
Dynamo DB를 사용할 때 가장 큰 어려움은 데이터 모델링이다. 기존의 익숙한 RDBMS에서의 데이터모델링은 데이터기반 설계(엔티티 식별하고 테이블, 관계 맺기)라고 한다면, DynamoDB는 Query pattern 기반 설계이다. 데이터 기반 설계에서는 어떻게 가져오지에 대한 문제를 SQL을 활용해서 그때그때 풀어버리기 때문에, 데이터 접근패턴에 따라 설계가 달라지는 DynamoDB특성을 이해하기에 큰 어려움이 있다.
아래 글은 간단한 사용사례를 기반으로 다이나모디비 테이블 설계에 대한 도움이 될 것이다.
원글
Single Table Design
싱글 테이블 설계는 Rick Houlihan에 의해 개발되고 Alex DeBrie에 의해 대중화되었습니다. 많은 사람들이 관계형 데이터베이스와 정규화 프로세스에 익숙합니다. 다이나모디비는 서버리스이고 고도로 확장 가능하며 일관된 읽기 성능등 훌륭한 장점이 있지만 개발에 다른 접근 방식이 필요합니다. 관계형 데이터베이스에서는 여러 테이블을 만들고 기본 키와 외래 키로 서로 관계를 맺어주고, 만약 새로운 엔터티가 필요한 경우라면 새 테이블을 만들고 기본 키 및 외래 키를 통해 다른 엔터티(테이블)과 연결하면 됩니다.
DynamoDB는 관계형 데이터베이스의 키(기본키, 외래키) 대신 인덱스를 활용하여 DynamoDB 테이블 내의 데이터에 효율적으로 액세스할 수 있습니다. 여기에는 기본 키(파티션 키 및 정렬 키), 글로벌 보조 인덱스(GSI, 파티션 키 및 정렬 키) 및 로컬 보조 인덱스(추가 정렬 키 제공)가 포함됩니다.
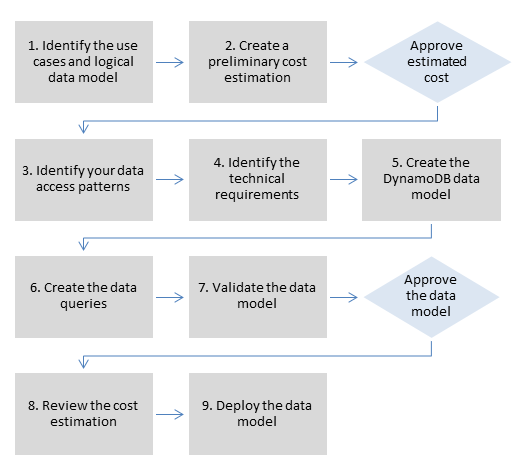
AWS 데이터 모델링 프로세스 - 번역자가 추가했습니다
AWS는 DynamoDB 데이터 모델링 프로세스 단계를 위 그림처럼 9단계로 정의하지만 여기서는 다음에 초점을 맞출 것입니다:
- 데이터 액세스 패턴 식별
- DynamoDB 데이터 모델 생성
- 데이터 모델 검증
DynamoDB의 개념과 예제를 보면 길을 잃기 쉽습니다. 이 글에서는 산타클로스를 돕기 위한 사용 사례로 실제 코드에 연결되는 간단한 예제를 제공하고자 합니다. 산타클로스는 많은 편지(Letter)를 받는데, 각 편지에는 여러 장난감(Toy)에 대한 요청이 포함될 수 있습니다. 이는 키 저장소 데이터베이스(Key store database)에서는 나타낼 수 없습니다. 왜냐하면 편지와 장난감 사이의 관계를 구현해야 하기 때문입니다.
싱글 테이블 설계의 주요 이점은 양방향으로 다대다 관계를 구현할 수 있다는 것입니다. 대부분은 관계형 데이터베이스 모델에 익숙하지만 싱글 테이블 설계는 DynamoDB에 대해 이를 가능하게 합니다.
데이터 액세스 패턴 식별
산타의 공방에서는 아이들이 보낸 편지에 각 장난감에 대해 받기를 원하는 장난감 목록과 수량을 표현하고자 합니다. 이 시나리오에서 모델링할 두 가지 주요 엔티티는 편지와 장난감입니다.
Letter : 편지에는 ID, 총 가격(포함된 모든 장난감의 순비용 합계), 주소, 받은 날짜 및 주소가 포함되어야 합니다.
Toy : 장난감에는 ID, 이름, 설명 및 가격이 포함되어야 합니다.
싱글 테이블 설계의 경우 DynamoDB 테이블을 Letters라고 할 것이며 이 테이블에는 Letters와 Toys 엔티티가 포함될 것입니다.
이 DynamoDB 테이블의 데이터 액세스 패턴(Data Access Pattern)은 다음과 같습니다:
- 장난감의 전체 목록 가져오기 (속성 포함)
- 개별 장난감 가져오기 (속성 포함)
- 편지 전체 목록 가져오기 (장난감 목록과 속성을 포함한 )
- 개별 편지와 해당 속성 가져오기(장난감 목록이 포함된 )
- 새 편지 만들기
- 새 장난감 만들기
- 특정 장난감에 대해 해당 장난감을 요청하는 모든 편지 목록과 산타가 배달해야 하는 총 장난감 수를 검색
- 주어진 편지에 대해 편지 정보와 장난감 가격에 대한 정보를 검색
- 편지 수신 당시의 편지 정보와 장난감 가격의 스냅샷인 편지 히스토리 정보를 JSON 형식으로 검색해야 함
DynamoDB 데이터 모델 만들기
이제 액세스 패턴과 속성 목록이 있으므로 이 데이터베이스가 어떻게 보일 수 있는지 모델링을 시작할 수 있습니다. 스프레드시트나 NoSQL workbench에서 이를 수행할 수 있습니다.
DynamoDB는 데이터 정규화에 대해 크게 염려할 필요가 없고 일부 데이터는 중복될 수 있습니다.
다음과 같은 것으로 끝낼 수 있습니다:
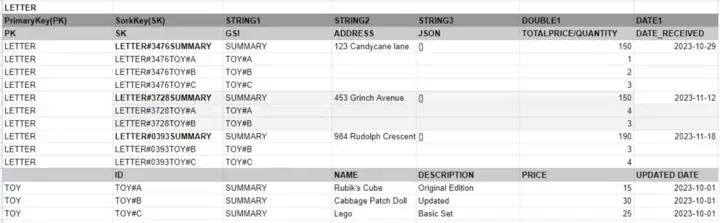
저자가 PartiionKey 자리에 PrimaryKey 로 넣었는데... 왠지 실수? 같습니다 뒤로 계속 PartitionKey 를 PrimaryKey로 지칭하고 있습니다. 참고바랍니다.
공식 문서에 따르면 Primary Key = Partition Key + Sort Key
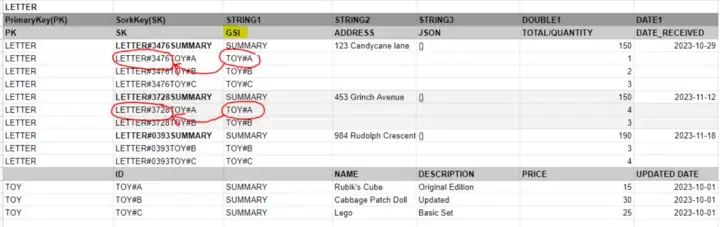
편지(Letters)와 장난감(Toys)는 고유한 기본 키(Partition Key) 필드에 LETTER 또는 TOY를 입력하여 구분됩니다. 이를 통해 이러한 특정 엔티티를 쿼리할 수 있습니다.
인터넷에서 볼 수 있는 대부분의 DynamoDB 싱글 테이블 설계는 PK 필드에 단일 고유 값 (예: USER#ALEXDEBRIE 또는 RACER-1)을 기반으로 하는데, 이는 객체 집합(이 경우 Letters 또는 Toys와 같은)을 검색하는 데 적합하지 않습니다. 따라서 이는 PK 필드에 엔티티 범주(LETTER/TOY)를 저장하고 SK 필드에 실제 객체의 고유 식별자와 엔티티의 실제 행 유형(편지 엔티티의 경우 요약 행 또는 장난감 세부 정보 행)을 저장하는 방식으로 처리됩니다.
LETTER는 주소, 편지 기록 정보, 총 편지 가격(비용), 편지 수신 날짜와 같은 LETTER 전체에 대한 정보를 저장하기 위한 SUMMARY 행으로 구현되었습니다.
LETTER는 어떤 장난감이 요구되었는지와 이 편지에 대한 각 장난감의 수량을 저장하기 위해 개별 TOY 행으로 구현되었습니다.
TOY는 LETTER보다 더 단순하며 속성 정보를 포함하는 행만 필요합니다.
DynamoDB 테이블의 파티션 키(PK)에서는 BEGINS_WITH 함수를 사용할 수 없기 때문에 스캔 없이 모든 Letters와 Toys를 쿼리하려면 PK 필드에 LETTER와 TOY를 저장합니다. 이렇게 하면 PK 필드에 LETTER#... 또는 TOY#...와 같은 항목을 만들 수 없게 됩니다. 따라서 개별 편지나 장난감을 조회할 때는 PK(LETTER 또는 TOY 포함)와 BEGINSWITH("TOY#ID")를 사용하는 연관된 SK를 기반으로 쿼리합니다.

이제 주어진 장난감에 대해 요청된 장난감의 수를 알아야 하는 데이터 액세스 패턴을 살펴보면 기본 키로는 이를 수행할 수 없습니다. 이때 역 인덱스(Inverted Index)를 활용합니다.
역 인덱스(Inverted Index)는 DynamoDB에서 일반적인 보조 인덱스(Secondary Index) 설계 패턴입니다. 여기에는 DynamoDB 테이블의 기본 키의 역을 저장하는 보조 인덱스가 포함되어 일반 키 값 저장소 접근 방식으로는 실제로 가능하지 않은 다대다 관계의 "다른" 쪽을 쿼리할 수 있습니다.
이 경우 DynamoDB 테이블의 STRING1 필드에 GSI(Global Secondary Index)를 만듭니다. 이 GSI를 사용하면 모든 TOY에 대한 STRING1 요소를 DynamoDB에서 쿼리할 수 있고 연관된 모든 LETTER를 조회할 수 있습니다.
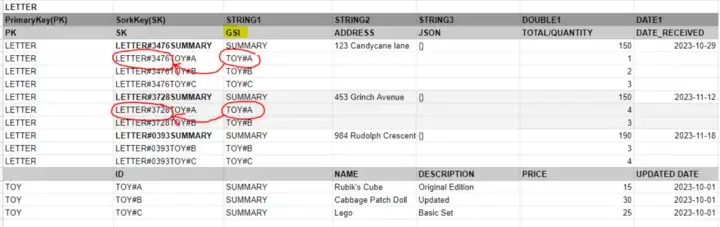
따라서 Toy A와 관련된 모든 편지를 찾고자 한다면 GSI 인덱스를 사용하여 편지에서 TOY#A를 효과적으로 쿼리할 수 있습니다. 그런 다음 SK 필드에서 개별 LETTER 정보만 조회하면 됩니다.
이것이 데이터의 전체 스캔을 사용하지 않고 이 정보를 효과적으로 얻는 방법입니다. 인덱스를 사용하면 데이터 액세스 패턴을 충족하고 데이터 호출을 최소화하여 비용을 낮출 수 있습니다. DynamoDB는 서버리스이므로 사용한 만큼만 비용을 지불합니다. 그렇기 때문에 NoSQL 싱글 테이블 모델에서는 데이터 액세스 패턴이 훨씬 더 중요한 고려 사항입니다. 관계형 데이터베이스에서는 테이블을 만들고 키로 연결하기만 하면 되지만 NoSQL 싱글 테이블 모델에서는 신중하게 고려해야 합니다.
데이터 모델 검증
산타의 공방의 실제 작동 코드 예제로 데이터 모델을 검증해 보겠습니다.
데이터 액세스 패턴을 몇 가지 살펴보겠습니다.
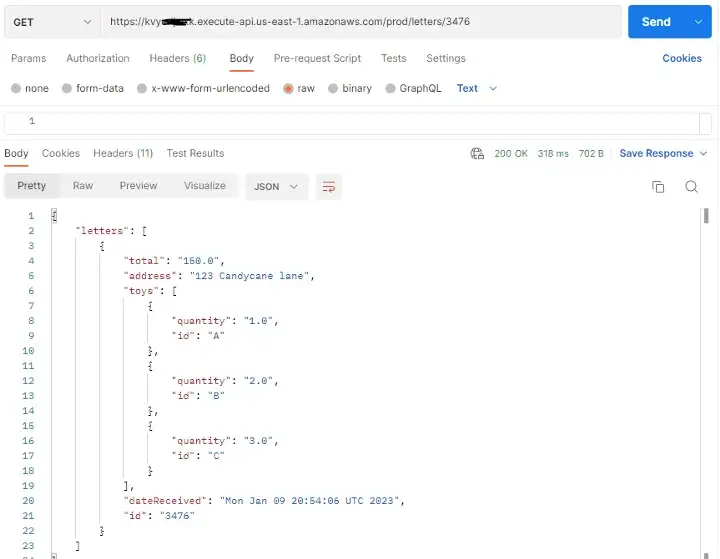
먼저 데이터 액세스 패턴 4인 속성(장난감 목록 포함)이 있는 개별 편지 가져오기를 살펴보겠습니다.
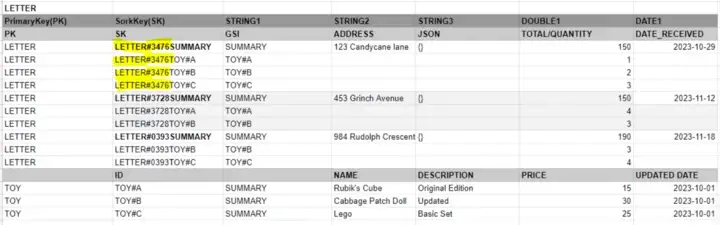
PK가 LETTER이고 SK가 LETTER#3476으로 시작하는 것을 기반으로 DynamoDB 테이블을 쿼리하면 전체 테이블 스캔을 수행하지 않고도 요약 레코드 1개와 필요한 TOY 레코드 3개를 반환합니다.
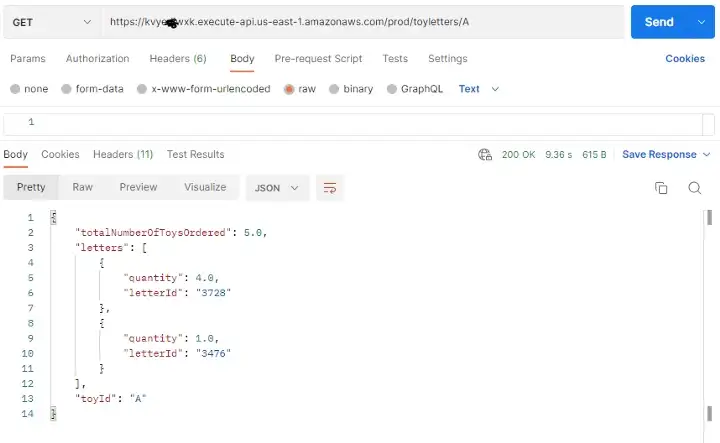
마지막으로 데이터 액세스 패턴 8(특정 장난감에 대해 해당 장난감을 요청하는 모든 편지 목록과 산타가 배달해야 할 총 장난감 수 검색)을 살펴보겠습니다.
이는 STRING1 필드에 대한 GSI 인덱스로 구현된 역 인덱스를 사용하여 달성됩니다.
다음 Postman 호출로 이것이 작동함을 확인할 수 있습니다.
산타의 공방(Santa's Workshop) 을 더 자세히 살펴보시길 바랍니다.
번역시점에서 링크는 깨져있습니다
중요한 점은 적절한 인덱싱으로 정보가 어떻게 저장되고 검색될 것인지 이해할 수 있다면 싱글 테이블 설계를 사용하여 DynamoDB에서 관계형 모델링을 개발할 수 있다는 것입니다.
결론
이 글에서는 싱글 테이블 설계 DynamoDB 테이블을 만드는 데 대한 주요 고려 사항을 설명했습니다. 각 테이블은 요구 사항이 다릅니다. 이에 대한 제 생각은 다음과 같은 핵심 단계가 있다는 것입니다:
- 엔터티와 속성 식별
- 엔터티 간의 관계 식별
- 모델에 대한 모든 데이터 액세스 패턴 문서화
- 스프레드시트에서 모델 만들기 또는 NoSQL 워크벤치 사용
- 모델 구현
- 테스트 및 반복
작동하는 모델이 있으면 고도로 확장 가능한 서버리스 DynamoDB 모델의 이점을 누릴 수 있습니다. 이는 관계형 데이터베이스 모델링과는 다른 프로세스이므로 사고의 조정이 필요합니다.
각 싱글 테이블 설계는 엔터티, 속성 및 관계에 따라 고유할 것입니다. 또한 동일한 요구 사항을 충족하기 위한 많은 다양한 접근 방식이 있습니다.
더 읽어볼만한 글들
