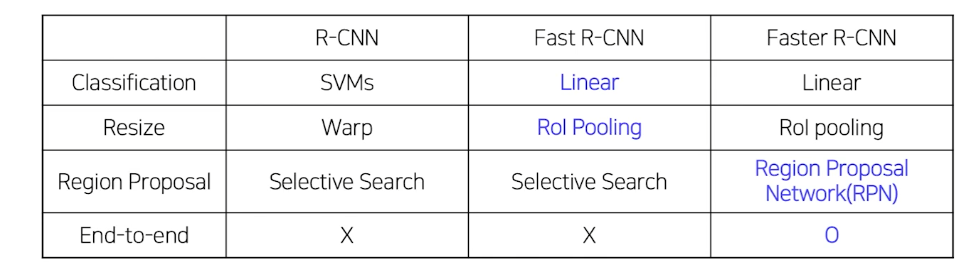
2 Stage Detectors
R-CNN
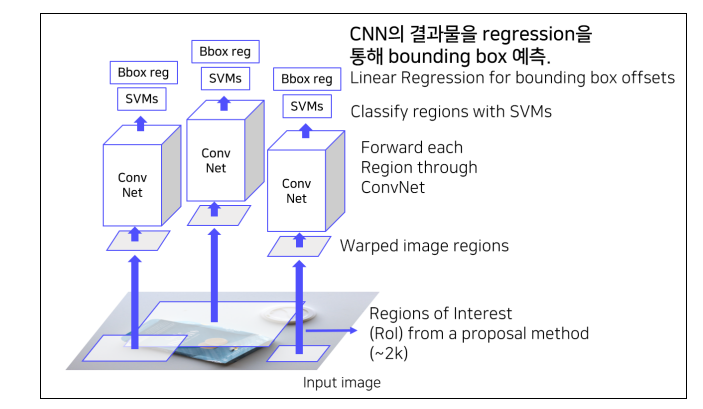
- train 방법
- AlexNet
- domain specific finetuning
- dataset
- IoU > 0.5 = positive samples
- 1 batch = positive sample 32, negative samples 96
- Linear SVM
- dataset
- IoU >= 0.3 = positive samples
- 1 batch = positive samples 32, negative sample 96
- hard negative mining
- hard negative = false positive
- 0인데 1이라고 예측하는 샘플들을 취합해 강제로 다음 배치로 추가시켜 학습을 또 시키는 방법
- 배경으로 식별하기 어려운 샘플들을 다음 배치의 negative sample로 mining하는 방식을 사용한다.
- dataset
- Bbox regressor
- dataset
- IoU > 0.6 = positive samples
- loss function
- MSE Loss
- dataset
- AlexNet
- 결점
- 2000개의 region을 각각 CNN를 통과하는 방식이기 떄문에 연산량이 매우 많다. 따라서 속도가 매우 느리다.
- 객체 크기가 각각 다른데 이를 일정한 size로 강제 warping을 하기 때문에 통해 성능이 하락할 가능성이 있다.
- CNN, SVM classifier, Bbox regressor가 모두 따로 학습한다. 즉, End-to-End가 아니다.
SPPNET
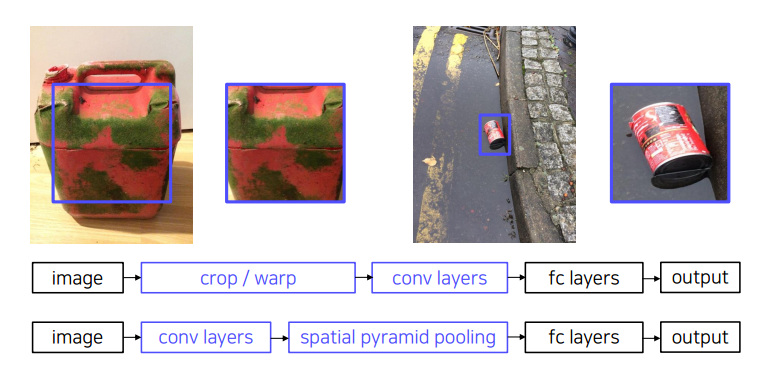
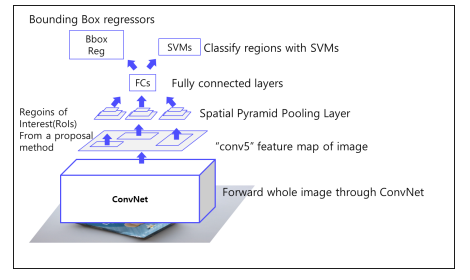
convolution layer를 거친 후 feature를 뽑아내고, spatial pyramid pooling layer를 거침으로써 고정된 size로 변환하게 된다.
-
spatial pyramid pooling layer
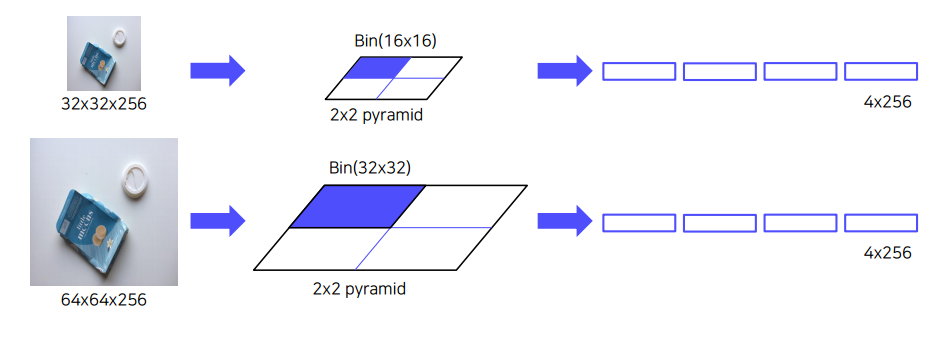
피라미드의 크기만큼의 pooling을 진행해 하나의 feature를 생성하는 방식이다. 예를들어 32 32 256의 image가 있을 대 2 2 pyramid를 거친다면 16 16만큼의 크기를 bin으로 규정한다. 이 bin을 사용해 pooling을 거친다. -
결점
- CNN, SVM classifier, Bbox regressor가 모두 따로 학습한다. 즉, End-to-End가 아니다.
Fast R-CNN
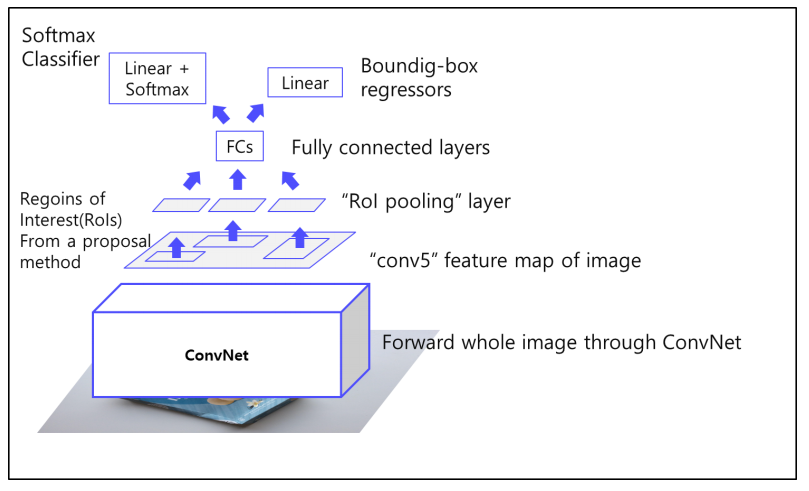
fast R-cnn은 vggnet을 사용했다.
- RoI Projection

원본 이미지에서 RoI 추출을 하고, 원본 이미지에 convolutional layer를 거친 후에 뽑았던 RoI를 적용하는 것.
이 때 convolutional layer를 거치면 이미지가 작아지기 때문에, 일정 비율에 맞춰 RoI 또한 작게 변형하여야 한다.
RoI projection을 통해 다양한 size의 RoI를 추출하게 되고, 이를 사용해 고정된 feature vector를 만들게 되는데, 이를 위해 RoI Pooling을 사용한다.
-
RoI Pooling
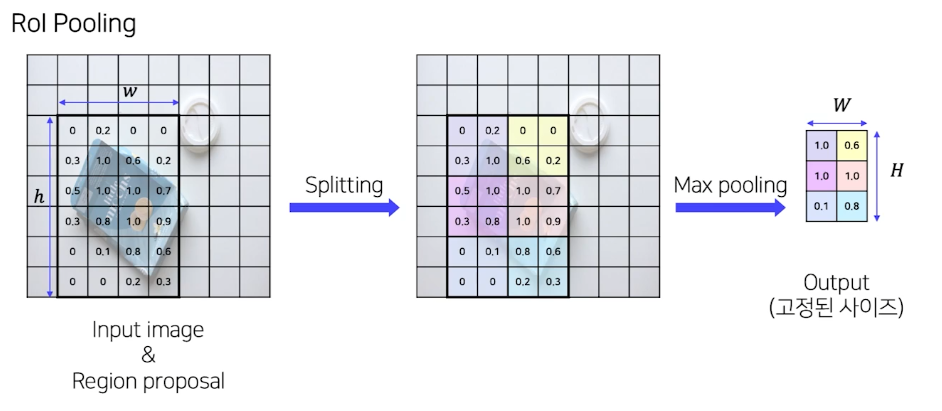
- SPP 사용
- pyramid level: 1
- Target grid size: 7x7
- SPP 사용
-
클래스 갯수는 C+1개로 클래스 c개의 갯수와 배경 1개로 구성되어 있다.
-
train 방법
- end-to-end 구조이기 때문에 multi task loss를 사용한다.
- Loss function
- classification : Cross entropy
- Bbox regressor : smooth L1
- dataset
- IoU > 0.5 : positive samples
- 0.1 < IoU < 0.5 : negative samples
- 1 batch : positive samples 25% + negative samples 75%
-
Hierarchical sampling
- R-CNN의 경우 이미지에 존재하는 RoI를 전부 저장해 사용하다 보니, 한 배치에 서로 다른 이미지의 RoI가 포함되었다.
- Fast R-CNN의 경우 한 배치에 한 이미지의 RoI만을 포함시켰기 때문에, 한 배치 안에서 연산과 메모리를 공유할 수 있다.
-
결점
- selective search를 통해서 region을 추출하기 때문에 완벽한 end-to-end구조가 아니다.
faster R-CNN
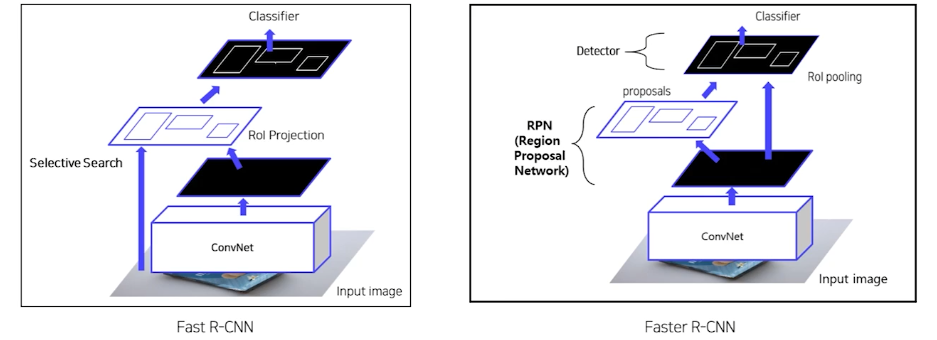
-
Anchor box
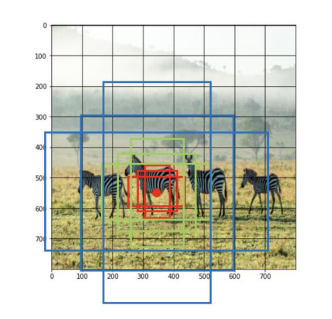
각 cell마다 n개의 다양한 크기의 box, 다양한 비율의 box를 만들어낸다. -
Region Proposal Network (RPN)
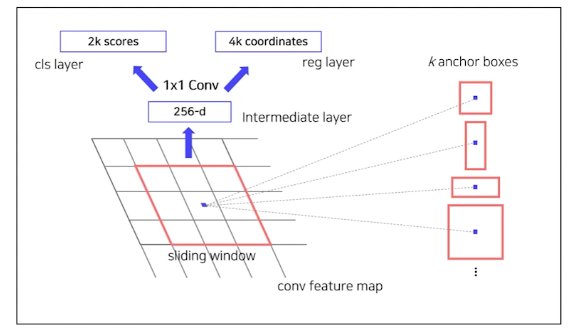
anchor box 안에 객체가 있는지 없는지 판별하고, 객체가 있다면 anchor box를 미세조정해주는 역할을 한다.
더 자세히 구조를 살펴보면, 다음과 같다.
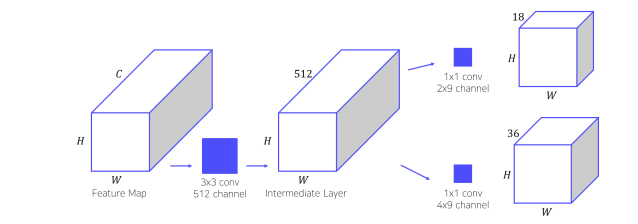
- 원본이미지가 CNN을 통해 feature map으로 나온다. 이를 input으로 받는다.
- 3x3 conv을 수행하여 intermediate layer를 생성한다.
- 1x1 conv을 수행하여 bounding box regression을 수행한다. 이를 통해 4(bounding box)x9(num of anchors) = 36채널을 생성한다.
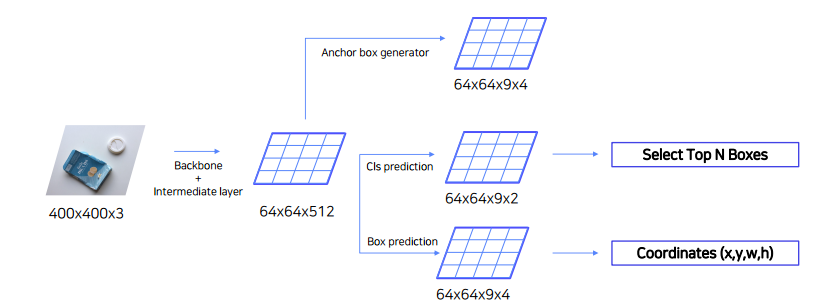
- 종합적으로 9개의 anchor box에 대해서 classification 과정에서 객체를 포함하고 있는지 없는지를 판별하고, Bbox regressor 과정에서 미세조정방식을 찾기 때문에 위 이미지와 같은 차원을 갖는다.
-
NMS
- 겹치는 영역을 없애기 위해 사용하는 것
- Class score를 기준으로 proposals 분류한다.
- IoU가 0.7 이상일 때 겹친다고 판단하고 제거한다.
-
train 과정
- Region Proposal Network (RPN)
- RPN 단계에서 classification과 regressor학습을 위해 앵커박스를 positive/negative samples 구분
- dataset
- IoU > 0.7 or highest IoU with GT: positive samples
- IoU < 0.3: negative samples
- 0.3 <= IoU <= 0.7 : 학습에 사용하지 않음
- loss function
- classification : cross entorpy loss
- Bbox regression : MSE Loss
- RPN 이후
- dataset
- IoU > 0.5: positive samples → 32개
- IoU < 0.5: negative samples → 96개
- 128개의 samples로 mini-bath 구성
- dataset
- Loss function
- classification : Cross entropy
- Bbox regressor : smooth L1
- RPN과 Fast RCNN 학습을 위해 4 steps alternative training 활용했으나, 요즘에는 Approximate joint Training을 활용한다.
- Region Proposal Network (RPN)
Summary