
엘릭서를 공부하다가 중요한 개념인 프로세스에 대한 좋은 글을 보게되었다. 요즘은 번역이 비교적 쉬운 세상이 되다보니, 부담없이 한번 시도해보았다. 저자는 Samuel Mullen 이라는 프리랜서이다.
저는 캔자스시티에서 아름다운 아내, 멋진 두 자녀, 강아지, 고양이와 함께 살고 있습니다. 저는 루비, 자바스크립트, 엘릭서를 전문으로 하는 프리랜서 소프트웨어 개발자로, 제가 하는 일을 사랑합니다.
Elixir Processes: Spawn, Send, and Receive
저는 공상과학 소설 읽기를 좋아합니다. 과학적인 근거에 기반한 이야기뿐 아니라, 레이저 검을 휘두르는 우주 마법사가 등장하는 내용도 좋아합니다. 저는 공상과학 소설에서 그럴 법한 상상의 이야기, 생각 못했던 소재와 아이디어를 즐깁니다. 특히 소설속에 등장하는 외계인과 그들의 문명 및 세계관을 알아가는게 즐겁습니다.
공상과학에서 자주 반복되는 주제 중 하나는 하이브 마인드입니다. 이야기속에서 주인공은 외계 종족과 상호작용을 위해 많은 시도와 도전을 합니다.(상호작용은 보통 "외계벌레들을 우주로 날려버린다"는 의미이죠) 마침내 용감한 주인공 혹은 여주인공은 외계인들이 집단적으로 움직인다는 사실을 알아내고 외계'여왕'과 성공적?으로 상호작용하여 세상를 구합니다.

엔더스 게임이란 소설에서 인류는 'Bugger' 라는 애칭으로 알려진 외계종족과 대결을 펼칩니다. 두 종족 모두 각자의 함대와 거의 실시간으로 먼 거리에서 통신할 수 있지만, 통신 대상에 차이가 있습니다. 버거종족의 경우 여왕이 통신을 통해 각 드론을 지휘하고 제어합니다.
반면에 인류는 지시를 전달하고 각 함선이 그 지시를 가장 잘 수행할 수 있는 방법을 결정하도록 합니다.
엔더스 게임과 프로그래밍 동시성 모델에서 유사점을 도출한다면, 버거는 전통적인 동시성 모델에 해당하고 인류는 액터 모델에 해당한다고 상상할 수 있습니다. 전자의 경우 공유 메모리를 여러 스레드와 프로세스가 사용하려하고, 어떤 식으로든 손상될 경우 관련된 모든 스레드에 심각한 문제를 초래할 수 있습니다. 따라서 여왕처럼 누군가 중앙에서 철저하게 관리를 해 줄 필요가 있습니다. 반면에, 인류의 우주선처럼 액터 모델에서는 프로세스 간에 공유되는 것이 없습니다. 따라서 각 프로세스는 다른 프로세스에 영향을 미칠 염려 없이 독립적으로 작동할 수 있습니다.

Benjamin Tan Wei Hao는 erlang과 Elixir에서 사용하는 Actor Model(액터 모델)의 동작을 다음 다섯 가지로 단순화합니다:
- 각
액터는프로세스입니다. - 각
프로세스는특정 작업을 수행합니다. 프로세스에 어떤작업을 지시하려면메시지를 보내야 합니다.프로세스는 다른메시지를 다시 보내응답할 수 있습니다.프로세스에작업을 지시하는메시지의 종류는 각각의프로세스마다 다릅니다. 즉,프로세스내부에서 수신된메시지는pattern-matched를 통해 특정한 작업으로 라우팅됩니다.- 그 외에는
프로세스는 다른프로세스와 어떤 정보도 공유하지 않습니다.
...The Little Elixir & OTP Guidebook
이 점을 염두에 두고 Elixir의 동시성(concurrency) 기본 요소를 살펴봅시다.
Process
Elixir의 기본 동시성 단위는 프로세스입니다. Elixir 또는 Erlang의 프로세스는 다른 언어에서 프로세스와 그 개념이 다릅니다.
...Elixir에서
프로세스는 기본 운영 체제(OS)프로세스를 의미하지 않습니다. 운영체제의 프로세스는 너무 느리고 사이즈가 비교적 큽니다. 대신 Elixir는 Erlang의 프로세스 지원을 사용합니다. 이러한 프로세스는 네이티브 프로세스와 마찬가지로 모든 CPU에서 실행되지만 오버헤드가 거의 없습니다."
..Programming Elixir
BEAM은 기본 운영체제 프로세스에서 실행하여 이 작업을 수행합니다. 거기서부터 사용 가능한 각 CPU 코어에 대한 "스케줄러"를 생성하며, 각 코어는 자체 스레드에서 실행됩니다. 이 스케줄러가 Elixir 프로세스의 생성 및 실행을 관리합니다.
Elixir 프로세스를 생성은 수 마이크로초밖에 걸리지 않으며 초기 메모리 사용량은 몇 KB에 불과합니다. 이에 비해 OS 스레드는 일반적으로 스택에만 몇 메가바이트를 사용합니다. 따라서 많은 수의 엘릭서 프로세스를 생성할 수 있습니다. 가상 머신이 부과하는 이론적 한계는 약 1억 3,400만 개입니다!
..Elixir in Action
자 이제 아래 코드를 실행시켜봅시다.
spawn(fn -> IO.puts "Hello, World!" end)
|> Process.info(:memory)실행하면 아래와 같은 튜플을 반환합니다:
{:memory, 2688}
2,668은 "...프로세스의 바이트 단위 크기입니다. 여기에는 호출 스택, 힙 및 내부 구조가 포함됩니다."
프로세스 생성에 대해 자세히 살펴봅시다.
Spawn
엘릭서 프로세스를 생성하려면 spawn/1 또는 spawn/3을 사용해야 합니다. 전자는 방금 살펴본 것처럼 익명 함수를 인자로 받아들이고, 후자는 모듈, 함수 이름, 인수 목록(MFA)을 인자로 받습니다. 두 경우 모두 spawn은 호출하는 프로세스에 PID(프로세스 ID)를 반환합니다.
몇 가지 예를 살펴보겠습니다. IEx(엘릭서 REPL)를 열고 다음을 입력합니다:
iex > spawn(fn -> IO.puts("Hello, Alpha Centauri!") end)아래와 같은 출력을 확인할 수 있습니다.
#PID<0.2866.0>
Hello, World!위와 비슷한 출력을 spawn/3함수를 통해 받을 수 있습니다.
iex > spawn(IO, :puts, ["Hello, Alpha Centauri!"])두 경우 모두 Elixir는 새 프로세스를 생성하고 그 안에서 지정된 함수를 실행하지만, 그게 전부입니다. PID 옆에 반환 값도 없고, 성공 또는 실패 메시지도 없으며, 자식 프로세스는 주어진 작업만 수행할 수 있고, 일단 시작되면 부모 프로세스는 자식 프로세스 내부에서 무슨 일이 일어나고 있는지 전혀 알 수 없습니다 (제가 완전히 공감할 수 있는 부분입니다).
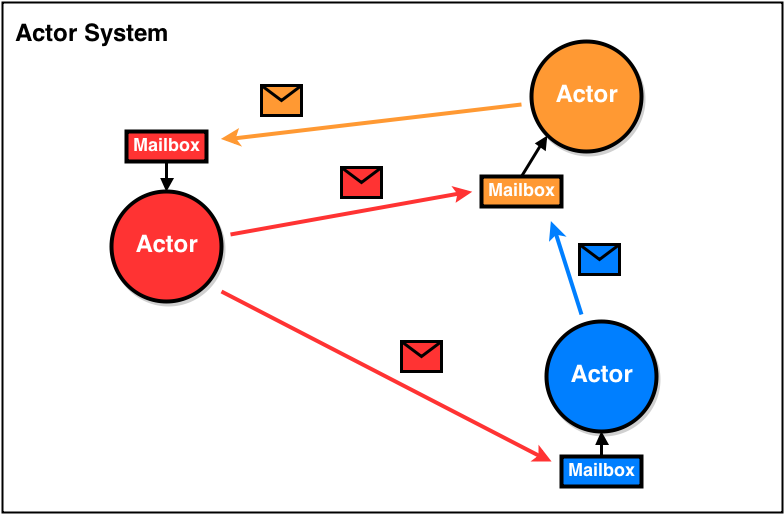
다행히도 액터 모델의 일부인 프로세스는 메시지를 통해 다른 프로세스와 통신할 수 있습니다. 수신 프로세스는 메시지를 응답으로 반환하거나 다른 프로세스로 메시지를 보낼 수 있습니다.
메시지 주고받기
엘릭서에서 다른 프로세스로 메시지를 보내는 방법은 매우 쉽습니다. 받는 프로세스의 PID와 보낼 메시지만 있으면 됩니다. 아래 Iex에서 이렇게 시도해볼 수 있습니다.
iex > send(self(), :hi)
:hi여기서 우리가 한 것은 현재 IEx 세션에 :hi라는 메시지를 보내는 것입니다. send/2 함수는 우리가 보낸 메시지를 반환하지만 아무 일도 일어나지 않은 것으로 보입니다. 메시지가 어디로 갔을까요? 허공으로 사라졌나요? dev/null로 전송되었나요? "커튼을 타고 내려와 보이지 않는 합창단에 합류"했나요? 아니면 어딘가에 저장되어 있을까요? 짐작하셨겠지만, 답은 프로세스가 메시지를 수신할 때까지 메시지가 프로세스 사서함(mailbox)에 저장된다는 것입니다. Process.info/2를 사용하면 수신된 메시지를 확인할 수 있습니다.
iex > Process.info(self(), :messages)
{:messages, [:hi]}IEx 프로세스의 사서함에 수신된 메시지를 꺼내려면, receive/1매크로를 사용하여 수신하면 됩니다.
iex > receive do :hi -> IO.puts "Hello." end
Hello.
:ok
iex > Process.info(self(), :messages)
{:messages, []}receive/1 함수는 수신된 메시지가 :hi 아톰과 일치하는지 검사하고 일치하면 함수(IO.puts/1)를 실행합니다. receive/1 함수를 다시 실행하면 어떻게 될까요?
receive/1 함수를 다시 실행하면 IEx 세션이 종료될 때까지 중단될 것이므로, receive/1로 작업할 때는 after 절을 포함하는 것이 좋습니다.
receive do
:hi ->
IO.puts "Hello!"
after
0 ->
IO.puts "Message not found"
endafter 절은 타임아웃 값으로 :infinity 또는 0에서 4,294,967,295(49.7일) 사이의 정수를 사용합니다. 값을 0으로 설정하면 수신 블록이 즉시 반환되지만, 다른 값은 해당 밀리초만큼 대기합니다.
기본 사항을 설명했으니 이제 spawn/3, send/2, receive/1을 함께 사용하는 방법을 살펴보겠습니다. 인사말을 화면에 출력하는 간단한 모듈부터 시작하겠습니다:
defmodule Salutator do
def run do
receive do
{:hi, name} ->
IO.puts "Hi, #{name}"
{_, name} ->
IO.puts "Hello, #{name}"
end
end
endreceive 블럭을 추가함으로, 우리는 Salutator 모듈의 중요 부분을 완성할 수 있습니다. 이제 필요한 것은 해당 모듈을 띄우는 spawn/3함수입니다.
iex > pid = spawn(Salutator, :run, [])Salutator가 실행되는 동안, 우리는 여러 메시지를 보내 볼 수 있습니다.
iex > send(pid, {:hi, "Mark"})
{:hi, "Mark"}
Hi, Mark
iex > send(pid, {:hello, "Suzie"})
{:hello, "Suzie"}두 번째로 Salutator에 메시지를 보냈을 때 예상한 결과를 반환하지 않은 것을 알 수 있습니다. receive/1은 일반함수(매크로)라는 것을 기억하세요. 일단 실행되면 작업을 수행하고 종료됩니다. run/0이 두 개 이상의 메시지를 수신하도록 하려면 다시 생성해야 합니다. 이럴땐 재귀(recursion)를 사용하면 됩니다. 새로운 모듈과 함수는 다음과 같습니다:
defmodule Salutator do
def run do
receive do
{:hi, name} ->
IO.puts "Hi, #{name}"
{_, name} ->
IO.puts "Hello, #{name}"
end
run() # <- 재귀호출!
end
end이제 우리는 (재미는 없지만,) 인사말을 무제한으로 생성할 수 있습니다. 이제 생성된 프로세스가 어떻게 자신을 호출한 프로세스나 다른 프로세스와 통신할 수 있는지 궁금합니다. 하지만 먼저 사서함을 좀 더 자세히 살펴봅시다.
프로세스 사서함 (Process Mailbox)
앞서 프로세스가 메시지를 수신(receive)할 때까지 메시지가 프로세스의 사서함에 저장된다는 것을 살펴보았습니다. 그런데 왜 함수를 직접 실행하지 않고 프로세스의 사서함으로 메시지를 보낼까요? Elixir 프로세스 가이드에 따르면 "메시지를 보내는 프로세스는 send/2요청시 응답을 기다리지않고, 수신자의 사서함에 메시지를 넣고 계속 진행합니다. (비동기 처리)" 라고 설명합니다. 그러면 수신 프로세스는 발신 프로세스에 진행 상황을 알릴 필요도 없고(no callback) 발신자의 진행을 방해할 필요(non blocking)도 없이 수신 사서함의 용량에 따라 메시지를 처리할 수 있습니다.
receive 표현식은 다음과 같이 실행됩니다.
1. 사서함에서 첫 번째 메시지를 가져옵니다.
2. 위에서부터 아래까지 제공된 패턴과 일치하는지 확인합니다.
3. 패턴이 메시지와 일치하면 해당 코드를 실행합니다.
4. 일치하는 패턴이 없으면 메시지를 원래 있던 위치에 다시 사서함에 넣습니다. 그리고 다음 메시지를 꺼내서 2단계로
5. 대기열에 더 이상 메시지가 없으면 새 메시지가 도착할 때까지 기다립니다. 새 메시지가 도착하면 1단계부터 시작하여 사서함의 첫 번째 메시지를 검사합니다.
6.after절이 지정되어 있고 주어진 시간 내에 일치하는 메시지가 없으면 이후 블록에서 코드를 실행합니다.
--- Saša Jurić, Elixir in Action
각 프로세스에는 사용 가능한 메모리에 의해서만 제한되는 자체 사서함이 있습니다. 이렇게 메모리에 따라 제한을 둠으로, 작업할 수 있는 충분한 공간을 제공하면서, 잘못되는 사태를 방지할 수 있습니다.
이제 모두 붙여보자
지금까지 프로세스 생성, 개별 메시지 송수신, 프로세스 사서함에 대해 살펴보았습니다. 지금까지 배운 내용을 바탕으로 각 요소가 어떻게 함께 작동하는지 보여줄 수 있는 무언가를 만들어 봅시다.
우리가 만들 도구는 단어 사전을 가져와서 서로의 애너그램인 단어들을 그룹화하고, 세 개 이상의 단어가 일치하는 목록을 반환하는 도구입니다. 출력은 다음과 같습니다:
...
{"elmno", ["monel", "Monel", "melon", "lemon"]}
{"denopru", ["unroped", "repound", "pounder"]}
{"adegiillnntu", ["linguidental", "indulgential", "dentilingual"]}
{"aeelrs", ["sealer", "reseal", "resale", "reales", "leaser", "alerse"]}
{"aceilnp", ["pinacle", "pelican", "panicle", "capelin", "calepin"]}
...튜플의 첫 번째 요소는 애너그램 문자의 알파벳순 정렬이고, 두 번째 요소는 서로의 애너그램인 단어의 목록입니다.
먼저 애너그램 단어를 축적하고 그룹화하는 프로세스를 만들겠습니다. 다음으로, 사전에서 단어를 읽고, 각 단어에 대한 프로세스를 생성하여(제 시스템에는 235,886개의 단어가 있으므로 235,886개의 프로세스가 있습니다) 결과를 구문 분석하고 축적기에 저장하는 모듈을 만들겠습니다. 모듈의 이름은 Accumulator로 하겠습니다.
defmodule Accumulator do
def loop(anagrams \\ %{}) do
receive do
{from, {:add, {letters, word}}} ->
anagrams = add_word(anagrams, letters, word)
send(from, :ok)
loop(anagrams) # must put loop/0 inside each match
{from, :list} ->
send(from, {:ok, list_anagrams(anagrams)})
loop(anagrams)
end
end
defp add_word(anagrams, letters, word) do
words = Map.get(anagrams, letters, [])
anagrams
|> Map.put(letters, [word|words])
end
defp list_anagrams(anagrams) do
anagrams
|> Enum.filter(fn {k, v} -> length(v) >= 3 end)
end
end위 모듈은
- 목록에 애너그램을 추가하고 (
add_word/3) - 요청이 있을 때 목록을 반환하는 (
list_anagrams/1)
두 가지 역할을 수행합니다. loop/1 함수의 receive(3~12줄) 절에 구현되어있습니다. 두 경우 모두 Accumulator는 send/2(6줄과 10줄)를 통해 호출 프로세스에 응답합니다. 단어를 추가할 때는 :ok로 응답하고, :list는 :ok의 튜플과 애너그램 목록으로 응답합니다. 비공개 함수인 add_word/3과 list_anagrams/1은 이름에서 알 수 있듯이 정확히 그 기능을 수행합니다.
이제 Accumulator 모듈을 띄워봅시다.
pid = spawn Accumulator, :loop, []이제 다음 모듈인 Anagrammar은 Accumulator와 서로 통신합니다.
defmodule Anagrammar do
@dictionary "/usr/share/dict/words"
def build_list(accumulator_pid) do
words
|> Enum.each(&(add_anagram(accumulator_pid, &1)))
end
def get_list(accumulator_pid) do
send(accumulator_pid, {self, :list})
receive do
{:ok, list} ->
list
|> Enum.each(&IO.inspect/1)
end
end
defp words do
File.read!(@dictionary)
|> String.split("\n")
end
defp add_anagram(accumulator_pid, word) do
spawn(fn -> _add_anagram(accumulator_pid, word) end)
end
defp _add_anagram(accumulator_pid, word) do
send(accumulator_pid, {self, {:add, parse(word)}})
receive do
:ok -> :ok
end
end
defp parse(word) do
letters =
word
|> String.downcase()
|> String.split("")
|> Enum.sort(&(&1 <= &2))
|> Enum.join()
{letters, word}
end
end조금 복잡해보이지만 하나씩 하나씩 봐보겠습니다.
build_list/1함수(4~7줄)는 시스템 사전에서 단어(23~26줄)를 가져와- 구문 분석(40~49줄)한 다음
- Accumulator(32~38줄)에 로드하는 역할을 담당합니다.
- 각 단어에 대해 새로운 프로세스를 생성하여 이 작업을 수행합니다(28~30줄).
- 33줄에서 어큐뮬레이터에 메시지를 보내면 곧이어 :ok 응답(35-37줄)이 돌아올 것으로 예상합니다.
목록을 가져오는 것은 훨씬 더 쉽습니다.
get_list/1(9줄)에 어큐뮬레이터의 PID를 제공하면get_list/1이 어큐뮬레이터에 메시지를 보내고(10줄)- 응답을 받습니다(12~16줄).
한번 실행해봅시다. 우리는 이미 Accumulator에서 PID를 가지고 있습니다. 사전을 로드하고 목록을 가져오기만 하면 됩니다:
Anagrammar.build_list(pid)
Anagrammar.get_list(pid)👉 원문
