사용할 컴포넌트 상단에서 데이터 prefetch를 진행해주고 HydrationBoundary로 해당 컴포넌트를 감싸줍니다. 그리고 이 결과가 담긴, dehydrated 상태의 queryClient를 하위 컴포넌트인 Posts로 전달합니다.
// page.tsx
import {
dehydrate,
HydrationBoundary,
QueryClient,
} from '@tanstack/react-query'
import Post from '@/components/post'
export default async function PostPage() {
const queryClient = new QueryClient()
await queryClient.prefetchQuery({
queryKey: ['posts'],
queryFn: getPosts,
})
return (
<HydrationBoundary state={dehydrate(queryClient)}>
<Posts />
</HydrationBoundary>
)
}// post.tsx
'use client'
export default function Posts() {
// prefetch 된 query Data로 서버에서 렌더링 될 때 해당 데이터도 확인 가능
const { data } = useQuery({
queryKey: ['posts'],
queryFn: () => getPosts(),
})
// prefetch를 하지 않은 query Data로 서버에서 렌더링을 마치고 클라이언트로 넘어온
// 이후에 클라이언트 단에서 query를 fetching해야 데이터 확인 가능
const { data: commentsData } = useQuery({
queryKey: ['posts-comments'],
queryFn: getComments,
})
// ...
}서버에서 prefetch된 데이터를 활용해서 클라이언트 컴포넌트에까지 pre-render를 진행하게 됩니다. prefetch를 하지 않으면, 서버에서는 useQuery hook을 사용할 수 없기 때문에 전체 렌더링이 끝나고 클라이언트단에서 query가 조회되기 전까지 데이터값은 찾을 수 없습니다. 하지만 서버컴포넌트에서 prefetch를 하게 되면 데이터가 들어간채로 서버에서 렌더링이 진행되기 때문에 데이터가 정상적으로 넘어오게 됩니다.
❗️ 해당 설명은 공식문서를 참고한 내용이 맞지만 매우 간소화된 설명입니다. 더 자세한 내용은 꼭 공식문서를 확인하시기 바랍니다.
프로젝트에서는?
위에서 알아본 내용을 바탕으로 프로젝트에서는 실제로 어떤 변경점이 생겼고 어떤 부분이 개선되었는지 알아보겠습니다. 저희 서비스에서 초반에 사용자가 접하는 페이지중 하나인 스터디 탐색 페이지입니다. 구성은 아래 사진과 같습니다.
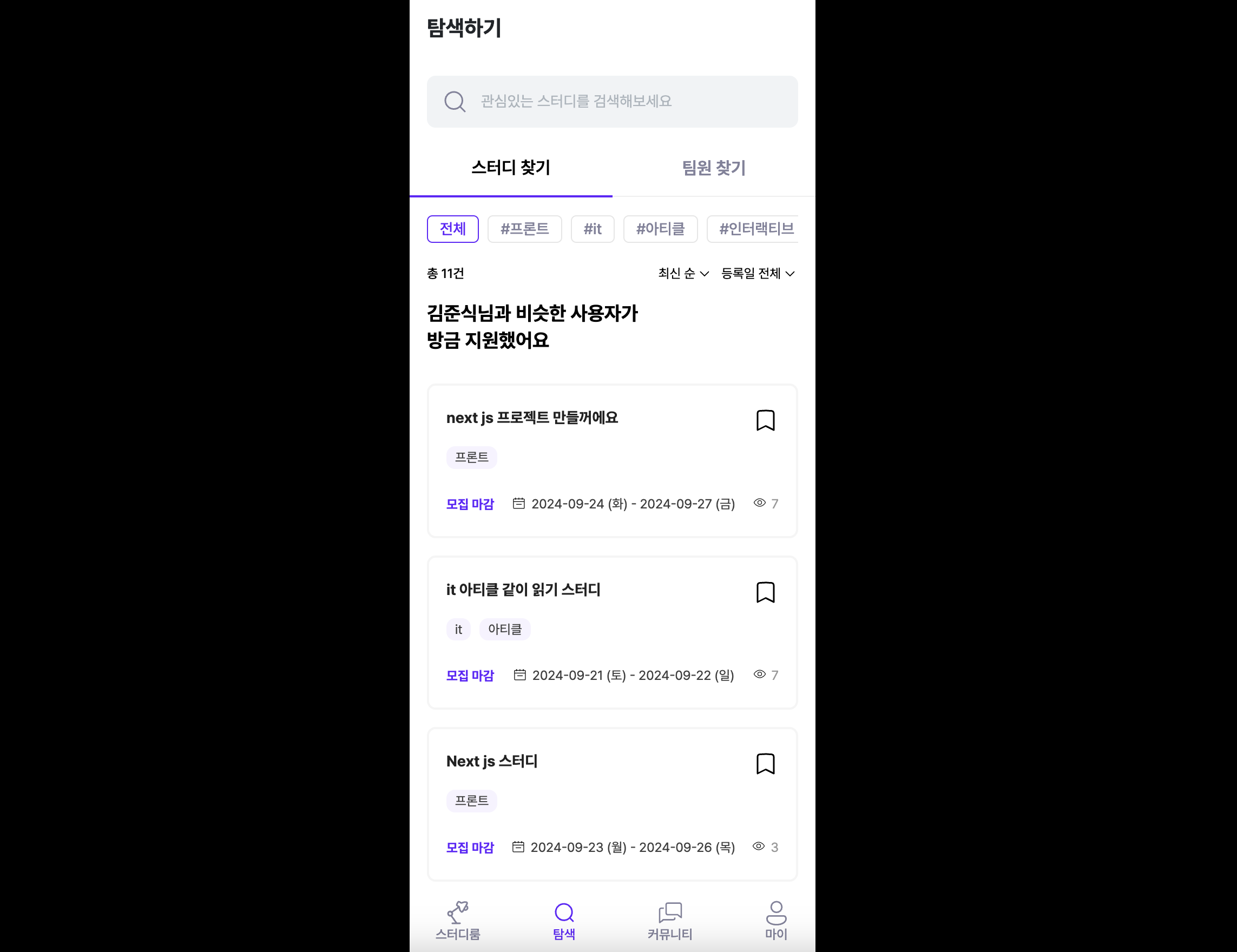
위 화면에서 상단 Header와 하단 GNB는 사용자에게 먼저 보여주고 나머지 요소들을 불러오는 동안 skeleton UI를 사용자에게 제공하여 UX를 개선해보겠습니다.
우선 HydrationBoundary를 선언적으로 사용하기 위해서 ServerFetchBoundary 컴포넌트와 getQueryClient를 만들어줬습니다.
공식문서에서 제공하는 코드와 비슷하지만 한 컴포넌트에서 query를 여러개 사용하는 경우를 고려하여 queryOption을 배열로 받는 코드만 추가했습니다.
해당 서비스의 경우 예를들어 스터디 목록 query와 더불어 스터디의 본인 여부를 위해 유저 정보 query가 같이 필요한 경우 등이 있었습니다.
// getQueryClient.ts
import {
isServer,
QueryClient,
defaultShouldDehydrateQuery
} from "@tanstack/react-query";
const DEFAULT_STALE_TIME = 60 * 1000;
function makeQueryClient() {
return new QueryClient({
defaultOptions: {
queries: {
staleTime: DEFAULT_STALE_TIME,
refetchOnWindowFocus: false,
refetchOnReconnect: false,
retry: 0,
},
dehydrate: {
shouldDehydrateQuery: (query) =>
defaultShouldDehydrateQuery(query) || query.state.status === "pending",
},
},
});
}
let browserQueryClient: QueryClient | undefined = undefined;
export function getQueryClient() {
if (isServer) {
return makeQueryClient();
} else {
if (!browserQueryClient) browserQueryClient = makeQueryClient();
return browserQueryClient;
}
}// ServerFetchBoundary
import type { ReactNode } from "react";
import {
type FetchQueryOptions,
HydrationBoundary,
dehydrate
} from "@tanstack/react-query";
import { getQueryClient } from "@/apis/getQueryClient";
export type FetchOptions = Pick<FetchQueryOptions, "queryKey" | "queryFn">;
type Props = {
fetchOptions: FetchOptions[] | FetchOptions;
children: ReactNode | ReactNode[];
};
export async function ServerFetchBoundary({ fetchOptions, children }: Props) {
const queryClient = getQueryClient();
if (Array.isArray(fetchOptions)) {
for (const option of fetchOptions) {
// 병렬 처리로 단축
await Promise.all(fetchOptions.map(option => queryClient.fetchQuery(option)));
}
} else {
queryClient.fetchQuery(fetchOptions);
}
return (
<HydrationBoundary state={dehydrate(queryClient)}>
{children}
</HydrationBoundary>
);
}이후 서버컴포넌트로 사용할 page 코드를 아래와 같이 작성했습니다.
// app/study-list/page.tsx
import { Suspense } from "react";
import { ServerFetchBoundary } from "@/apis/ServerFetchBoundary";
import Gnb from "@/components/common/Gnb/Gnb";
import Header from "@/components/common/Header/Header";
import ExplorerSkeleton from "@/components/Study/Explorer/ExplorerSkeleton";
import ExplorerTab from "@/components/Study/Explorer/ExplorerTab";
import { studyListQueryOptions } from "@/hooks/api/study/useStudyListQuery";
import { userInfoQueryOptions } from "@/hooks/api/userInfo/useUserInfoQuery";
export default function StudyListPage() {
const serverFetchOptions = [studyListQueryOptions(), userInfoQueryOptions()];
return (
<>
<Header>
<Header.Title>탐색하기</Header.Title>
</Header>
<Suspense fallback={<ExplorerSkeleton />}>
<ServerFetchBoundary fetchOptions={serverFetchOptions}>
<ExplorerTab />
</ServerFetchBoundary>
</Suspense>
<Gnb />
</>
);
}각 query들의 코드는 다음과 같습니다.
// useStudyQuery.ts
import type { UseSuspenseQueryOptions } from "@tanstack/react-query";
import { useSuspenseQuery } from "@tanstack/react-query";
import { httpMethod, createInit } from "@/apis/httpMethod";
import { END_POINTS } from "@/constants/api";
import { QUERY_KEYS } from "@/constants/queryKey";
import type { FilterSelectedType } from "@/types/filter";
import type { GetStudyListResponseType } from "@/types/study";
const getStudyList = async (param?: FilterSelectedType) => {
const queryString = new URLSearchParams(Object.entries(param ?? {}));
const data = await httpMethod<GetStudyListResponseType>(
END_POINTS.STUDY_LIST + `?${queryString}`,
"GET",
createInit(),
);
return data;
};
export const studyListQueryOptions = (
param?: FilterSelectedType,
): UseSuspenseQueryOptions<GetStudyListResponseType> => ({
queryKey: [QUERY_KEYS.STUDY_LIST],
queryFn: () => getStudyList(param),
});
export function useStudyListQuery(param?: FilterSelectedType) {
return useSuspenseQuery(studyListQueryOptions(param));
}// useUserInfoQuery.ts
import type { UseSuspenseQueryOptions } from "@tanstack/react-query";
import { useSuspenseQuery } from "@tanstack/react-query";
import { httpMethod, createInit } from "@/apis/httpMethod";
import { END_POINTS } from "@/constants/api";
import { QUERY_KEYS } from "@/constants/queryKey";
import { createClient } from "@/utils/supabase/client";
import type { GetUserInfoResponseType } from "@/types/userInfo";
const getUserInfo = async (id?: string) => {
let url;
if (id) {
url = END_POINTS.USER_INFO_BY_ID(id);
} else {
const supabase = createClient();
const user = await supabase.auth.getUser();
const userId = user.data.user ? user.data.user.id : "";
url = END_POINTS.USER_INFO_BY_ID(userId);
}
const data = await httpMethod<GetUserInfoResponseType>(url, "GET", createInit());
return data;
};
export const userInfoQueryOptions = (
id?: string,
): UseSuspenseQueryOptions<GetUserInfoResponseType> => ({
queryKey: [QUERY_KEYS.USER_INFO, id ? id : QUERY_KEYS.OWNER_USER],
queryFn: () => getUserInfo(id),
});
export const useUserInfoQuery = (id?: string) => {
return useSuspenseQuery(userInfoQueryOptions(id));
};추가적으로 사용자 인가 토큰을 api 요청에 포함시키기 위해서 handler와 httpMethod를 직접 구성해주었습니다.
// httpMethod.ts
export function createInit<Body extends object>(
token?: string,
body?: Body,
cache: RequestCache = "no-store",
): RequestInit {
return {
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${token}`,
},
body: JSON.stringify(body),
cache,
};
}
async function fetchWithTokenHandler<Data>(uri: string, tokens: string, init?: RequestInit) {
const response = await fetch(`${process.env.NEXT_PUBLIC_API_BASE_URL}${uri}`, init);
if (response.status === STATUS.UNAUTHORIZED) {
const newTokens = await refreshAuth(tokens);
return await fetchWithTokenHandler<Data>(uri, newTokens, {
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${newTokens}`,
},
body: init?.body,
cache: init?.cache,
});
} else if (!response.ok) {
throw new Error(response.statusText);
}
try {
const data = await response.json();
return data as Data;
} catch (error) {
return undefined as any;
}
}
export function httpMethod<Data>(
input: string,
tokens: string,
method: HttpMethod
init?: RequestInit,
) {
return fetchWithTokenHandler<Data>(input, tokens, { method , ...init });
}최종적으로 서비스 전체에서 재사용가능한 서버컴포넌트에서 react-query와 fetch를 결합했으며
개인화된(token을 포함한) 요청까지 할 수 있는 로직을 완성할 수 있었습니다.
물론 코드를 간단히만 살펴보셔도 아시겠지만 보일러 플레이트가 가볍지는 않다는 단점이 있긴합니다. 그렇기에 해당 서비스에서는 과할 수 있지만, 필요 없는 기능은 절대 아니라고 생각할 수 있었습니다.
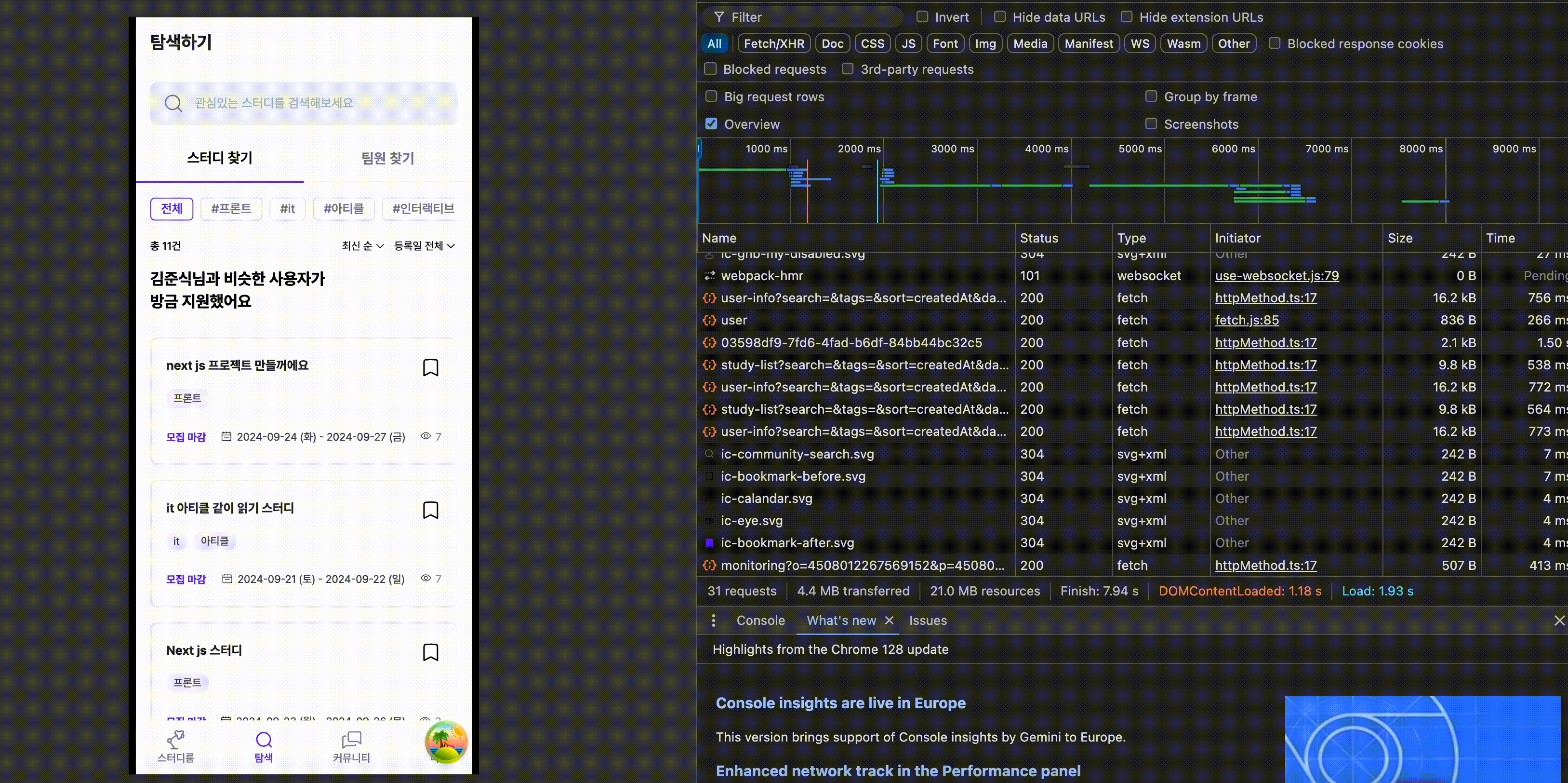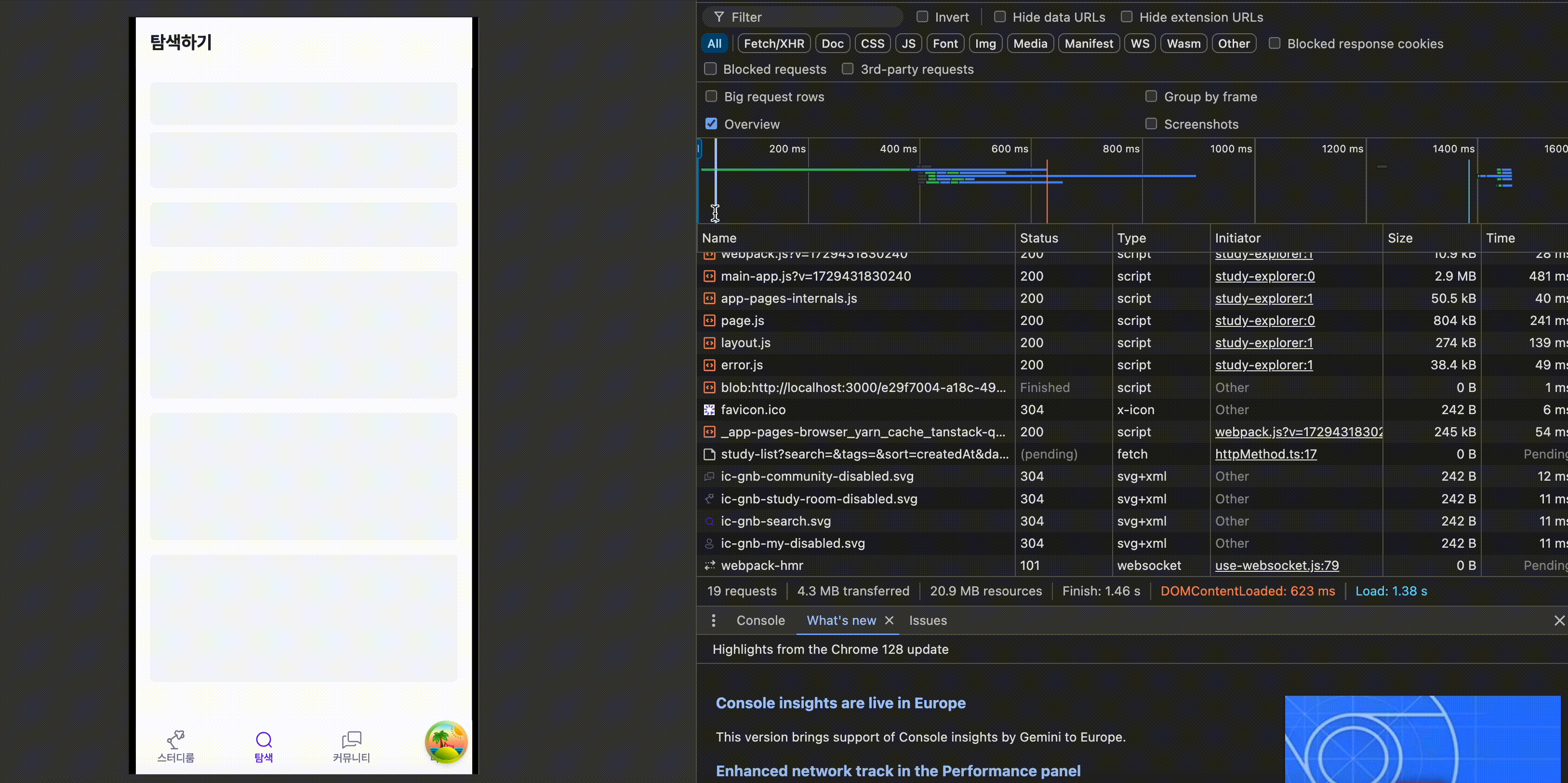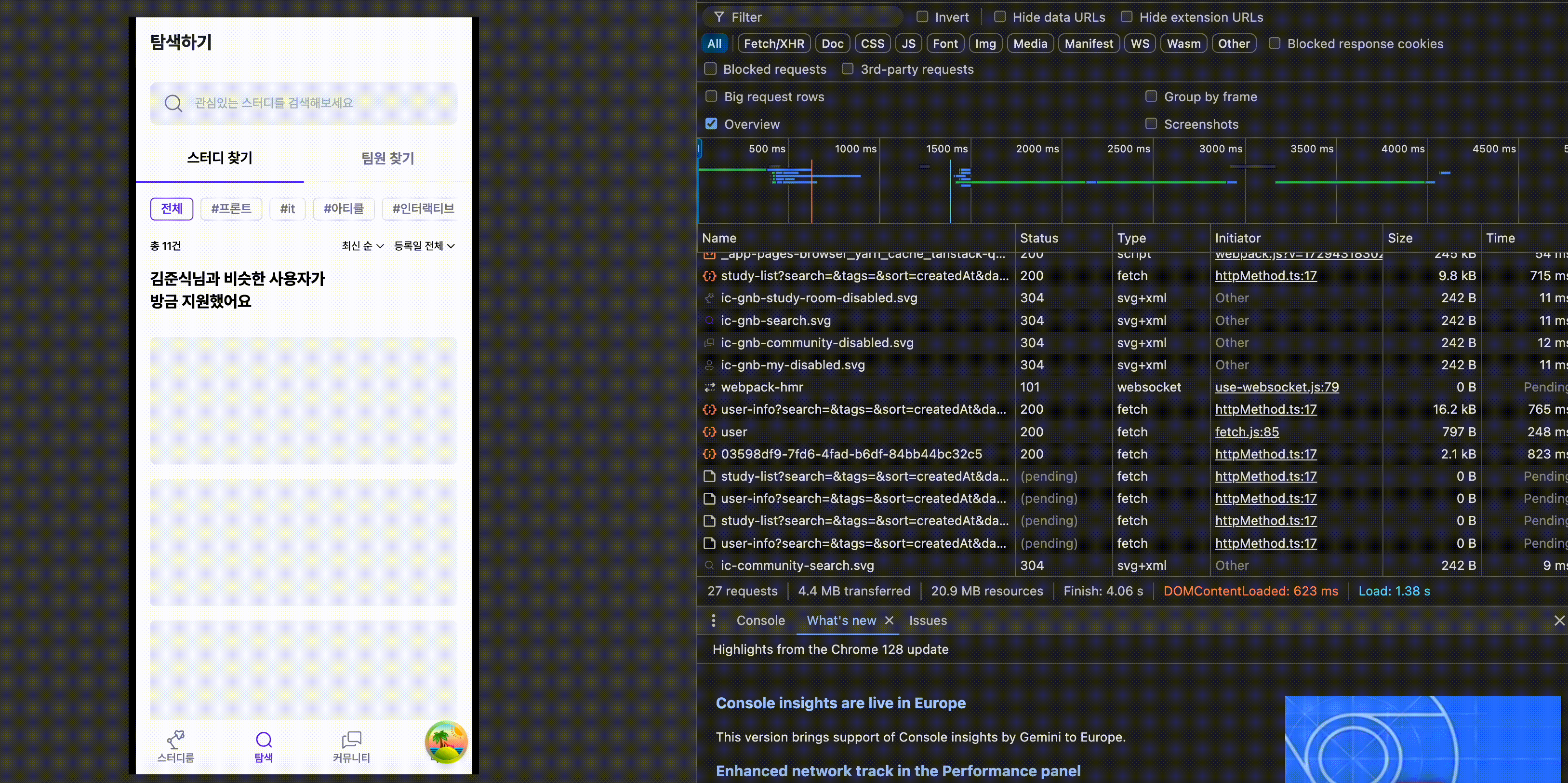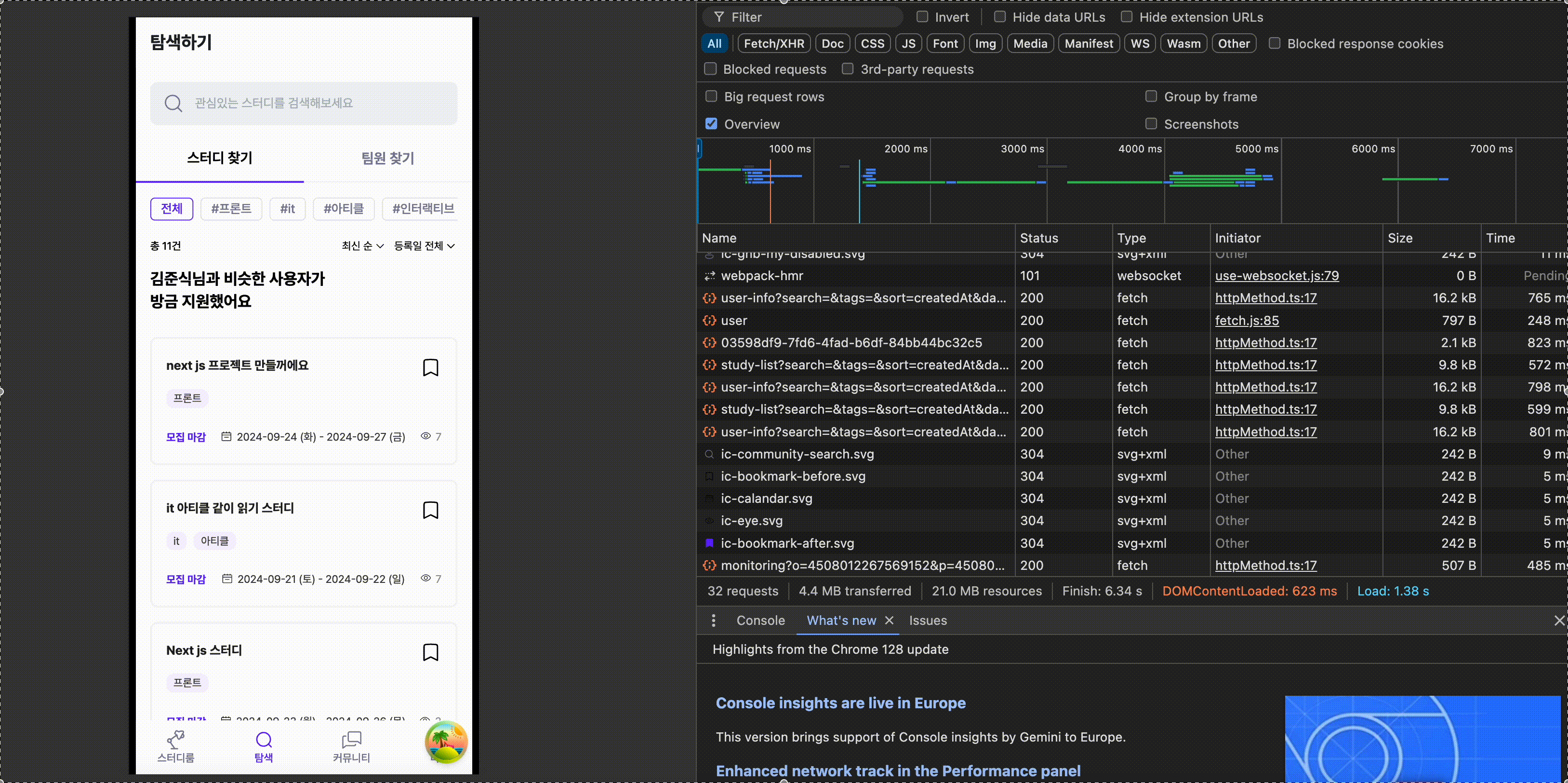
개선 이후 결과물은 다음과 같습니다.
코드 개선 이전
코드 개선 이후
🔚 마치며
Next.js app router에서 react-query가 굳이 필요하지 않다는 의견들이 정말 많습니다. fetch만으로 충분히 서비스 구현이 가능하다는 얘기가 많지만 모든 서비스가 하나의 기술만으로는 해결될 수 없다고 생각합니다.
실생활에서 사용되는 서비스들은 정말 많은 기능들을 제공하고 고도화되어있는 서비스가 많습니다. 그럴수록 사용자의 경험성은 중요해지는데에 비해 최적화는 점점 더 어려워진다고 생각합니다. 개발자로써 서비스를 사용하는 사용자를 위해, 또한 기술적인 발전을 위해 끝없이 학습을 이어가야 한다고 생각합니다.
프로젝트단에서 해당 기술을 사용할 일이 없을 수도 있고 실무에서도 사용하지 않을 수 있습니다. 다만 언젠가 생길 러닝커브라면 고민점이 생겼을 때 파보는게 좋을 거 같다 판단해서 해당 고민들에 대한 학습을 진행했습니다.
항상 정답은 없지만 배워가야할 기술은 많은게 개발자의 숙명이라고 생각하며 오늘도 하나 배우면서 성장해나가는 발판이 될 수 있었던 시간이였던 거 같습니다.
참조
React Server Component 공식문서
https://react.dev/reference/rsc/server-components
Next.js 공식문서
https://nextjs.org/docs
React-query 공식문서
https://tanstack.com/query/latest/docs/framework/react/overview
Next.js에서 fetch와 tanstack-query 효율적으로 사용하기
https://blog.toktokhan.dev/how-to-use-effectivelynext-js-fetchtanstack-query-333c28168e92
React Query 환경에서 Next.js와 streaming 이용하기
https://velog.io/@stakbucks/React-Query%EC%99%80-streaming-%ED%95%98%EA%B8%B0

7개의 댓글

안녕하세요 좋은 글 잘 읽었습니다
덕분에 NextJS 에서 HydrationBoundary 를 사용하는 법에 대해서 감을 잡는데 큰 도움이 되었습니다.
글을 보며 찬찬히 배워나가던 중
export async function ServerFetchBoundary({ fetchOptions, children }: Props) {
const queryClient = getQueryClient();
if (Array.isArray(fetchOptions)) {
for (const option of fetchOptions) {
await queryClient.fetchQuery(option);
}
} else {
await queryClient.fetchQuery(fetchOptions);
}
return (
<HydrationBoundary state={dehydrate(queryClient)}>
{children}
</HydrationBoundary>
);
}이 부분에서 fetch 의 실행 유무를 await 할 필요가 없더군요 !!
이미 위에서 설정한 getQueryClient 메소드에서 dehydrate 옵션에서 펜딩 상태의 쿼리들도 dehydrate , hydration 과정을 거치게 되는거 같더라고요

글 잘 읽었습니다.
+) "react-query와 fetch의 캐싱" 문단의 표에서 "데이터 캐싱 상태 관리 방식" 행의 내용이 서로 바뀐 것 같아서 말씀드려요