사이드 프로젝트에서 게시물 검색을 할 수 있는 기능이 필요했다.
관계형 DB로만 구현할지 ElasticSearch를 도입할지 고민을 많이 했었다.
일단 둘의 차이점부터 설명하겠습니다
관계형 DB 활용
먼저 관계형 DB를 활용하는 방법입니다. 장점은 매우 명확하게 단순하게 구현을 할 수 있습니다. 하지만 단점도 존재합니다
- 제한된 검색 기능 : Like 연산자로 복잡한 검색 요구사항 충족하기 힘듬
- 성능 이슈 : 데이터가 많아질수록 검색 쿼리 성능이 떨어짐
- 확장성 제약 : 검색 기능 확장 시 노력 필요
- 한글 검색 한계 : 한글 형태소 분석 불가능
이렇게 단점이 존재합니다. 제일 먼저 눈에 들어온 것은 제한된 검색 기능과 성능 이슈쪽이였습니다.
기술스택과 포지션 등으로 복잡한 검색이 많아질 시 요구사항을 완전히 충족하기 힘들다고 생각하였습니다.
비록 지금 MVP 단계로 개발하고 있고 지금은 제목과 글 내용에 대한 검색만 하기에는 충분하지만, 확장성을 고려했을 때는 조금 기능이 떨어진다고 생각하였습니다.
그래서 결국에는 ElasticSearch를 도입하기로 하였습니다.
ElasticSearch 활용
엘라스틱 서치의 장점을 간략하게 말해보겠습니다.
- 고급 검색 기능 : 부분 일치, 유사 검색, 오타 교정 기능
- 검색 성능 : 인덱싱을 통한 최적화된 검색 성능
- 검색 품질 : 연관성 점수를 통한 더 정확한 검색 결과 제공
- 필터링과 정렬 : 다양한 조건으로 필터링
위 4개의 장점이 지금 하고 있는 프로젝트에 꼭 필요한 부분들이라고 생각했습니다.
ElasticSearch 설정 및 기능 도입에 대해서도 설명하겠습니다.
ElasticSearch 어떻게 쓰는거야?
먼저 저희 프로젝트는 Spring 3.3.x와 자바 17, Gradle을 사용하고 있습니다.
Gradle과 yml설정부터 해줍니다.
implementation 'org.springframework.boot:spring-boot-starter-data-elasticsearch'spring:
elasticsearch:
uris: http://localhost:9200
username: your_username
password: your_password그런 다음 검색을 할 데이터에 관해서 Document를 만들어줘야합니다.
@Document(indexName = "projects")
@NoArgsConstructor
@Data
public class ProjectDocument {
@Id
private Long id;
@Field(type = FieldType.Text, analyzer = "standard")
private String title;
@Field(type = FieldType.Text, analyzer = "standard")
private String content;
}그리고 엘라스틱 서치에 관한 Repository를 따로 만들어줘야합니다.
public interface SearchProjectRepository extends ElasticsearchRepository<ProjectDocument, Long>{
List<ProjectDocument> findByTitleContainingOrContentContaining(String title, String content);
}보통은 JPA를 상속받지만 저희는 엘라스틱 서치를 사용하기 때문에 ElasticsearchRepository를 상속받아줍니다. 그리고 찾을 document를 가져와 줍니다.
검색을 하기위한 앤드포인트와 서비스를 만들어보겠습니다. 검색에 관한 키워드는 requestparam으로 넘겨줍니다
public class SearchController {
private final SearchService searchService;
@GetMapping("/search")
public List<SearchResultDto> search(@RequestParam String query, @RequestParam(required = false) String type) {
return searchService.search(query, type);
}
}
public class SearchService {
private final SearchProjectRepository searchProjectRepository;
public List<SearchResultDto> search(String query, String type) {
List<SearchResultDto> results = new ArrayList<>();
if (type == null || type.equalsIgnoreCase("project")) {
List<ProjectDocument> projects = searchProjectRepository.findByTitleContainingOrContentContaining(query, query);
log.info("검색 쿼리 '{}' 결과: {} 개의 프로젝트 찾음", query, projects.size());
results.addAll(projects.stream()
.map(SearchResultDto::fromProjectDocument)
.toList());
}
//todo pr 검색도 추가
return results;
}
}앤드포인트에서는 제일 중요한건 query이기에 필수로 받아줍니다. 얘네가 후에 제목과 내용중에서 해당되는 것을 찾아줍니다. type은 저희 프로젝트 특성상 어떤 글인지 타입을 나눈거라서 필수로 받아올 필요는 없습니당.
그리고 이제 service에서 결과를 list로 저장을 해서 뿌려줄겁니다.
게시글을 올릴 때마다 JPA는 저장이 되는데 엘라스틱 서치에도 동기화가 필요합니다. 그래야 검색을 할 수 있으니까... 그래서 메서드를 하나 추가해줄겁니다.
public void saveProject(Project project) {
ProjectDocument projectDocument = ProjectDocument.fromProject(project);
searchProjectRepository.save(projectDocument);
log.info("프로젝트 ID {} Elasticsearch에 인덱싱 완료", project.getId());
}이 메서드를 생성, 업데이트되는 곳에 JPA에서 생성되거나 업데이트된 후 다시 세이브를 해줘야합니다.
이렇게 하면 간단하게 엘라스틱 서치로 검색이 가능합니다!
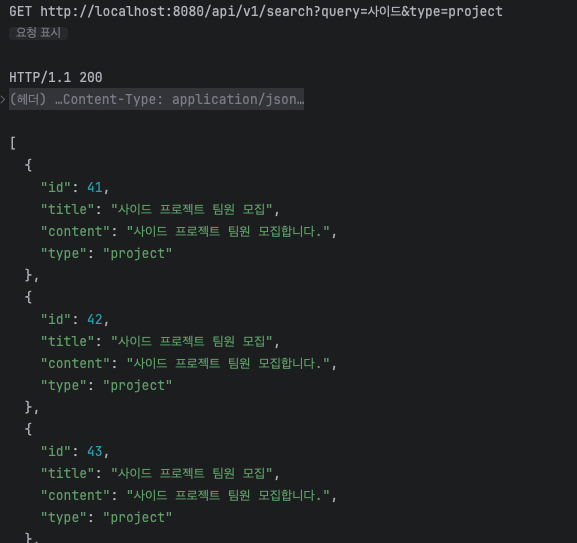
트러블 슈팅
- repository 상속 문제
elasticsearch를 도입하고 서버를 실행할 때 문제가 생겼습니다.
에러 로그
The bean 'projectRepository', defined in com.example.sideproject.domain.project.repository.ProjectRepository defined in @EnableJpaRepositories declared on JpaRepositoriesRegistrar.EnableJpaRepositoriesConfiguration, could not be registered. A bean with that name has already been defined in com.example.sideproject.domain.project.repository.ProjectRepository defined in @EnableElasticsearchRepositories declared on ElasticsearchRepositoriesRegistrar.EnableElasticsearchRepositoriesConfiguration and overriding is disabled.원인은 JPARepository와 ElasticSearchRepository는 둘다 Repository 인터페이스를 상속받아 구현된 인터페이스입니다. 그래서 auto configuration을 통해 Spring 서버를 실행시킬 시 Spring은 Spring Data JPA를 실행시켜 repository 인터페이스를 상속받아 구현된 repository bean들을 전부 찾아 configure 하려고 하기 때문에 충돌이 나는겁니다.
해결방안은 패키지 분리를 하면 되긴하는데 레포지토리가 많으면 하나하나 다 해야한다고 하더라구요...
@EnableJpaRepositories(basePackages = {
"com.example.sideproject.domain.project.repository",
"com.example.sideproject.domain.user.repository",
....
})
@EnableElasticsearchRepositories(basePackages = "com.example.sideproject.domain.search.repository")이걸 해결하니 다른 문제가 발생했습니다.
- 인덱싱 문제
위에 한 것처럼 처음에 구현을 해놓고 신나게 api 테스트를 했지만 결과는 [] 빈 배열이였습니다.
왜일까 생각을 해보다가 데이터가 안들어갔구나라는 결론이 나왔습니다.
그래서 해결책으로는 서버가 먼저 켜질 때 데이터를 인덱싱하는 방법을 선택하였습니다.
ElasticsearchConfig를 하나 만들어줍니다.
public class ElasticsearchConfig {
private final ProjectRepository projectRepository;
private final SearchProjectRepository searchProjectRepository;
@Bean
//서버 실행될 때 JPA에서 인덱싱한걸 엘라스틱 서치에 저장
public CommandLineRunner indexProjectsOnStartup() {
return args -> {
try {
long count = searchProjectRepository.count();
if (count == 0) {
log.info("Elasticsearch에 인덱싱된 프로젝트가 없습니다. 초기 인덱싱을 시작합니다...");
List<Project> allProjects = projectRepository.findAll();
List<ProjectDocument> documents = allProjects.stream()
.map(ProjectDocument::fromProject)
.toList();
searchProjectRepository.saveAll(documents);
log.info("초기 데이터 인덱싱 완료: {} 개의 프로젝트 인덱싱됨", allProjects.size());
} else {
log.info("이미 {} 개의 프로젝트가 인덱싱되어 있습니다.", count);
}
} catch (Exception e) {
log.error("초기 데이터 인덱싱 중 오류 발생: {}", e.getMessage(), e);
}
};
}
}이렇게 해두면 스프링 서버가 부팅될 때 알아서 가져와줍니다.
