
1. Kubernetes란?
Kubernetes 줄여서 k8s라고 불리는데. 쿠버네티스는 과연 무엇일까요? 구글을 통해 간단하게 확인할 수 있는 정의는 '컨테이너화된 워크로드와 서비스를 관리하기 위한 확장가능한 오픈소스 플랫폼'이라는 것입니다.
보통 간단한 서비스 환경 구성시, 하나의 서버에 여러 개의 컨테이너를 올려서 사용할 수 있습니다. 그런데 서비스의 크기가 커지게 되고 운용해야 할 서버가 늘어나고 컨테이너 수가 수백, 수천개가 되면 관리 하기가 너무나 힘들어집니다.
마이크로서비스 아키텍처가 점차 발전함에 따라 점점 더 서비스를 작게 만들게 되고 아주 적은 자원으로도 서비스를 운용할 수 있게 됐습니다. 그러면 이렇게 늘어난 컨테이너의 수를 관리하기 위한 컨테이너 운영 환경이 필요한데, 그 대표 주자가 쿠버네티스입니다.
컨테이너 운영 환경이란?
vm, 서버에 올라가는 컨테이너 수가 많아지면서 관리는 힘들어지고 컨테이너가 장애 등 예측 못할 상황에 꺼졌을 때, 자동적으로 여유가 되는 서버에 컨테이너를 배포하는 작업이 필요합니다.(scheduling) 또 컨테이너의 상태를 체크하거나 로그를 수집하고 모니터링해서 관리해주는 환경을 말합니다.
그러면 어떻게 관리는 해줄까요?
어떻게 관리를 해주길래 요즘 대세로 이름을 날리고 있는 걸까요? 쿠버네티스는 다음과 같은 기능을 제공합니다.
• 서비스 디스커버리와 로드 밸런싱 : 쿠버네티스는 클러스터 내부에서만 사용할 수 있는 DNS를 제공합니다. 그리고 내부적으로 네트워크 트래픽을 로드밸런싱하여 안정적으로 배포하게 해줍니다.
• 스토리지 오케스트레이션 : 로컬 저장소, 공용 클라우드, NFS 등 대부분의 스토리지를 지원하며 설정 한 번으로 자동으로 마운트까지 할 수 있습니다.
• 오토스케일링 : 원하는 상태를 등록하여 해당 상태를 지속적으로 유지하게 할 수 있습니다.
• 자동화된 빈 패킹 : 컨테이너를 노드에 맞춰서 리소스를 자동으로 할당해줍니다.
2. 핵심 개념
쿠버네티스는 알아야 할 개념은 많지만 그 중에 꼭 알고 가야 할 개념을 주관적으로 정리해 봤습니다.
바로 Desired State와 Object 입니다.
1) Desired State
Desired State란, 원하는 상태라는 뜻인데. 쿠버네티스는 대부분의 설정들을 yaml 파일로 저장합니다. 이 yaml 파일에 쿠버네티스 양식에 맞게 내가 원하는 상태를 기록해 놓으면 자동적으로 해당 상태를 유지해줍니다.
예를 들어, 나는 Pod(최소 구성 단위)을 5개 만들거야! 라고 설정하면 쿠버네티스는 yaml 파일을 분석하여 자동적으로 Pod을 5개 생성해줍니다. 그리고 안에 돌아가고 있는 컨테이너가 장애가 나서 꺼질 경우나 의도적으로 서버를 끌 경우, 처음 설정했던 5개를 맞추기 위해 다시 컨테이너를 생성해주게 됩니다.
이는 Pod 뿐 아니라 대부분의 작업들을 이런 식으로 설정하게 됩니다.
2) Object
오브젝트의 경우, 뒤에서 자세히 설명할 예정인데. 쿠버네티스가 관리하는 상태(State)들을 오브젝트(Object)로 정의합니다.
아래는 오브젝트의 상태 작성 양식인데. 각 오브젝트마다 입력해야 할 내용은 다르지만 대표적인 내용으로만 적어 놨습니다.
apiVersion :
kind :
metadata :
name :
labels :
app:
spec :
... • apiVersion
api 버전을 표시하며 현재 v.123 버전까지 나와있으며 간단하게 v1으로 작성해도 됩니다.
쿠버네티스는 REST API를 기본으로 사용한다. 쿠버네티스 내 외부의 통신은 모두 REST API 호출을 사용하며 모든 것을 API 오브젝트로 취급합니다.
• kind
오브젝트의 종류입니다. service, controller, volume, pod 등 다양하게 있습니다.
• metedata
오브젝트의 이름이나 라벨등을 지정합니다.
• spec
각 컴포넌트에 대한 상세 설정을 적을 수 있습니다. 오브젝트의 종류에 따라 내용은 달라집니다.
3. Architecture
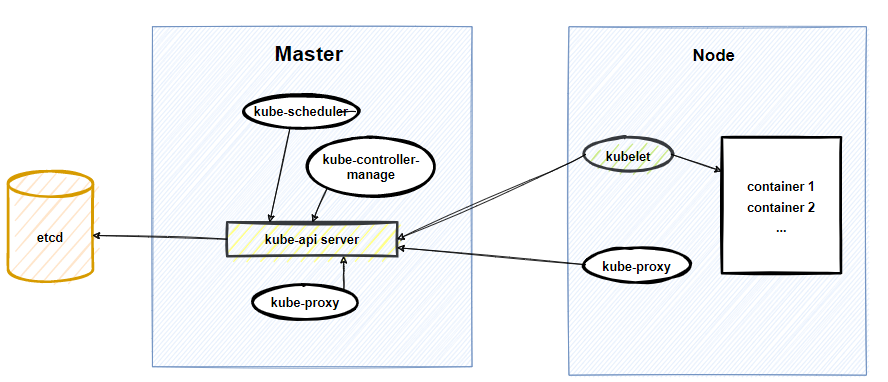
쿠버네티스는 크게 두 가지로 구성됩니다. 하나는 클러스터를 관리하는 마스터(Master)와 컨테이너를 생성하고 실행하는 작업을 하는 노드(Node)입니다.
자세히 보면 대다수가 kube-api server를 보고 있는 것을 확인할 수 있습니다. 그만큼 kube-apiserver가 중요하다는 것을 확니 할 수 있습니다.
3-1 Master
Master는 클러스터를 관리하는 역할을 합니다. 클러스터를 관리하기 위해 내부에는 kube-apiserver, etcd, kube- kube-scheduler, kube-controller-manager가 있습니다.
하나씩 살펴봅시다.
1) kube-apiserver
쿠버네티스의 모든 통신의 중심에는 apiserver를 통해서 진행합니다. 외부에서의 접근도 내부에서의 접근도 상태를 확인하는 것도 명령을 보내는 것도 모두 apiserver를 통합니다. 모든 요청은 REST 호출을 사용합니다.
2) etcd
etcd는 key-value 저장소입니다. 클러스터 내의 설정과 state들이 이곳에 저장되고 있고 나머지 모듈들은 stateless 로 동작하기 때문에 이 저장소가 특히 중요합니다. 가능하면 백업을 주기적으로 해주면 좋습니다.
3) kube-controller manager
Kubernetes controller manager는 클러스터 내의 상태를 원하는 상태로 제어하기 위해 사용하는 데몬입니다. 원하는 상태란, pod 수가 적을 경우 원하는 상태에 적힌 수에 맞춰서 pod를 생성하는 역할을 합니다. 종류로는 replication controller, endpoints controller, namespace controller, service accounts controller가 있습니다.
4) cloud-controller-manager
클라우드 서비스를 이용할 때, 쿠버네티스와 연동하기 위해서 사용합니다. 종류로든 Node Controller, Route Controller, Service Controller, Volume Controller가 있습니다.
5) kube-scheduler
새로운 pod를 생성할 때 클러스터내에서 알맞은 노드를 선택해서 자원을 할당 후 배포해줍니다. 유기견(Pod)을 키울 수 있는 집을 적절히 조사해, 유기견이 살기에 적합한 집에 입양 보낸다고 생각하시면 됩니다.
3-2 Node
노드는 실제 Pod(컨테이너들)가 실행되는 환경을 말합니다. 이 노트 안에 있는 Kubelet, Kube-proxy, Container Runtime들은 pod를 관리하고 실행하는 역할을 합니다.
1) Kubelet
kubelet은 클러스터내의 모든 노드에서 실행되며, 노드에 할당된 Pod를 관리합니다. apiserver와 주기적으로 통신하여 로그 및 명령어를 처리하는 역할을 합니다. 또 Kubelet을 통해 Pod 내부의 컨테이너를 작업할 수 있습니다. 물론 apiserver를 통해서 가능합니다.
2) Kube-proxy
각 노드에서 실행되며, 쿠버네티스 API에 정의된 서비스를 반영합니다. 기능으로는 Pod에 연결되는 네트워크를 관리합니다.
3) Container Runtime
노드에 컨테이너를 실행하는 역할을 합니다.(ex, Docker)
3-3 kubectl
Kubectl은 쿠버네티스 클러스터를 제어하기 위한 커맨드 라인 도구입니다. 아래는 kubectl의 구문을 간단하게 정리했습니다.
터미널 창에서 kubectl 명령을 실행하기 위한 구문입니다.

• command : 생성, 삭제, 가져오기 등, 실행하려는 동작들을 나타냅니다. create, get, desctribe, delete
• TYPE : 리소스의 타입을 지정합니다. 예를 들어, pod 과 같이 오브젝트 명도 될 수 있고 종류는 다양합니.
• Name : 리소스 이름을 지정합니다. 여러 타입을 하나의 리소스 이름으로 지정할 수 있고 개별적으로 지정할 수 있습니다.
* 여러 개 : kubectl get [TYPE 1] [TYPE 2] name
* 하나 씩 : kubectl get [TYPE 1]/name [TYPE 2]/nameflags : 선택적으로 플래그를 지정합니다. 포트 번호나 주소를 지정할 수 있습니다.
4. 오브젝트(Object)
쿠버네티스 오브젝트는 가장 기본적인 구성 단위입니다. 오브젝트 구성을 작성할 때, 원하는 상태를 yaml에 기록해 놓으면 쿠버네티스는 해당 오브젝트를 생성하고 상태를 유지하기 위해서 지속적으로 작동하게 됩니다.
생성, 수정 등 이 오브젝트를 동작시키려면 쿠버네티스 API를 이용해야합니다.
모든 오브젝트는 spec과 status를 가지고 있습니다. 먼저 spec이란, 오브젝트 작성 시 적었던 '원하는 상태'를 말합니다. status는 현재 오브젝트의 현재 상태를 말합니다.
만약 spec에 pod 개수를 5개로 설정한다면 status의 pod은 5개가 됩니다. 다시 spec의 pod 개수를 3개로 설정하면 status의 pod은 바로 3개가 됩니다.
오브젝트 작성
오브젝트를 기술할 때, 방법은 대표적으로 두 가지입니다. 하나는 쿠버네티스 API를 사용하여 JSON 형식으로 보내는 것과 kubectl을 사용하여 .yaml 파일을 작성하는 것입니다.
작성해야 할 것은 오브젝트 이름과 같은 기본적인 내용과 원하는 상태인 spec을 적어야합니다.
오브젝트 spec은 오브젝트마다 다르기 때문에 잘 찾아보고 맞는 양식으로 작성해야 한다. 아래는 deployment 오브젝트를 생성하기 위한 yaml 파일입니다.
apiVersion: apps/v1 // 오브젝트를 실행하기 위한 쿠버네티스 API 버전
kind: Deployment // 오브젝트 종류
metadata: // 오브젝트를 구분하기 위한 이름, UID 또는 네임스페이스를 입력
name: nginx-deployment
spec: // 오브젝트의 원하는 상태
selector: // Label 명을 기준으로 원하는 pod를 가져온다.
matchLabels:
app: nginx // key=app, value=nginx 해당하는 pod을 명시
replicas: 2 // 최대 pod 개수를 명시
template: // 만들 pod의 상태
metadata:
labels:
app: nginx
spec: // 컨테이너에 대한 원하는 상태를 명시
containers:
- name: nginx // 컨테이너명
image: nginx:1.14.2 // Docker(예시)로 불러올 이미지 이름
ports:
- containerPort: 804-1 Pod
쿠버네티스에서 가장 기본적인 배포 단위입니다. 컨테이너를 최소 1개 이상을 가지고 있습니다. 1개씩 하면 되지 왜 1개 이상일까요? 이유는 여러 개의 컨테이너를 배포하면 볼륨과 네트워크를 공유할 수 있다는 이점이 있기 때문입니다.
그러면 공유를 통한 서비스의 이점은 무엇일까요? 예를 들어, 하나의 서비스를 위해 하나의 pod에 여러 개의 컨테이너가 생성되었다고 봅시다. 그러면 하나의 컨테이너는 쓰기 작업을 하고 다른 하나의 컨테이너는 읽기 작업을 하는 등, 작업을 나눌 수 있습니다. 마치 객체지향의 단일 책임의 원칙을 이용하는 것처럼 할 수 있다고 보면 될 것 같습니다.
Pod 작성
일반적으로 파드를 직접 작성할 일은 없습니다. controller를 통한 deployment 배포를 통해서 생성하지만 일단 작성해 보겠습니다.
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 804-2 Service
예를 들어, 서비스중인 Pod가 장애로 재시작되거나 새로 추가한다고 가정해봅시다. 쿠버네티스는 이러한 작업이 있을 때마다 새로운 ip를 생성해서 할당해줍니다. 만약 ip를 대상으로 하나의 서비스를 묶어뒀다면 새로 만들어질 때마다 바뀐 ip를 추적해서 하나의 묶음으로 만들어줘야 하는 귀찮음이 발생합니다.
쿠버네티스에서는 이러한 문제를 해결하기 위해 Service라는 해결책을 만들었습니다.
Service는 ip가 아닌 Label Selector를 사용하여 Label을 추적하고 라벨명에 해당하는 Pod들을 하나의 묶음으로 만들어줍니다. 그렇게 하나로 묶어서 DNS 명을 부여하고 동일한 서비스를 하는 여러 Pod들의 원활한 트래픽을 위해 로드밸런서 기능을 사용합니다.
Service의 종류로는 대표적으로 ClusterIP, NodePort, Loadbalancer, ExternalName이 있습니다.
ClusterIP는 클러스터 내부에서 사용하는 IP를 말합니다. 내부에서만 사용하기 때문에 외부에서는 접근이 불가능합니다.
NodePort는 클러스터 내의 노드에서 접근이 가능한 포트입니다. 노드ip:port를 통해서 서비스에 접근이 가능합니다.
LoadBalancer는 외부 접근이 가능한 공인 IP를 서비스 객체에 할당합니다.
아래는 일반적인 Service 작성 방법입니다.
Service 작성
현재 app: MyApp으로 저장된 pod가 돌아다니고 있다고 가정합니다.
[단일 포트]
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
- apiVersion : API 버전을 설정
- kind : 오브젝트 종류를 설정
- metadata : 오브젝트 명을 설정
- selector : key-value 형식으로 원하는 pod의 라벨을 지정
- protocol : 프로토콜 명을 설정
- port : client가 접속할 port
- targetPort : pod로 접속할 port
[멀티 포트]
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377
nodePort: 30100NodePort
type 필드를 NodePort로 설정하면 사용할 수 있습니다. 그러면 쿠버네티스 컨트롤 플레인은 기본값(30000-32767)으로
포트를 할당해줍니다.
NodePort에 대해 간단하게 설명하자면, NodePort ip가 1.1.1.8이고 port를 30001로 지정했다고 합시다. 그러면 Service는 해당하는 pod를 라벨을 보고 가져옵니다. 그 후, pod가 있는 1.1.1.8:30001로 요청을 하면 Service가 모아놓은 pod로 바로 연결이 됩니다.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort
selector:
app: MyApp
ports:
- port: 80
targetPort: 80
nodePort: 300074-3 Volume
컨테이너가 실행될 때, 내부의 파일들dms 임시적입니다. 만약 갑작스러운 장애로 인해 컨테이너가 종료되면 내부에 기록되어 있는 데이터는 삭제가 됩니다. 바로 이러한 문제를 해결하고 영구적으로 로그를 저장하거나 큰 데이터를 저장하며 컨테이너간 데이터 공유를 지원하는 것이 쿠버네티스 Volume 입니다.
쿠버네티스는 정말 다양한 볼륨을 지원합니다. 사용하려고 생각하는 모든 볼륨을 지원한다고 보면 됩니다. 설정할 수 있는 볼륨의 종류는 아래와 같습니다.
1) emptyDir
이름을 보면 알 수 있듯 빈 디렉터리를 뜻합니다. Pod를 생성할 때, 생성되며 Pod가 사라지면 같이 삭제됩니다. 이 볼륨 역시 컨테이너간 공유가 가능합니다. 워커노드의 디스크에 생성됩니다.
따로 디스크가 아닌 'memory'로 설정할 수 있지만 권장하지 않습니다.
apiVersion: v1
kind: Pod
metadata:
name: emtpy_pod
spec:
containers:
- image: k8s.grcr.io/..
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name : cache-volume
emptyDir: {}2) hostPath
hostPath는 pod가 실행되고 있는 워커로드의 디스크를 사용하는 방식입니다. 같은 워커로드에 실행되는 pod라면 서로간 공유가 가능합니다. 하지만 pod가 재생성 됐을 때, 다른 노드로 갈 수 있기 때문에 권장하는 방식은 아닙니다.
apiVersion: v1
kind: pod
metadata:
name: host-test
spec:
containers:
- image : k8s.gcr.io/~
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name : test-volume
path: /data // 워커노드의 디렉터리 위치
type: Directory3) PV & PVC
PV(Persistence Volume)과 PVC(Persistence Volume Claim)은 hostPath와 비슷하게 어떠한 저장소를 공유하기 위해서 사용하지만 같은 노드에서만 사용이 가능한 hostPath와는 다르게 PV는 다른 노드의 Pod와도 공유가 가능하게 해줍니다.
PV와 PVC에 대한 간단한 정의로는 PV는 클러스터의 리소스이고 PVC는 PV에 대한 요청입니다.
관리자가 사용하려는 스토리지(NFS, iSCSI 등)을 볼륨크기와 접근 권한을 정의하고 사용자는 PVC를 통해 원하는 볼륨을 정의하면 쿠버네티스에서 알맞은 PV를 바인딩해줍니다.
3-1) 프로비저닝(provisioning)
먼저 프로비저닝이란, 사용자의 요구에 맞게 자원을 배포해 두고 요청 시 바로 사용할 수 있는 상태로 만드는 것입니다.
PV를 프로비저닝는 할 수 있는 방법에는 정적 프로비저닝과 동적 프로비저닝이 있습니다.
-
정적 프로비저닝
앞서 말한 것처럼, 관리자가 직접 하나하나 PV를 생성해 놓는 것입니다. 그러면 사용자는 PVC를 작성하여 알맞은 PV를 바인딩할 수 있게됩니다. -
동적 프로비저닝
만약 사용자가 원하는 PV가 없으면 어떡해야 할까요? 그럴 때 사용하는 것이 동적 프로비저닝입니다. PVC를 작성하고 원하는 PV가 없다면 자동으로 사용자가 요청한 PVC에 맞는 디스크를 생성하고 PV를 만들어서 바인딩해줍니다.
3-2) PV 작성
다음은 PV를 작성하는 방법입니다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: slow
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /tmp
server: 172.17.0.2- kind : 오브젝트 종류를 PesistentVolume을 명시해야 합니다.
- volumeMode : Filesystem과 Block을 사용할 수 있는데. Block은 raw 볼륨을 사용합니다. 이를 쓰지 않는다면 Filesystem으로 설정하시면 파일시스템을 자동으로 만들어줍니다.
- accessModes : ReadWriteOnce(하나의 노드에서 읽기/쓰기), ReadWriteMany(다수의 노드에서 읽기/쓰기), ReadWriteOncePod(단일 pod에서 읽기/쓰기)
- persistentVolumeReclaimPolicy : PVC를 다 사용하고 난 뒤, 사용했던 데이터를 남길 지(Retain),지울 지(Delete)를 선택할 수 있습니다.
- storageClassName : PV는 스토리지클래스 이름을 설정할 수 있습니다. 그러면 PVC를 작성할 때 사용자가 사용하고 싶은 PVC의 클래스 이름을 설정하여 해당 볼륨만을 바인딩할 수 있게 됩니다.
3-3 PVC 작성
다음은 PVC의 작성하는 방법입니다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: claim-test
spec:
accessModes:
- ReadWriteOnce
volumeMode : FileSystem
resources:
requests:
storage: 8Gi
storageClassName: slow
selector:
matchLabels:
release: "stable"
matchExpressions:
{key: enviroment, operator: In, values: [dev]}- resources.request.storage : 원하는 용량을 설정합니다.
- matchExpressions : 키와 값의 목록과 연산자를 사용해서 작성합니다. 위에 들어 있는 내용을 간단히 해석하면
key : enviroment // key가 enviroment
operator: In // value 값이 dev에 해당하는 PV를 가져오라는 것 입니다.
values: dev
4-4 Controller
컨트롤러는 보일러의 온도조절기와 같다고 볼 수 있습니다. 보일러를 원하는 온도를 맞추면 실내 온도를 측정해서 원하는 온도에 맞게 온도를 조절해 줍니다.
컨트롤러도 이와 같습니다. 오브젝트에 원하는 상태를 적어서 만들면 Pod를 '현재 상태'와 '원하는 상태'를 비교해서 '원하는 상태'로 유지하도록 관리해줍니다.
상태 확인은 Apiserver를 통해서 진행합니다.
컨트롤러의 종류로는 Replication Controller(RC), Replica Set(RS), Deployment, DaemonSet, Stateful Set, CronJob 등이 있습니다.
간단하게 정리하면,
- Replication Controller(RC) : 만들 Pod의 수와 상태 그리고 Label을 기준으로 가져올 selector가 있습니다.
- Replica Set(RS) : RC와 동일하지만 Set 방식의 Selector를 사용합니다.
- DaemonSet : 각 노드마다 하나의 Pod를 제공해줍니다. ex) 로그, 모니터링 등
- Deployment : 가장 기본적인 컨트롤러입니다.
- StatefulSet : 상태가 없는 다른 컨트롤러와 다르게 상태가 있는 컨트롤러입니다. 상태가 있다는 것은 pod가 사라지더라도 데이터를 보존할 수 있습니다.
- Job : 마치 용병같이 필요한 작업을 위해 Pod를 생성하고 작업이 끝나면 Pod를 제거합니다.
5. 배포 방식
배포방식은 대표적으로 Deployment, Replication Controller, ReplicaSet, DaemonSet, Job 등이 있습니다.
5-1 Deployment
가장 기본적인 컨트롤러중 하나입니다. 아래는 Deployment 작성 예시입니다.
apiVersion: v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
containerPort: 80- kind : 오브젝트 종류를 Deployment로 선언
- metadata-name : nginx-deployment 라는 이름으로 오브젝트 명을 지정
- replicas : 관리할 파드의 개수(원하는 상태)
- selector : Deployment가 관리할 파드를 찾는 방법을 정의합니다. label 명이 'app: nginx'인 pod를 가져오도록 정의합니다.
- template : 만약 replicas에 정의한 수보다 pod가 적다면 template에 명시된 상태로 pod를 생성합니다.
5-2 Replication Controller
현재 Replication Controller보다 ReplicaSet 방식을 권장하여 사용하고 있지만 그래도 알아두는 것도 나쁘지 않습니다.
Deployment와 별 차이 없기 때문에 작성부터 살펴보겠습니다.
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
replicas: 3
selector:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
containerPort: 805-3 ReplicaSet
ReplicaSet은 Replication Controller의 새로운 버전입니다. 차이점은 selector에 있습니다. ReplicaSet은 이름에서 알 수 있듯 Set 방식을 사용하며, selector에 matchLabels가 들어 있다면 set 방식을 사용한다는 뜻입니다.
그러면 set방식을 사용한다는 것이 무슨 차이일까요?
두개의 pod이 있다고 가정해봅시다. 각 라벨은 app: example1, app:example2 라고 설정합니다. replication controller는 selector를 통해서 app에 매칭되는 value를 하나만 가져올 수 있습니다.
반면에 ReplicaSet의 경우,
selector:
matchExpressions :
- {key: app, operator: In, values: [example1, example2]}
같은 key 값에 여러 개의 value 값을 포함시킬 수 있습니다.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: Replica-test
labels:
app: test-replica
spec:
replicas: 3
selector:
matchLabels:
app: test-replica
template:
metadata:
labels:
app: test-replica
spec:
containers:
- name: nginx
image: nginx5-4 DaemonSet
DaemonSet은 모든 노드에 동일 Pod를 추가해줍니다. 만약 노드가 클러스터에서 제거된다면 해당 Pod도 제거되고 DaemonSet을 삭제하면 해당하는 Pod들도 모두 정리됩니다.
일반적인 사용 용도로는 모든 노드에 동일하게 로그 수집, 모니터링 데몬 실행시킬 수 있습니다.
apiVersion: v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluent-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernets.io/master
operator: Exists
effect: Noschedule
containers:
- name: fluentd-elasticsearch
image : quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory 200Mi
volumeMouns:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationgracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers-
tolerations:
- key: node-role.kubernets.io/master
operator: Exists
effect: Noschedule
쿠버네티스는 각 노드별 taint명을 지정할 수 있습니다. taint로 지정된 노드는 컨트롤러에 스케줄링 되지 않기 때문에 tolerations로 지정해야지만 스케줄링이 가능합니다.
위는 key: node-role.kubernets.io/master 지정한 노드를 포함해서 Pod를 생성하겠다는 의미입니다. Noschedule은 toleration이 완전히 일치하는 경우에만 pod를 배포할 수 있습니다 -
terminationgracePeriodSeconds : pod에 종료 요청을 보내고 30초간 대기 후 종료되지 않는다면 강제 shutdown 되게 합니다
5-5 Job
Job이란, 특정한 임무를 pod에게 주고 해당 일이 수행되면 삭제하는 작업을 수행합니다. 만약 성공적으로 완료하지 못했을 경우, 다시 진행하겠다고 설정한다면 새로 생성해서 다시 시작하게 됩니다.
완료여부에 따라 추가 진행방향을 설정할 수 있습니다. 또 cronJob을 설정하여 주기적으로 Pod를 생성하여 작업을 진행할 수 있습니다.
다음은 Job의 예시입니다.
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4- command : Pod에서 실행할 명령어를 명시해줍니다.
- restartPolicy : 만약 예상치 못한 상황이 발생해 pod가 장애가 발생했을 때의 처리 방식을 지정합니다. Always(항상 재시작), OnFailure(비정상 종료 발생 시 컨테이너 재시작), Never(재시작 하지 않음) 기본값은 Always 입니다.
- backoffLimit : 재시작 횟수를 지정합니다. 기본값은 6입니다.
