1. 데이터 베이스
📍 컴퓨터 시스템에 저장된 정보나 데이터를 모두 모아 놓은 집합
데이터베이스를 사용하는 이유는 데이터를 휘발성으로 사라지게 하지 않고, 오래 기간 저장하며, 동시에 체계적으로 보관하기 위해서입니다.
2. RDBMS
📍 관계형 데이터베이스에서 모든 데이터는 2차원 테이블(table)로 표현할 수 있습니다.
📍 각 로우는 저만의 고유 키(Primary Key)가 있습니다.

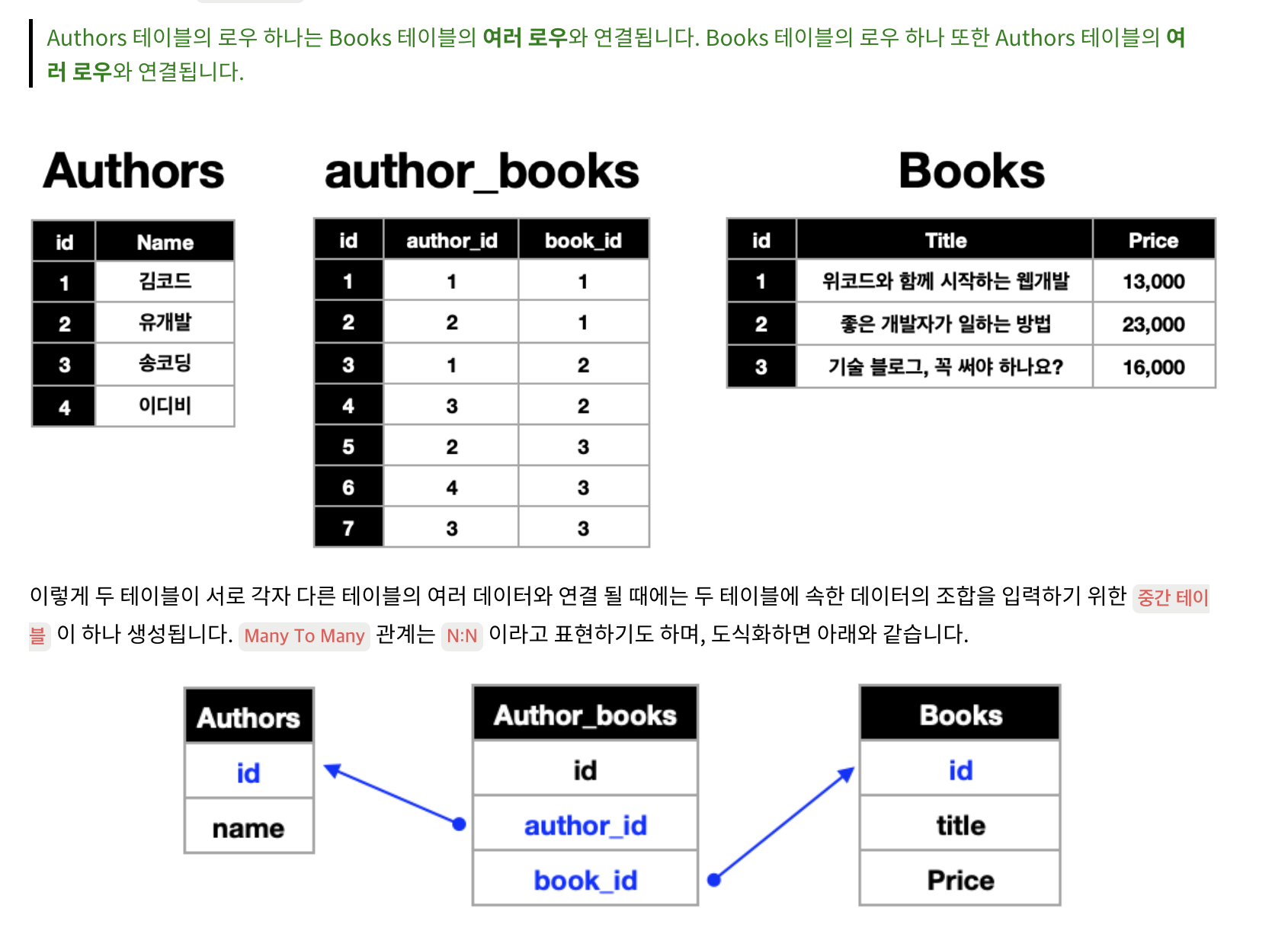
테이블에 저장된 데이터들의 관계에 따라 세가지 타입이 있습니다.
1) one-to-one,
2) one-to-many,
3)many-to-many
1) one to one
데이터들이 서로 하나씩만 연결이 된 경우

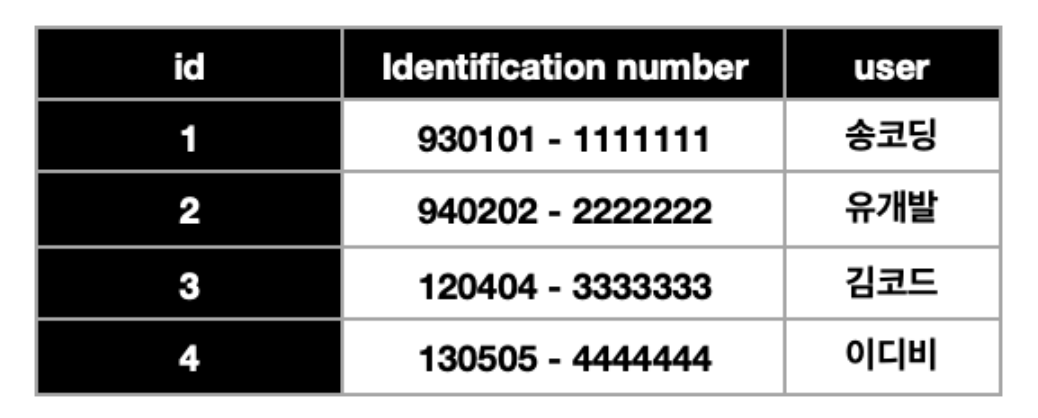
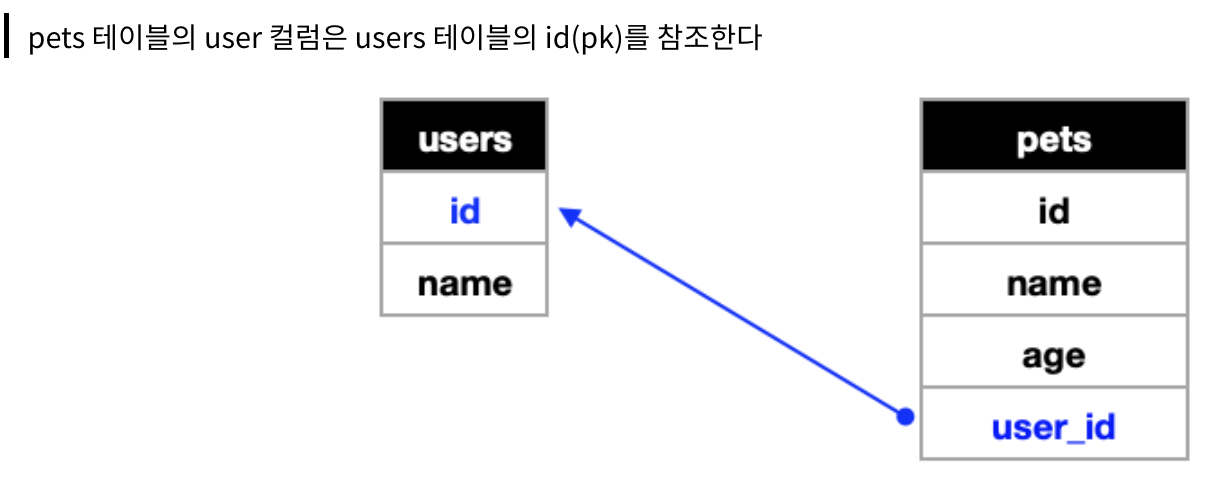
우리에게는 users 라는 테이블이 이미 있고, 이름 데이터들을 이미 저장해뒀는데, 같은 이름들을 중복 해서 여러번 저장하면 불필요한 메모리를 사용하게 됩니다. 따라서 user 란에 이름을 직접 저장하기 보다는 아래 그림처럼 user_id 를 저장해주는 것이죠(id는 Primary key로 항상 존재하니깐요).
이를 참조한다 라고 표현합니다.
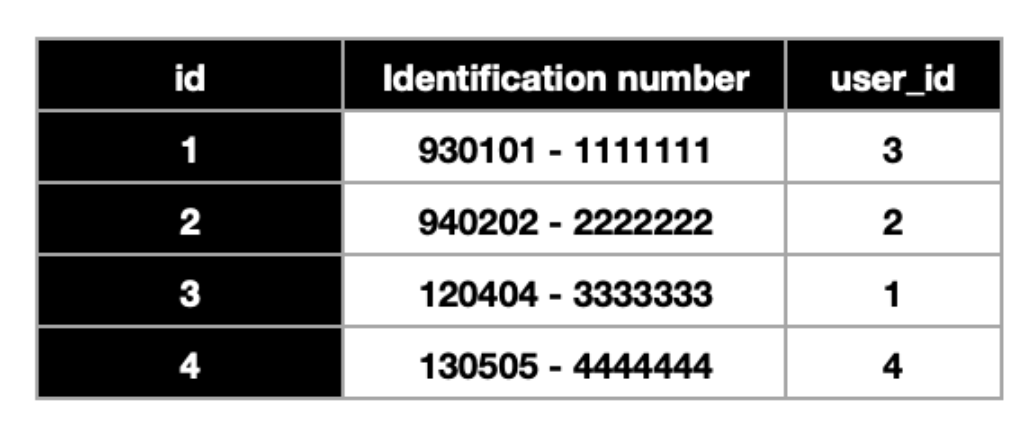
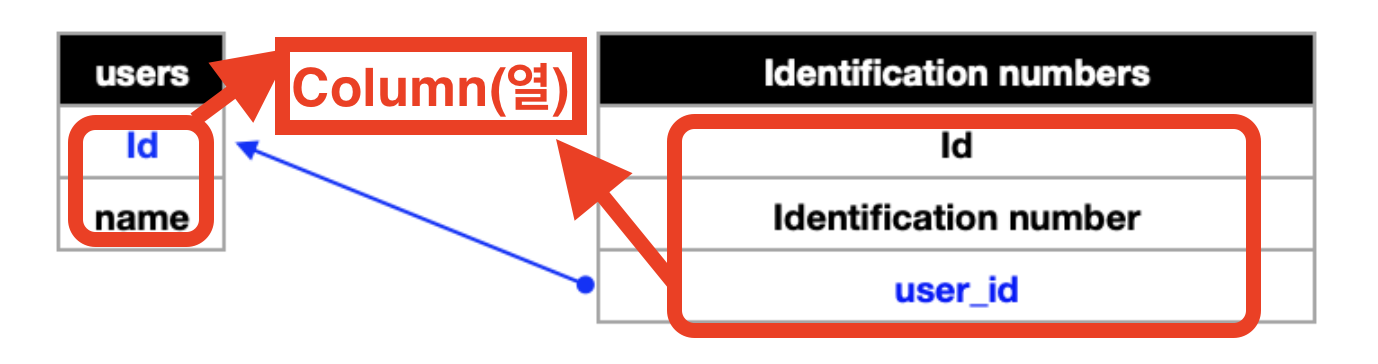
📍 1:1 은 두 테이블이 서로가 서로의 오로지 한 로우에만 연결되어야만 합니다.
*** normalization(정규화)
중복된 데이터를 저장하지 않음으로 디스크를 더 효율적으로 쓰고,
또한 서로 같은 데이터이지만 부분적으로만 내용이 다른 데이터가 생기는 문제가 없어집니다.
- Foreign key(외부키)라는 개념을 사용하여 주로 연결합니다.
2) one to many
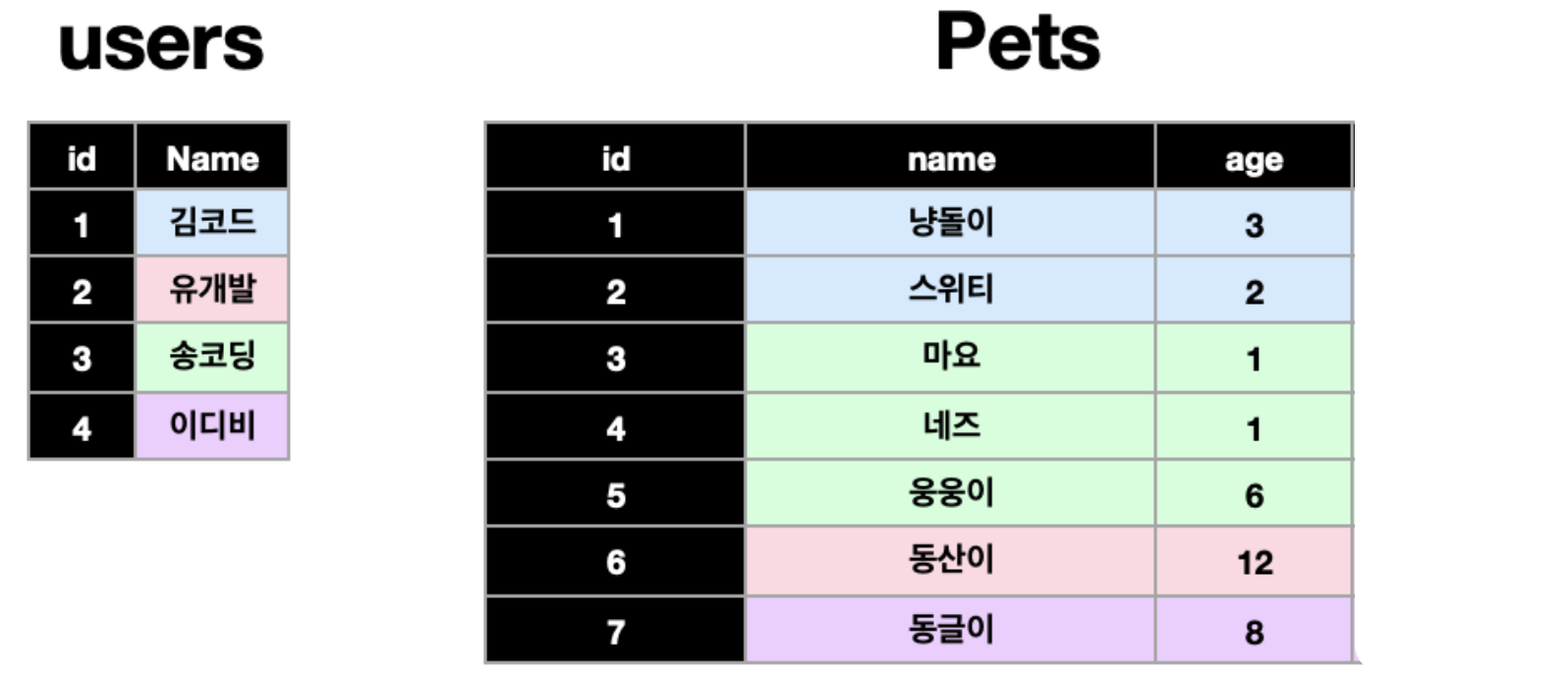
Users 테이블의 로우 하나는 Pets 테이블의 여러 로우와 연결됩니다. Pets 테이블의 로우 하나는 Users 테이블의 로우 하나와 연결됩니다.
따라서, users 테이블이 one, pets 테이블이 many가 되겠네요
이렇게, 한 테이블의 로우 하나가 다른 테이블의 여러 로우와 연결되는 경우를 One To Many 관계 혹은 일대다 관계라고 부릅니다.
📍 1:N 은 한 테이블의 로우 하나에 다른 테이블의 로우 여러개가 연결될 수 있습니다.
3) many to many
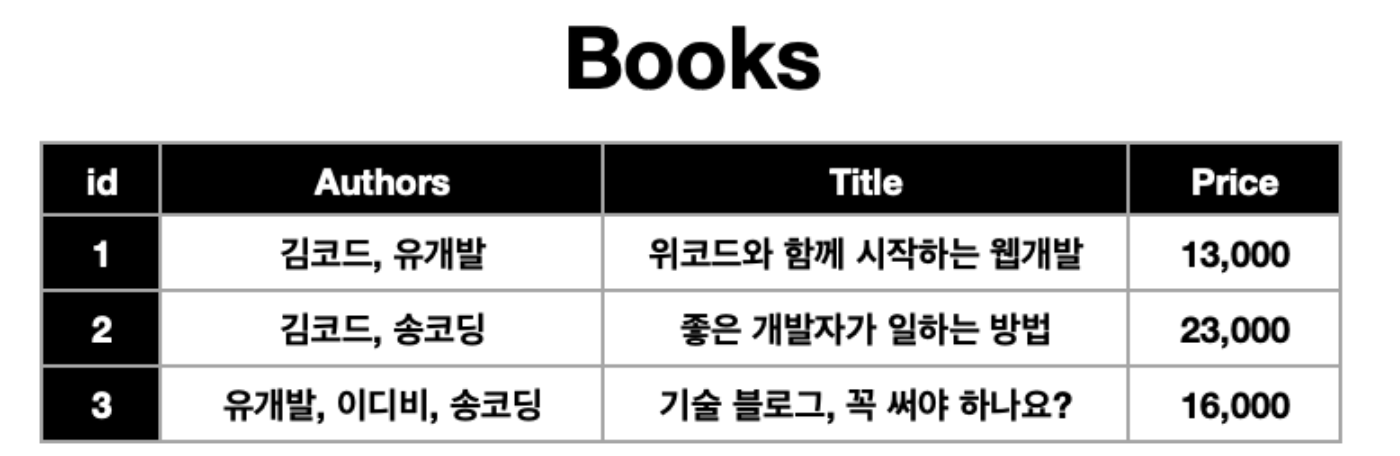
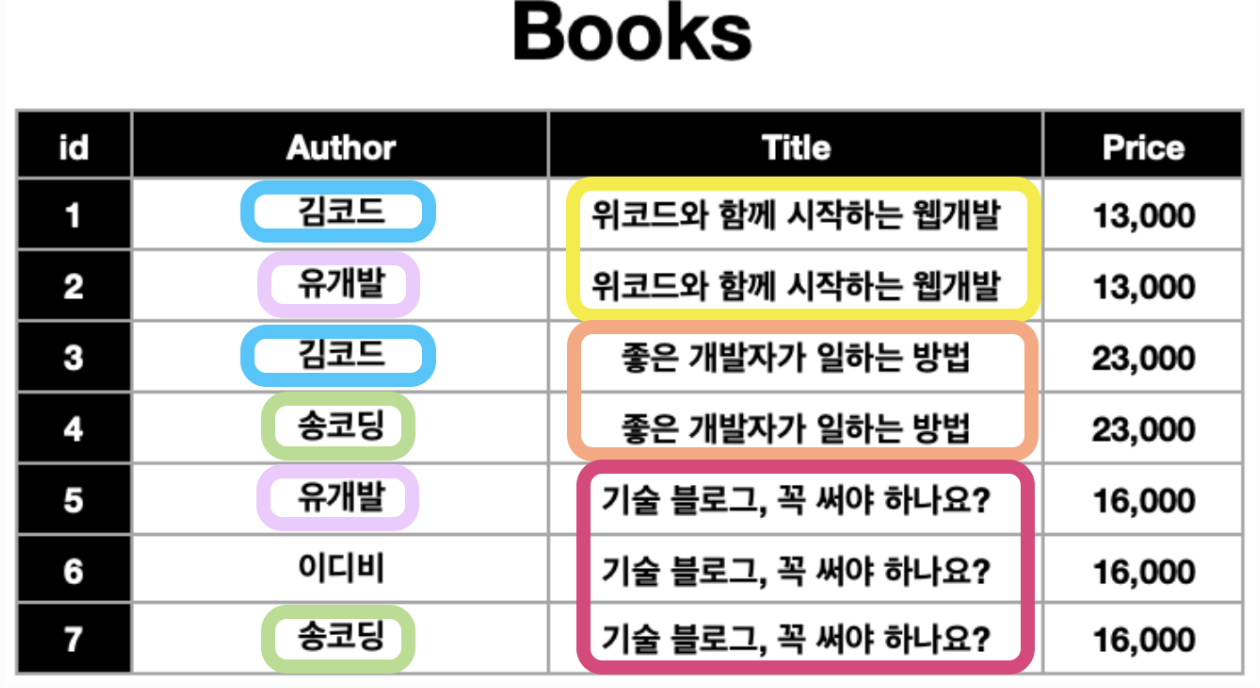
우선은 테이블의 행 하나에는 딱 하나의 데이터만 들어가야 한다는 사실만 알아두세요.
4.스타벅스 메뉴판 정규화 모델링
