내가 바라보는 그놈의 클린아키텍처
머릿속으로만 알고있는 개념들을 정리하기 위해서 정리를 해보려고 합니다.
클린아키텍처의 공통적인 목표는 관심사의 분리입니다.
이를 동작하기 위해서는 의존성 규칙을 지켜야 합니다.
의존성 규칙은 무엇일까요?
의존성 규칙이란 모든 소스코드 의존성은 반드시 외부에서 내부로, 고수준 정책을 향해야 합니다.
이 문장부터 어려운데 고수준 ( 상위 수준의 개념) 들은 저수준(구체화된 세부 개념)의 변경에 영향을 받지 않는다는 의미입니다.
더 쉽게 예를들어봅시다.
서울시에 맥도날드 지점을 찾는 코드가 있습니다.
종로구에 이벤트가 발생해서 종로구에 맥도날드 지점을 찾는 코드를 변경했습니다.
이걸 변경한다고 하여도 서울시에서 맥도날드 지점을 찾는 코드는 변경되면 안된다는 의미입니다.
클린아키텍처는 결국 전체의 계층을 3개로 분리하였습니다.
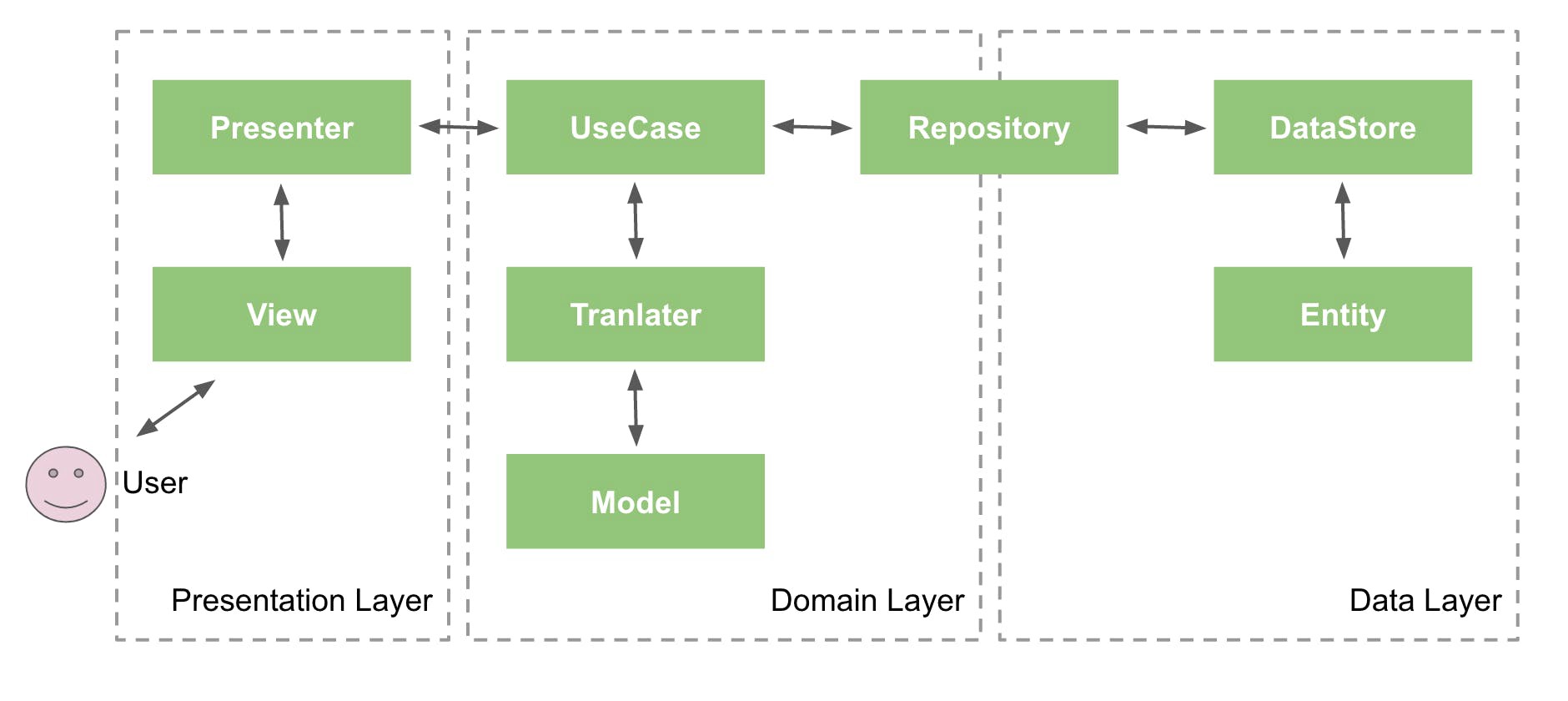
클린아키텍처를 검색하면 매우 자주 나오는 이미지입니다.
- Pressentation Layer
화면의 표시,애니메이션,사용자 입력 처리등 UI에 관련된 모든 처리를 갖고있습니다.
View - UI화면 표시와 사용자의 입력담당을 합니다. 자기가 화면에 그리는 것의 의미를 모르고, 프레젠터의 명령을 받아 화면을 어떤 이미지,색으로 그릴지 결정하는것뿐입니다.
헷갈리지 말아야 할것은 View가 꼭 Activity/Fragment를 의미하는것은 아닙니다.
Presenter - MVP에서 말한는 P 가 아닙니다. 좀 더 넓은 의미입니다. Presenter에는 ViewModel도 포함될수 있습니다. 직접적으로 플랫폼에 의존하지 않습니다. 프레젠터는 화면에 그리는 것이 어떤 의미를 가지고 있는지를 알고 있으며 입력이 들어왔을때 어떤 반응을 해야하는지도 담당하고있습니다.
- Domain Layer
UseCase - 비즈니스 로직입니다.
Model - 앱의 실질적인 데이터가 구현되어있습니다. REST API등으로 얻어지는 외부 데이턴는 포함되지 않습니다.
Translater - 데이터 계층의 엔티티 - 도메인 모델을 변환하는 mapper역할을 합니다.
- Data Layer
Repository - 유스케이스가 필요로 하는 데이터 저장/수정 등의 기능을 제공하는 클래스입니다.
데이터 소스를 인터페이스 형태로 참조하기 때문에 이 클래스에서 데이터소스 객체를 갈아끼우는 형태로, 외부 API 호출/로컬 DB 접근/mock object 출력을 전환할 수 있습니다.
Data Source - 실제 데이터의 입출력이 여기서 실행됩니다.
Entity - 데이터 소스에서 사용되는 데이터를 정의한 모델로, 맨 위의 과녁 그림에서의 엔티티와는 다른 개념입니다. REST API의 요청/응답을 위한 JSON, 로컬 DB에 저장하기 위한 테이블이 대표적입니다.
어려운 용어는 충분히 나열했고 그래서!
그래서 목적이 무엇인가?
계층을 분리하고 클린아키텍처... 좋은건 알겠습니다. 그래서 이점이 무엇인가요?
분량이 큰 앱일지라도 소스코드를 쉽게 파악할수 있다는 이점이 있습니다!
파악한다는게 무슨 의미죠?
- 수정사항, 에러가 발생했을때 어디를 고쳐야하는지 금방 파악할 수 있습니다.
- 다른 개발자들이 보아도 쉽게 이해할 수 있습니다.
- 특정 부분의 수정이 다른 부분에 영향을 거의 주지 않습니다.
사실 이 개념을 정리하면서 크게 와닿는 부분은 3번입니다. 만약 스파게티처럼 이렇게 저렇게 엮여있고 이걸 구분되어있지 않다면 수많은 버그가 터질거고 수정하는 것에 상당한 시간을 할애해야할것입니다.
