기본 데이터타입, 배열, 비트맵
1.기본 데이터 타입
크기(size)와 해석(inerpretation)이 존재
크기는 bit수 => long, long long, unsigned...
해석은 data type => char, int, float...

C언어 data type
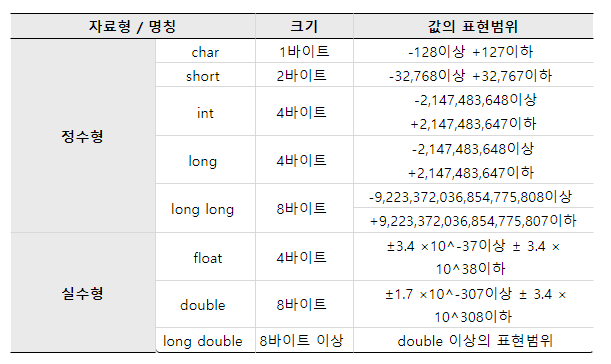
char = 1바이트 = 8비트 = 256
int = 4바이트 = 32비트 = 4,294,967,296
signed = 부등호 표현
unsigend = 부등표현하지 않는 타입
java data type
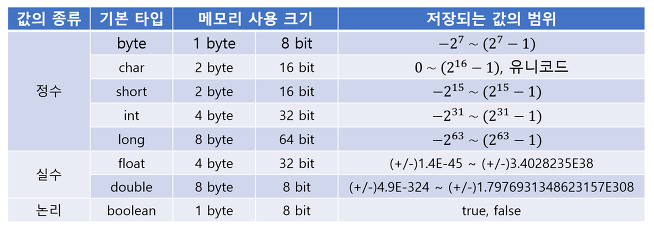
유니코드를 포함한 char이기 때문에 C언어보다 높은 비트수를 가집니다.
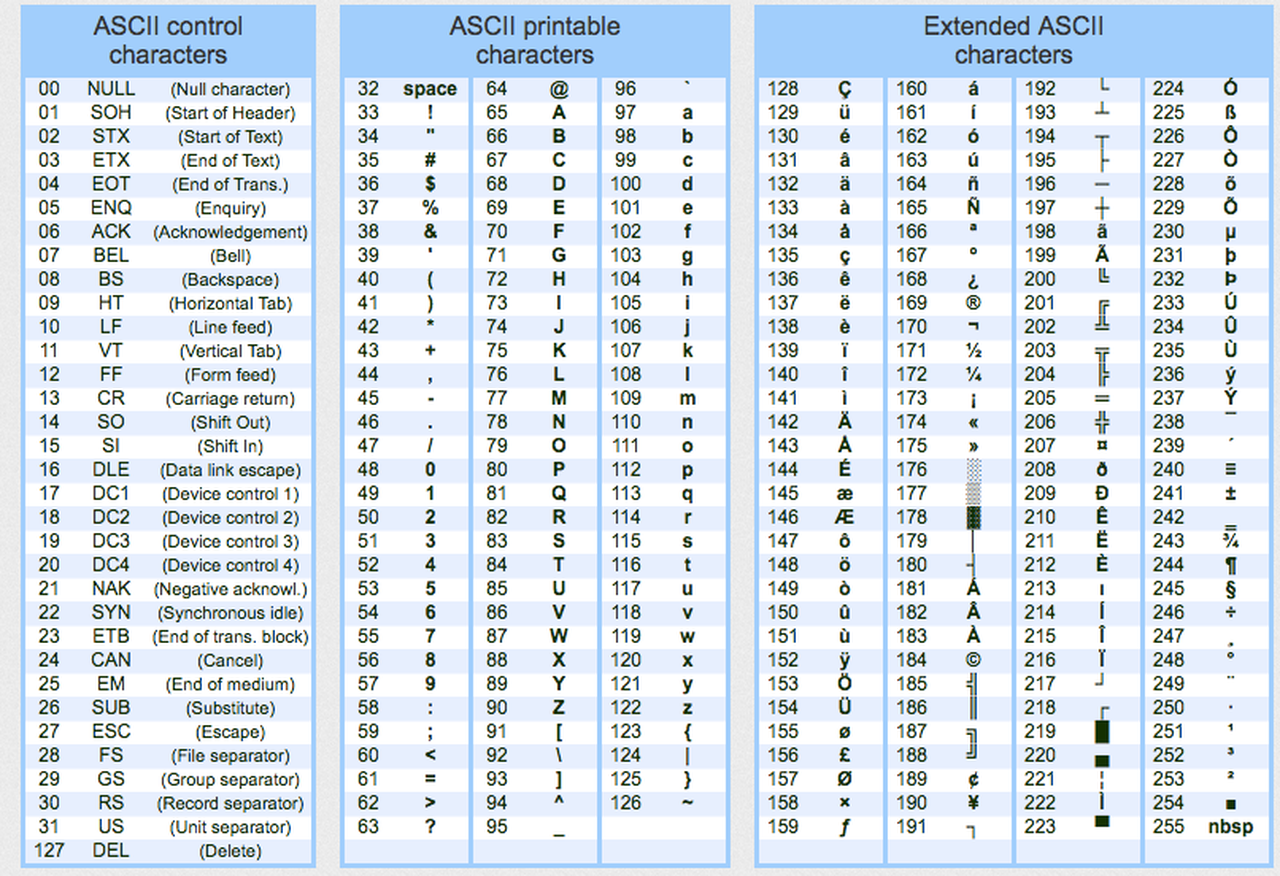
아스키코드
포인터란?
메모리 상에 위치한 특정한 데이터의 (시작)주소값을 보관하는 변수
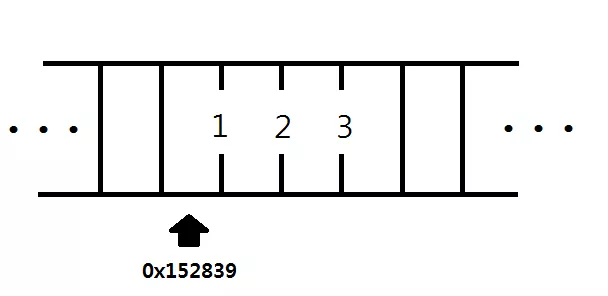
int p = 123 // 123 저장int 123이 메모리 주소에 저장된 상태
메모리주소의 시작점 = 0x152839
int* p // p의 메모리시작주소를 가리킴
포인터 p 에 들어 있는 값 : 0x7fff894c8b3c
int 변수 a 가 저장된 주소 : 0x7fff894c8b3c 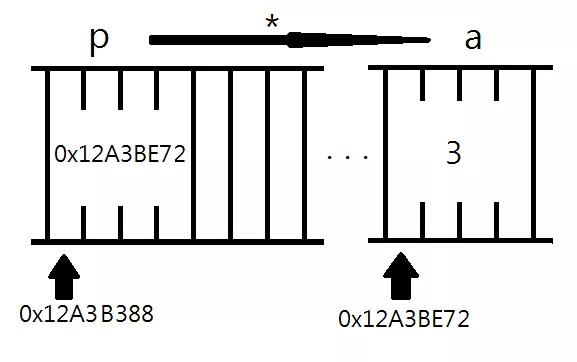
포인터의 장점
-
메모리 주소를 참조하여 배열과 같은 연속된 데이터에 접근과 조작 용이
-
동적 할당된 메모리 영역(힙 영역)에 접근과 조작 용이
-
한 함수에서 다른 함수로 배열이나 문자열을 편리하게 보낼 수 있음
-
복잡한 자료구조를 효율적으로 처리
-
메모리 공간을 효율적 사용
-
call by reference에 의한 전역 변수의 사용을 억제
포인터의 단점
-
포인터 변수는 주소를 직접적으로 컨트롤하기 때문에 예외 처리가 확실하지 않을 경우 예상치 못한 문제가 많이 발생. ( 널 포인트 같은 경우에 바로 접근할 경우 예외 발생)
-
선언만 하고 초기화를 하지않을 경우 쓰레기 주소를 가리키고 있기 때문에 사용에 주의해야 함.
-
포인터 변수는 주소를 직접 참조하기 때문에 의도하지않게 원본의 값이 수정 될 수 있다.
-
오류를 범하기 쉽고 기교적인 프로그램이 되기 쉽다.
-
프로그램의 이해와 버그 찾기가 어렵다.
-
메모리 절대 번지 접근 시 시스템 오류를 초래한다.
2. 배열
배열이란?
컴퓨터 메모리 상에 같은 타입의 변수를 연속적으로 여러 개를 한 꺼번에 정의할 수 있는 방법을 제공하고 있는데 이를 바로 배열(Array) 이라고 합니다.
ex) int형 자료 10개의 원소를 가지고 있는 배열
int arr[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
arr[3] = 4
arr[10] = ???
문자열
"abc" = {'a','b','c'} + null 4바이트 사용
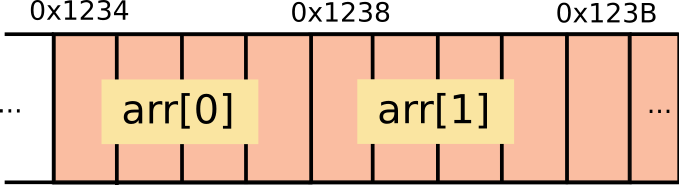
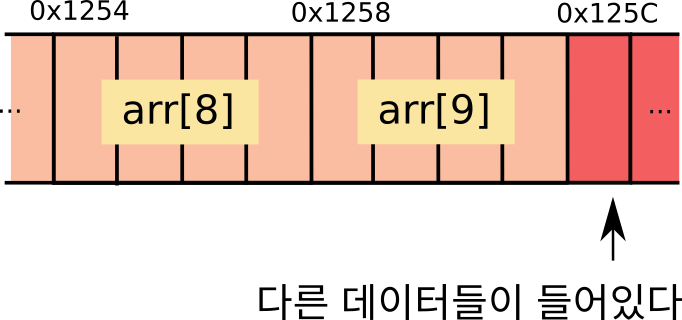
2차원배열 형태
1차원배열형태
int arr [10] = {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19}
2차원 배열형태
int arr[10][2] = {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19}
int arr[10][2] = {
{0,1},
{2,3},
{4,5},
{6,7},
{8,9},
{10,11},
{12,13},
{14,15},
{16,17},
{18,19}
}각 원소는 원소의 주소인 기저주소로부터 얼마나 떨어져있는지를 나타내는 오프셋으로 지정할 수 있다.
int arr[3] = 4
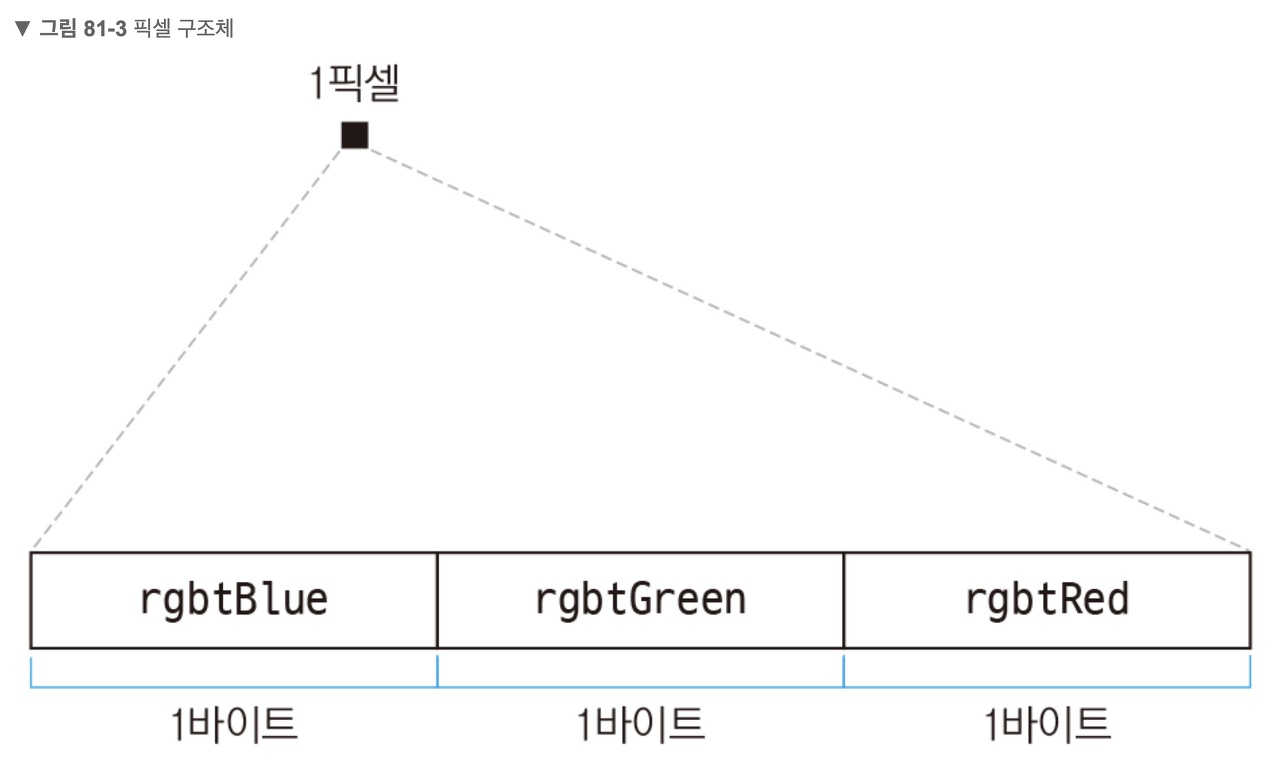
만약 char[3] = 25777 를 담는 다면?3. 비트맵
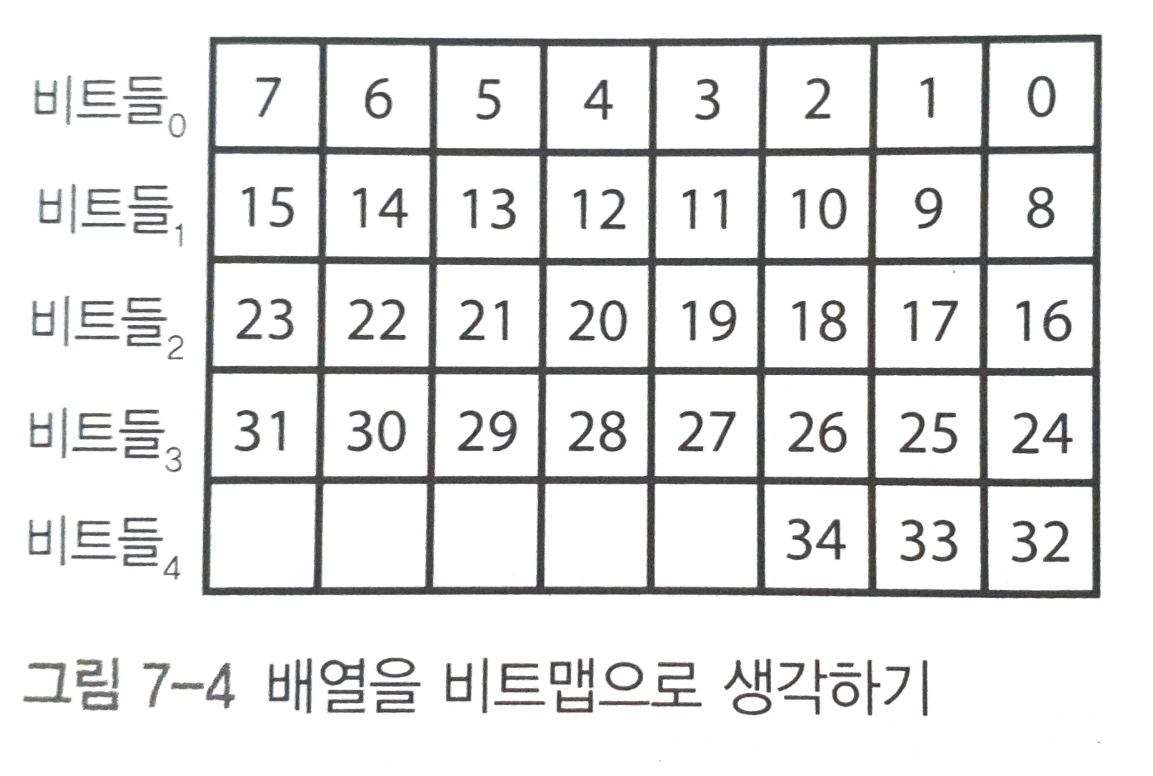
17 => 00010001
8비트 => 00000001
17 and 8비트 => 00010001 AND 00000111 => 00000001
1이 하나
1개수만큼 왼쪽시프트 => 00000010 => 2
2번째에 위치한다!

d