작년에는 광복절에 했던 인프콘이 올해는 8월2일 금요일날 열렸다. 장소는 작년과 동일한 코엑스 그랜드볼룸에서 진행을 하였고, 나는 9시까지 부랴부랴 도착하였는데 역시나 사람들은 많았다😆
 |
 |
 |
섹션을 듣기전 여러 부스에서 하는 이벤트에 참여하기 위해서 돌아다녔고, 이번부스에는 datadog, 무신사, 도커, 여기어때, 번개장터, 아임웹, 점핏 등등이 운영을 했다. (반가운 점핏친구들 😘, 여기어때에서 뽑기로 3등 나와서 캠핑의자를 받고, 번개장터에서는 치약과칫솔세트를, Jetbrain에서는 예쁜 양말을, 도커에서는 티셔츠 당첨으로 예쁜티셔츠를 받았다 꺄올🤭)
 |
 |
 |
 |
자, 그럼 본격적으로 발표를 들으러 가보자, 내가 들은 발표 시간표는 다음과 같다.

첫번째, 질문이 답을 바꾼다: AI시대, 좋은 답을 이끄는 질문

AI는 평소 관심 있게 바라보고 공부하고 있는 주제 중 하나이기에 이번 섹션을 선택하였고, 데이터 분석가인 권정민님의 발표를 들었다.
질문의 중요성과 AI 시대에서 좋은 질문을 통해 원하는 답을 얻는 방법을 다루었다. 강의는 4세 어린이가 하루 평균 300개의 질문을 하고, 부모가 최대 14시간 동안 질문에 답해야 한다는 예시로 시작되었고, 질문은 정보를 얻고 이해를 돕고 비판적 사고를 유도하며 대화를 촉진하고 감정을 표현하고 행동을 촉구하는 등 다양한 역할을 한다.
 |
 |
AI 시대에는 질문이 답을 바꾸는 중요한 요소로 작용하며, 특히 LLM(Large Language Models)을 효과적으로 활용하기 위해서는 명확하고 목적이 분명한 질문이 필요하다. 좋은 질문은 목적이 분명하고, 측정 가능하며, 명확한 답변을 유도할 수 있어야 한다. 예시로 "한국에서 사람들이 아이폰을 더 좋아해?"라는 질문보다는 "한국에서 2023년 1년간 아이폰 판매량이 갤럭시 판매량보다 더 많아?"라는 질문이 더 명확한 답변을 유도할 수 있는 것 처럼 말이다.
 |
 |
이번 강의를 통해 질문의 힘을 다시 한번 깨닫게 되었고, 앞으로 질문을 할 때 더 목적이 드러나고 측정 가능하고 명확하게 하여 원하는 답변을 받기 위해 노력해야겠다고 느꼈다. 특히 챗봇에게 물어볼 때는 어떻게 질문해야 하는지를 다시 한번 되짚어보는 기회가 되었다.
두번째, 디버깅 마인드셋: 디버깅의 고통을 절반으로 줄여주는 고수들의 행동패턴 따라하기
문제가 발생시에 문제를 찾아내고 해결하는 과정은 개발자의 역량에 따라 천차만별이고 효율적인 디버깅은 프로젝트의 성공에 큰 영향을 미친다. 이러한 디버깅의 중요성을 인식하고 있기에 이번 강의를 통해 고수들의 디버깅 패턴을 배우고자 하였다.

디버깅은 "마법"이 아닌 "마술"이다
-> 트릭(고수들이 인지적 작업이 담긴 행동패턴)을 알고 손기술(행동패턴을 따라하며 훈련하고 체화하기)를 익히면 누구나 배울수 있는 기술이다.
인터뷰한 결과 고수들은 디버깅의 3단계,
원인파악, 문제해결, 사후처리 중에서 원인파악에 많은 시간을 들인다고 한다.
 |
 |
그리고 디버깅 고수들은 매 디버깅마다 심적표상이 쌓이며 똑똑해진다고 한다. 여기서 심적표상이란, 마음 속에 존재하는 지식 구조로 정보를 이해, 기억, 분석, 활용해 올바른 결정을 내리도록 도와주는 것이다. 디버깅 패턴 인식과 의사 결정을 위한 Decision Tree 같은 것이다.
자, 그럼 문제 원인 파악을 위한 5단계 가이드 에 대해 알아보자.

| 문제 원인 파악을 위한 5 단계 가이드 | |
|---|---|
| 사전 | 작업을 위한 계획 세우기(시간분배 등) |
| 1. 문제 정의 | 이정표 만들기 : 내가 지금 어떤 문제를 풀려고 하는거지?, 이게 없으면 당장 중요하지 않은 문제에 빠져 들어 시간을 허비할 수 있음 |
| 2. 정상 동작 정의(가장 중요한 단계) | 심적 표상 만들기. '정상적인 환경에서 어떤 조건에서, 어떤 순서로, 어떤일이 벌어져야 하는가?' 현재 벌어지는 일을 관찰 + 관찰한 정보 및 이미 알고 있는 정보 적어보기 올바른 동작을 정의하지 못하겠다면 그걸 정의하기 위한 추가 정보를 여러 소스에서 수집해야 함(도움요청, Git, 공식문서, 구글링, GPT..) |
| 3. 최소 재현 환경 구축하며 관찰 | 직접 재현하기. '문제가 있는 부분을 어떻게 핀포인트하여 격리시킬까?' 가능하다면 문제 발생 시점을 정확히 확인(에러모니터링, Git, Slack) 문제가 발생 했던 사용자의 환경과 동작을 그대로 따라함 내 환경에서 재현이 안 된다면 재현 조건 파악을 위한 추가 정보를 여러소스에서 수집해야함(로그심기, 사용자인터뷰..) |
| 4. 차이를 발생시키는 다양한 원인 탐색 | 머릿속 지도 펼치기. '두 환경의 차이가 어디에서 왔을까?' 추상적이든 구체적이든 떠오르는대로 적어보기 도메인 경험이 많을수록 첫번째 옵션이 진실일 가능성이 높으나, 주니어는 훈련을 위해서라도 3개 정도는 적어보는게 좋다. 다양한 옵션을 적기 어렵다면 추가 정보를 여러 소스에서 수집해야 함.(구글링, Git, GPT, 동료에게 설명하기, 산책하기..) |
| 5. 가설 설정 및 검증 | 옵션을 '검증 가능한 가설' 형태로 문장화(ex: A가 B로 되어있는 게 C현상의 원인이라면, B를 B'로 변경했을 때 C가 C'로 바뀌어야 한다) 실제로 작은 변경을 가하면서 가설대로 현상이 변하는지 관찰(이 과정에서 문제가 전이됐으면 시간 다시 잡고 1단계부터 재시작) 가설이 틀렸다면(오히려좋아) 무엇때문인지 적어보고 다음가설로 넘어감 끝내 원인 파악이 안 된다면, 원인파악을 위한 추가 정보를 여러 소스에서 수집해야함(구글링, GPT, 동료에게 도움받기, 산책하기..) |
위의 5단계가 1, 2, 3, 4, 5 순서대로 진행되지 않는다. 2, 3, 1, 4 이렇게도 변경된다. 그리고 가장 중요한 인지적 도구는 디버깅 마인드셋 자체이다.
추가로, 디버깅 고수들의 도구와 습관에 대해서 언급해주셨다. 디버깅 고수들은 능서불택필(글씨를 잘 쓰는 사람은 붓을 가리지 않는다)일 것 같지만, 실제로는 도구를 매우 가린다고 한다. (ㅋㅋㅋㅋㅋㅋ그래서 개발자는 좋은 키보드를 사용할려는거 아닐까..)
디버깅 도구의 예로, 자바스크립트 개발자는 크롬 개발자 도구를 이용하여 디버거를 잘 사용한다고 한다. (이 얘기를 듣고 반성하며, 개발자 도구의 디버거를 잘 이용해보자고 다짐하는 계기가 되었다.😅)
그리고 디버깅 고수들의 습관으로는
TDD: Test Driven Development일 것 같지만, Toilet Driven Development였다. 고수들은 화장실을 자주 간다. 화장실에 가서 강제로 휴식 시간을 갖고 회고를 통해 좋은 돌파구를 찾는다고 한다.
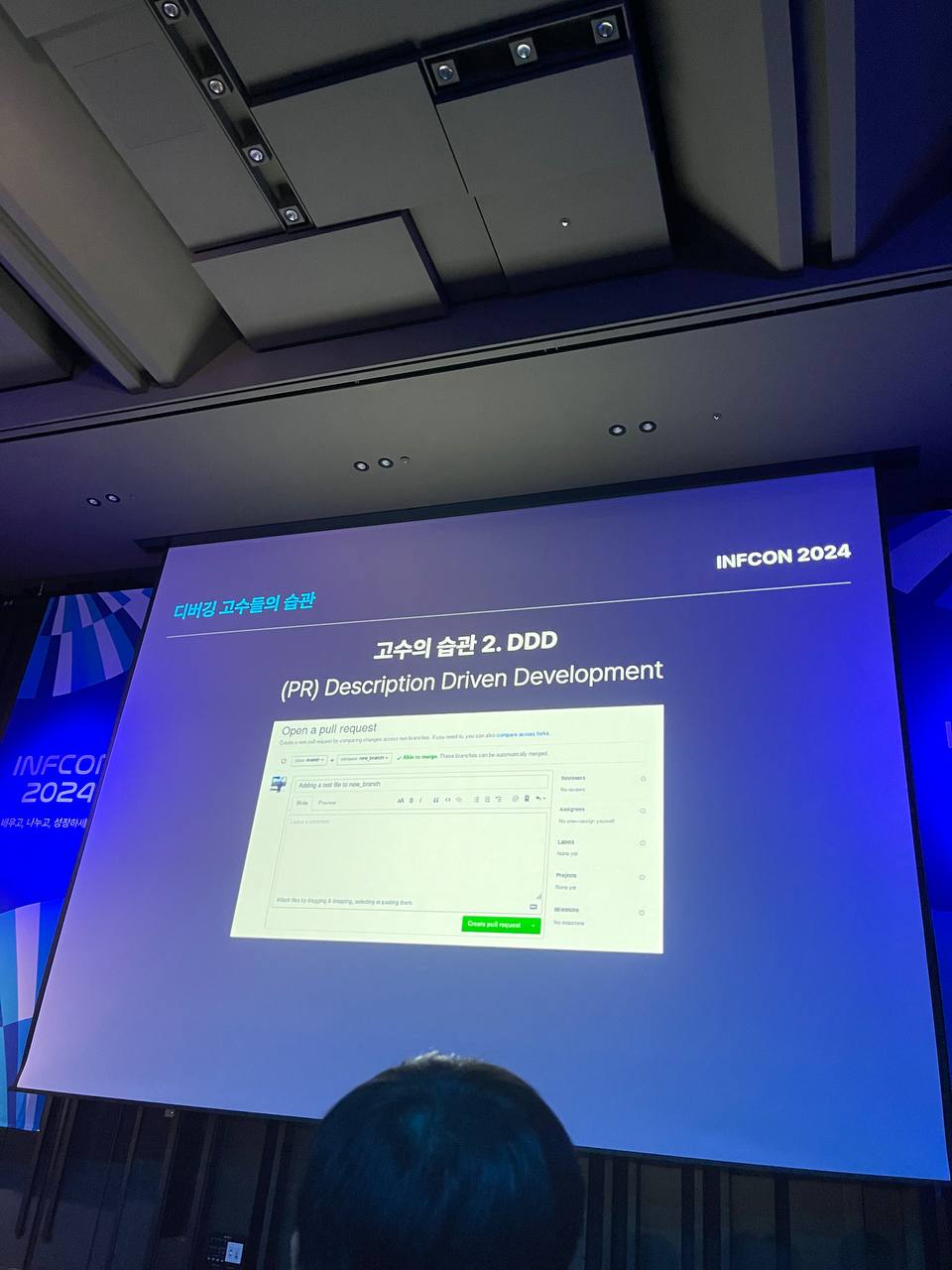
DDD: Description Driven Development의 약자로, 깃에 PR을 올릴 때 커밋을 잘게 잘 나누고 검색이 잘되게, 뇌에 잘 기억에 남게 작성한다고 한다. 커밋은 나중에 찾아보기 위한 것이고 PR은 남들에게 잘 보여주기 위한 것이다.
IDD: Issue Driven Development의 약자로, 깃헙 이슈들을 잘 올린다. 최소 재현 코드를 작성하고 이슈를 자주 올린다고 한다.
 |
 |
 |
이번 강의를 통해 배운 디버깅의 원인을 찾는 5단계 접근법이 있다는게 인상적이였다. 문제 정의에서부터 가설 설정 및 검증까지 체계적으로 진행되는 단계들을 통해 효과적으로 문제를 해결할 수 있을것 같다. 한번에 나의 디버깅 실력을 바꾸긴 어렵겠지만 고수들의 패턴에서 조금씩 가져와 실무에 적용해 볼 수 있을 것 같다. 나 역시도 디버깅의 고수가 되어보고 싶다는 생각을 하게 해준 강의였다.
그리고 TDD에서 T가 Toilet으로 설명하며 화장실에서 휴식과 회고를 통해 새로운 돌파구를 찾는다는 점이 흥미로웠다. 이는 휴식과 회고의 중요성을 다시 한번 깨닫게 해주었다.
세번째, Next.js 블로그 모범 사례 탐구 : Vercel 리더십 블로그 아키텍처 파헤치기

Next.js 등장 배경과 Next.js 13 이후
Next.js는 React의 한계를 극복하고 서버 렌더링을 쉽게 만들기 위해 만들어졌다. 초기 React는 클라이언트 사이드 렌더링에 집중되어 있었지만, 서버 사이드 렌더링의 필요성이 대두되면서 이를 효과적으로 처리할 수 있는 프레임워크로 Next.js가 등장하게 되었다. Next.js는 사전 렌더링과 파일 시스템 기반 라우팅(index routes, nested routes, dynamic routes), 그리고 API routes를 통해 풀스택 개발이 가능해졌다.
특히 Next.js 13 이후 많은 변화가 있었고, 가장 주목할 만한 변화는 React Server Component를 도입하여 컴포넌트 단위로 서버 렌더링이 가능해졌다는 점이다. App Router, Route Groups, Route Handlers, Server Actions, Partial Prerendering 등의 기능이 추가되어 더 유연하고 강력한 웹 애플리케이션을 개발할 수 있게 되었다.
Vercel 리더들의 블로그 아키텍처
본격적으로 Vercel의 CEO(라우치형)와 부사장(리형)의 블로그를 파헤쳐보는 시간을 가졌다.
| 항목 | CEO(라우치형) | 부사장(리형) |
|---|---|---|
| 설정 훑어보기 | next:"14.0.5-canary.16" | next:"14.2.0-canary.66" |
조회수 데이터 DB : redis.hgetall | 조회수 데이터 DB : postgres | |
| 컨텐츠 데이터 관리 | mdx 파일을 읽어 React 코드로 변환 | 글을 App 라우터 밖에서 데이터로 관리 |
| 라우팅과 렌더링 | Incremental Static Rendering(ISR) 사용, 1분마다 업데이트 | Partial Prerendering 사용, Suspense로 뷰카운트 가져오기 |
| 메타데이터 | 정적 메타데이터 사용, Dynamic Image Generation으로 이미지를 동적으로 생성 | generateMetadata를 이용한 동적 메타데이터 사용, 글의 제목만 받아 이미지를 동적으로 생성 |
요약하면 위의 표와 같고 추가로 Partial prerendering과 동적이미지 생성 관련하여 내용을 공유하고자 한다.
Partial prerendering(공식홈링크)
부분 사전 렌더링은 Next.js 14 에 도입된 실험적 기능이다. 이는 동일한 경로에서 정적 및 동적 렌더링의 이점을 결합할 수 있는 새로운 렌더링 모델이다. 부분 사전 렌더링이 별다른 문법이 추가되었다기 보다는 React의 Suspense를 이용하는 것이다.
PPR을 사용하기 위해서는 다음과 같다.(부사장(리형) 블로그를 토대로 코드를 작성하겠다)
next.config.mjs
const nextConfig = {
experimental: {
ppr: true,
},
};
export default nextConfig;/app/blog/[slug]/page.tsx
export default function Blog({ params }) {
let post = getBlogPosts().find((post) => post.slug === params.slug);
return (
<section>
<h1 className="title font-medium text-2xl tracking-tighter max-w-[650px]">
{post.metadata.title}
</h1>
<div className="flex justify-between items-center mt-2 mb-8 text-sm max-w-[650px]">
<Suspense fallback={<p className="h-5" />}>
<p className="text-sm text-neutral-600 dark:text-neutral-400">
{formatDate(post.metadata.publishedAt)}
</p>
</Suspense>
<Suspense fallback={<p className="h-5" />}>
<Views slug={post.slug} />
</Suspense>
</div>
<article className="prose prose-quoteless prose-neutral dark:prose-invert">
<CustomMDX source={post.content} />
</article>
</section>
);
}이렇게 함으로써 부분 사전 렌더링을 할수 있고, 이는 곧 느린 데이터 요청으로 인해 전체 페이지가 막히는 것을 방지하고 사용자의 경험을 높여 줄 것이다.
og 태그에 동적 이미지 생성
실무에 og 태그에 이미지를 넣는 방식은 서버에서 받아온 데이터를 기반으로만 생성해줬고 동적으로 이미지를 생성하는 방법은 이번 강의를 통해 알게 된 것중 하나이다. 자 그럼 어떻게 동적으로 생성하게 하는지 코드로 알아보자.
export const metadata = {
title: 'Making the Web. Faster',
description: 'Our vision of the Web is a global realtime medium for both creators and consumers, where all friction and latency are eliminated',
openGraph: {
title: 'Making the Web. Faster',
description: 'Our vision of the Web is a global realtime medium for both creators and consumers, where all friction and latency are eliminated',
images: [{ url: '/og/making-the-web-faster' }]
}
}images에 url로 /og/making-the-web-faster를 통해 app라우터의 api 핸들러를 통해서 이미지를 동적으로 생성하게 되는 것이다.
import { ImageResponse } from "next/og";
// 보기 편하기 위해 스타일은 제거한 코드이다.
export async function GET(_req: Request, { params: { id } }) {
const posts = await getPosts();
const post = posts.find(p => p.id === id);
if (!post) {
return new Response("Not found", { status: 404 });
}
return new ImageResponse(
(
<div>
<header>
<div>
Guillermo Rauch
</div>
<div />
<div>rauchg.com</div>
</header>
<main>
<div>
<div>
{post.title}
</div>
</div>
<div>
{post.date} – {post.viewsFormatted} views
</div>
</main>
</div>
)
);
}위 방식을 보고 "오"를 머리속에 외쳤고 개인프로젝트 or 실무에 적용 해야겠다 싶었다.
마지막으로, Vercel 리더들의 블로그 아키텍처를 이번 강의를 통해 깊이 있게 이해할 수 있어서 좋았고, 두 거장의 개발 방식을 직접 살펴볼수 있었던점도 큰 배움이 되었다. 각자의 방식이 다르지만 최적의 성능과 사용자의 경험을 제공하기 위해 각자의 방법으로 최선을 다하고 있음을 알 수 있었다.
하조은님의 마지막 말이 있다.
완벽한 답을 찾기보단 상황에 맞는 적절한 답을 찾으시길
나 역시도 기술을 선택하거나 개발을 진행할 때 주어진 상황과 조건에 맞게 최선의 답을 찾으려고 노력하는 편이다. 완벽한 답을 찾기보다는, 현재의 상황과 조건에 맞는 최선의 해결책을 찾는 것이 더 현실적이고 효과적이다. 각 프로젝트마다 요구사항과 환경이 다르기 때문에, 그에 맞춰 유연하게 대응할 수 있는 능력이 중요한 것 같다. 이러한 마인드셋을 가지고 개발에 임한다면, 더 많은 문제를 해결하고, 더 나은 결과를 도출할 수 있을 것이다.
네번째, 멀티패러다임 프로그래밍의 시대 : 객체지향과 함수형을 섞어야할 때!
이번 섹션은 인프런에서 이미 "함수형 프로그래밍과 JavaScript ES6+" 강의를 통해서 알고 있던 강사님이기도 했고 워낙 유명한 유인동님의 섹션이기에 주저없이 선택했다. 그리고 멀티패러다임 프로그래밍이 무엇인지 자세히 알고자 강의를 듣게 되었다.

멀티패러다임 언어를 효과적으로 사용하기 위해 타입스크립트로 Tagged Templates(해당 문법에 대해선 알고있다 생각하고 따로 언급하지 않겠다)를 만들면서 라이브코딩으로 멀티패러다임 개발 패턴을 소개해주셨다. (정말 기대 가득, 이때부터 집에 가서 돌려봐야지 하면서 동영상을 찍기 시작했다!!)
유인동님이 직접 라이브 코딩으로 보여주었고 거의 37분 정도 라이브 코딩을 하나하나 글로 설명하기 어려우니 전반적인 코드를 보고 말하고자하는 의미를 전달하고자 한다.
import { concat, flat, map, pipe, reduce, zip } from '@fxts/core';
import { escapeHtml } from './helper';
// function* concat(...arrs) {
// for (const arr of arrs) {
// yield* arr;
// }
// }
class Html {
constructor(
private strings: TemplateStringsArray,
private values: unknown[],
) {}
private escape(val: unknown) {
return val instanceof Html
? value.toHtml()
: escapeHtml(value);
}
toHtml() {
return pipe(
zip(
strings,
concat(
map((v) => f(v), values),
[''],
),
),
flat,
reduce((a, b) => a + b),
);
}
}
const html = (strings: TemplateStringsArray, ...values: unknown[]) => new Html(strings, values);
export function main() {
const a = '<script></script>';
const b = '<img onload="">';
const c = '&&&';
const users = [
{ name: 'idy', age: 40 },
{ name: 'hdy', age: 34 },
{ name: 'hdy', age: 31 },
];
const result = html`
<ul>
<li>${a}</li>
<li>${b}</li>
<li>${c}</li>
<li>
<ul>
${userItem(users[0])}
${userItem(users[1])}
${userItem(users[2])}
</ul>
</li>
<li>
${html`
<ul>
${[a, b, c].map((v) => html` <li>${v}</li> `)}
</ul>
`}
</li>
</ul>
`;
console.log('result: ', result);
console.log('result: ', result.toHtml());
}
위의 코드에서는 html 템플릿 문자열을 태그드 템플릿을 통해 문자열을 조작하는 기능을 담당한다. html 템플릿 관련된 부분은 클래스로 구조적으로 표현하고, 로직 부분은 pipe, map, concat, zip 등 함수형 프로그래밍에서 자주 사용되는 고차 함수를 사용하여 문자열 템플릿을 처리한다. 즉, 객체지향과 함수형을 함께 활용한 것이다. 유인동님은 이러한 멀티패러다임 접근 방식이 단일 패러다임으로 문제를 해결하는 것보다 더 우아하고 효율적일 수 있음을 강조하고자 하였다. 구조적인 부분과 로직 부분을 각각 객체지향과 함수형 프로그래밍으로 분리하여 개발하면, 각 패러다임의 장점을 극대화할 수 있으며, 더 나은 소프트웨어 디자인과 개발 경험을 제공할 수 있다는 메시지를 전달하고 싶었던 것같다.(내가 이해한 바로는 그러하다🧐)
라이브 코딩을 직관하면서 나 역시도 감탄했고, 나도 코딩할 때에는 저렇게 해야겠다는 다짐을 하게 만들어주었다. 이번 강의를 통해 또다른 인사이트를 얻은 것 같아서 좋았다. (감사합니다🫡)
다섯번째, 우리 회사에도 LLM 기반의 서비스를 도입할 수 있을까요?

(리뷰제조기🤖 를 깨알 홍보하며🤭) 발표 섹션 타이틀이 나에게 너무나도 매력적이였다. 왜냐하면 나의 관심사를 어떻게 실무에 적용할 수 있을까를 많이 고민하고 있던 중이였기 때문이다. 기대반 설렘반으로 해당 섹션을 들었다.
강의는 LLM(Large Language Model)의 기본 개념부터 서비스 구현, 그리고 서비스 고도화와 1년간 운영하면서 느낀 개발/운영 노하우에 대한 주제를 다루었다.
-
LLM 서비스의 사용되는 용어 정의는 다음과 같다.
LLM (Large Language Model): 자연어를 이해하고 처리하는 모델로, 수천억 개의 파라미터를 통해 성능이 크게 향상됨. OpenAI의 ChatGPT 3.5 이후 많은 LLM 모델들이 등장했으며, 클로즈 소스(예: ChatGPT, Gemini, Claude)와 오픈 소스(예: Meta Llama)로 구분됨.Prompt Engineering & Fine-Tuning:
Fine-Tuning: 이미 학습된 모델을 추가 학습시켜 특정 도메인 지식을 학습하거나 답변의 톤을 조정함.
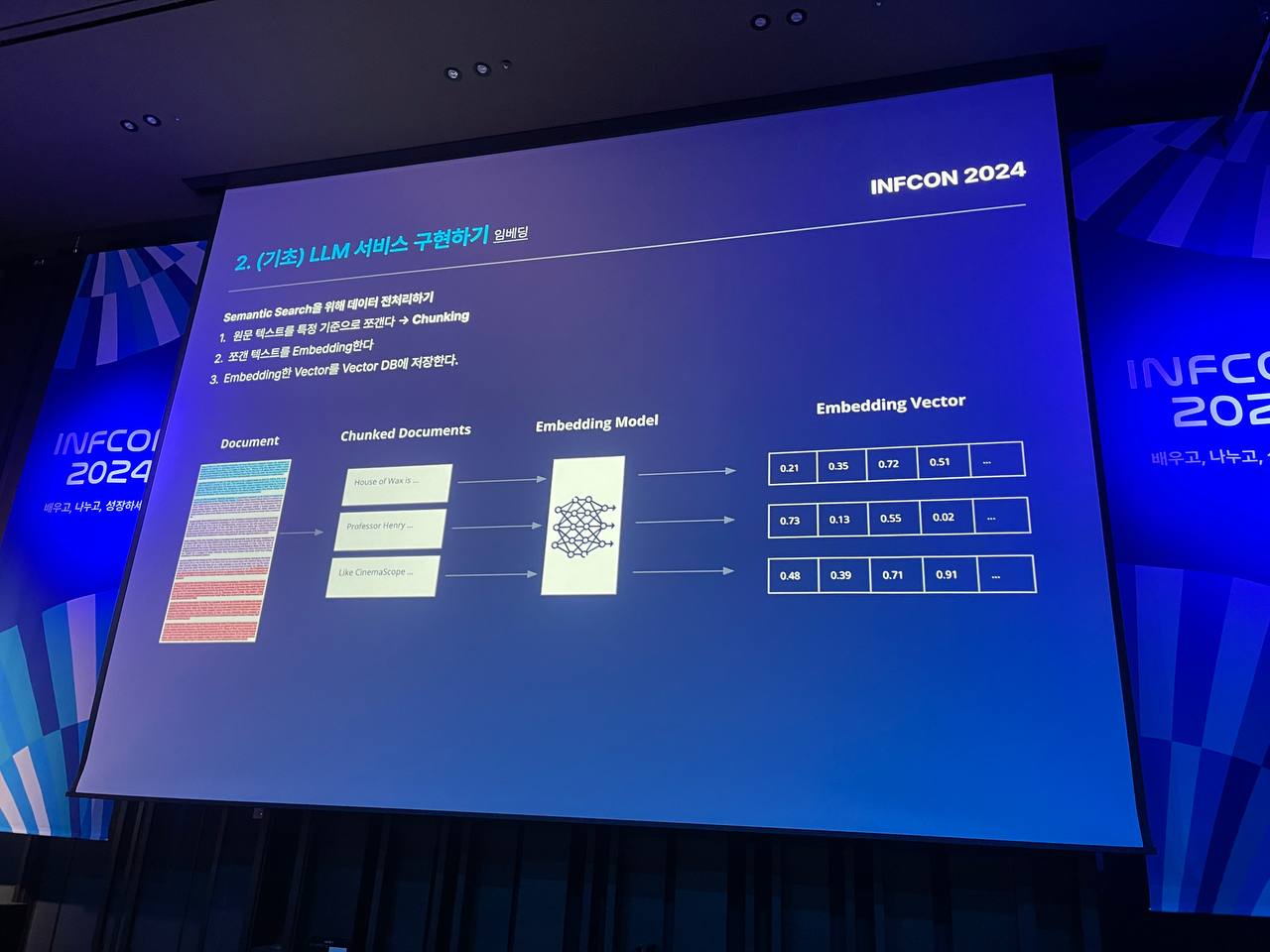
Prompt Engineering: 모델의 프롬프트(Input)를 개선하여 성능을 향상시키는 작업. 엔지니어 없이도 LLM 성능을 개선할 수 있음.RAG (Retrieval-Augmented Generation) & Embedding:
RAG: LLM이 학습하지 않은 외부 데이터를 검색하여 프롬프트에 보강하는 방법.
Embedding: 텍스트나 이미지를 벡터로 변환하여 의미적 검색(Semantic Search)을 수행하고, 벡터 DB에 저장하여 유사한 벡터를 찾는 작업.LLM Service: 금융, 법률, 헬스케어 등 다양한 산업에서 LLM이 활발히 도입되고 있으며, Salesforce, Adobe 같은 기업용 AI 솔루션으로 업무 효율을 높이고 있음.
-
LLM 서비스 구현하는 과정은 다음과 같다.
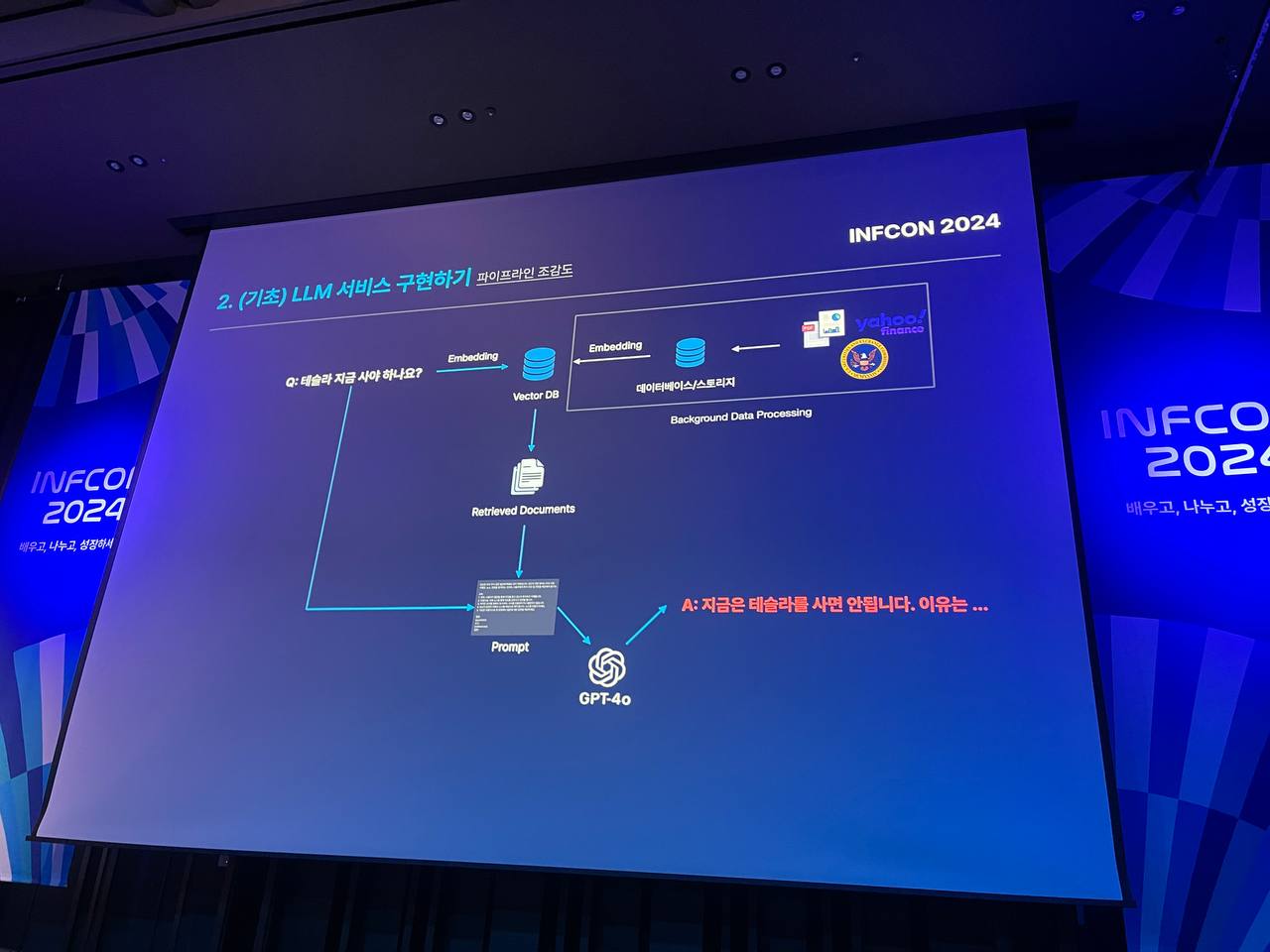
상황: 미국 주식 질문에 답변하는 봇을 만들기 위해서는
미국 주식 질문에 답할 수 있도록 프롬프트 작성하기 -> 주식 관련 데이터 수집하기 -> Semantic Search를 위해 데이터 전처리하기(임베딩) -> Vector DB 조회 결과 -> 프롬프트맞게 답변 제시



-
LLM 서비스를 고도화하기 위해서는, 다양한 데이터 소스를 추가하여 정확도를 높이고, RAG 결과를 정량적으로 개선해야 한다. 인프라 측면에서는 다양한 파일 포맷 처리와 텍스트 청크화를 통해 메타데이터를 추출하며, 카프카와 데이터베이스(RDBMS, 그래프 DB)를 활용한 체계적인 관리가 중요하다. Hallucination을 줄이기 위해 프롬프트 개선과 모델 설정 테스트가 필요하며, 질문을 잘게 쪼개고 청크에 키워드를 넣어 검색 성능을 향상시킨다. 마지막으로, 지속적인 개선을 위해 Evaluation을 통한 정량적 평가를 수행해야 한다.
이번 강의를 통해 배운 점 중 하나는 LLM 서비스를 단순히 도입하는 것에 그치지 않고, 지속적으로 데이터를 추가하고 정교한 RAG와 임베딩 과정을 통해 성능을 개선하는 것이 중요하다는 것을 알게 되었다. 또한 Hallucination 문제를 줄이기 위해 프롬프트를 개선하고 정밀한 테스트를 통해 최적의 설정을 찾는 과정이 필요함을 깨달았다.
앞으로 이번 강의에서 배운 내용을 바탕으로 내가 만든 리뷰제조기 서비스도 더욱 개선하고 발전시킬 계획이다. 이와 더불어 실무에서도 LLM 기반의 서비스를 도입할 수 있는 방향을 모색해보고자 한다.
여섯번째, 작은 조직을 위한 효과적인 디자인 시스템
이번 강의를 듣게 된 이유는 작은 조직에서는 어떻게 디자인 시스템을 구축하고 운영할까를 알고 싶어서 듣게 되었다. 인프랩의 프로덕트 리더님과 프로덕트 디자이너분이 실제로 디자인 시스템을 구축하면서 얻은 노하우를 공유하며, 작은 조직에서도 어떻게 디자인 시스템을 효과적으로 운영할 수 있는지에 대한 실질적인 조언을 들을 수 있었다.
 |
 |
먼저 디자인 시스템의 중요성에 대해 설명했다. 디자인 시스템은 다양한 페이지와 채널에서 공통의 언어와 시각적 일관성을 유지하면서, 반복되는 작업을 줄이고 더 복잡한 문제에 집중할 수 있게 해주는 도구이다. 그러나 작은 조직에서는 리소스 제약과 우선순위의 문제로 인해 디자인 시스템을 구축하기 어렵다는 현실을 짚어주었다. (나 역시도 전회사 팀에서는 리소스 부족으로 디자인 시스템 구축하는 어려움을 겪었던지라 굉장히 공감되었다.)
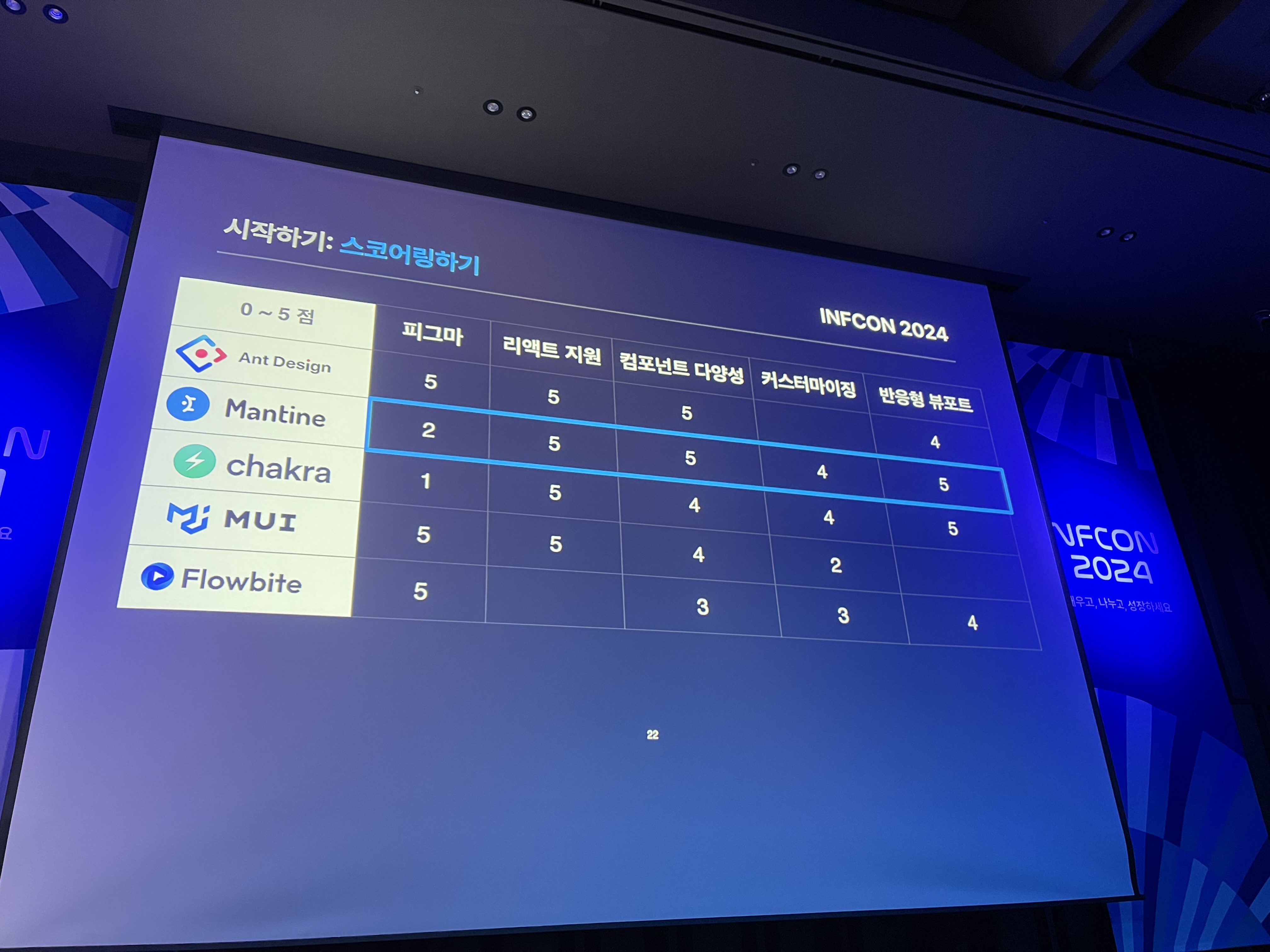
이어서 디자인 시스템을 구축하는 방법을 다루었다. 작은 조직에서는 위의 리소스가 부족하지만, 오픈소스 UI 라이브러리를 활용해 효과적으로 디자인 시스템을 구축할 수 있는 방안을 소개해주었다. 이 과정에서 Mantine을 선택한 이유와 그 장점을 설명했는데, 다양한 컴포넌트를 제공하고 반응형 디자인을 지원하며, 쉽게 커스터마이징할 수 있다는 점에서 유용하다고 했다. 또한 처음부터 모든 것을 완벽하게 하려 하기보다는 작고 빠르게 시작한 후, 점차적으로 발전시켜 나가는 것이 중요하다는 점을 강조했다.
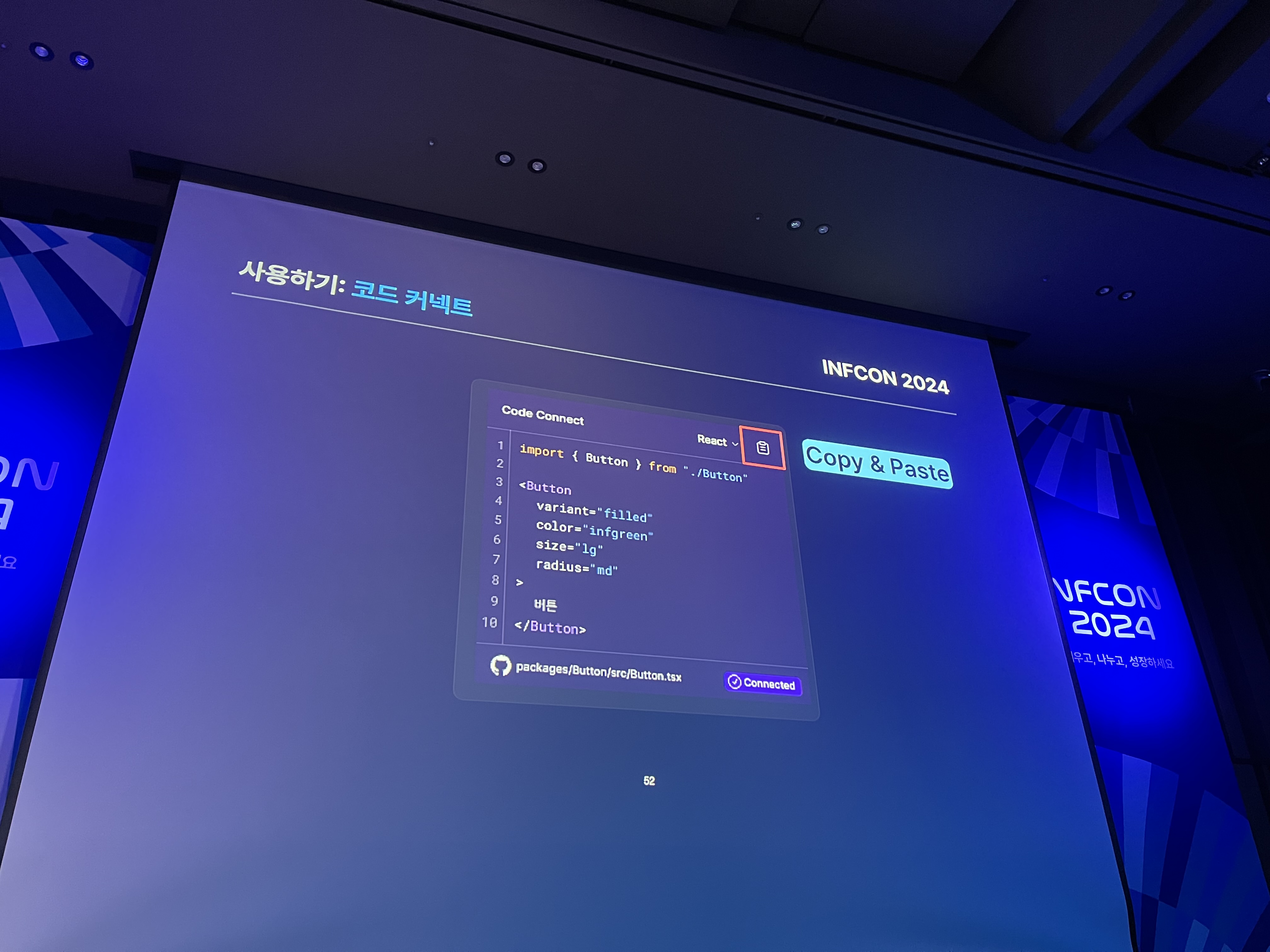
다음으로 디자인 시스템을 실제로 활용하는 과정에서 발생하는 문제와 해결 방안에 대해 논의했다. 여러 디자이너가 함께 작업할 때, 각기 다른 방식으로 컴포넌트를 사용하거나 속성을 다르게 설정하는 문제가 발생할 수 있다. 이러한 문제를 해결하기 위해 규칙을 명확히 정하고, 코드 커넥트 같은 도구를 활용해 시간을 절약하는 방법을 제시했다.
 |
 |
 |
 |
마지막으로 디자인 시스템을 다듬고 개선하는 과정에 대해 다루었다. 아이콘 사용과 UX 라이팅은 디자인 시스템의 중요한 부분이다. 특히, Mantine이 아이콘을 제공하지 않기 때문에 FontAwesome을 사용해 아이콘을 관리하는 방법을 소개했고, GPT를 활용한 UX 라이팅을 통해 사용자와의 인터페이스를 더욱 친근하고 효율적으로 만드는 방법도 제시했다. 이 과정에서 데이터를 아카이빙하고, UX 라이팅 기준을 정해 지속적으로 개선해 나가는 방법이 중요함을 강조했다.
이번 강의를 통해 작은 조직에서도 효과적으로 디자인 시스템을 구축하고 운영할 수 있는 방법에 대해 많은 영감을 받았다. Mantine을 통해 디자인 시스템을 구축하고 아이콘을 디자이너가 만들지않고 외부 라이브러리를 사용한다는 점과 UX 라이팅을 GPT를 활용한 점이 굉장히 나에겐 신선한 자극을 주었다. 그 조직에 맞는 최적의 기술을 신중하게 선택하고, 이를 효과적으로 활용한 점이 특히 인상 깊었다.👏
일곱번째, OpenAPI Generator 실전편: 효율적인 코드를 작성하는 법
OpenAPI Generator라는 생소한 기술에 대한 호기심과 토스 개발자 컨퍼런스에서 JavaScript Bundle Diet 라는 주제로 발표를 하셨던 지식공유자님의 발표섹션이기에 기대반설렘반으로 해당 섹션을 듣게 되었다.!

이번 강의에서는 OpenAPI Generator가 무엇이다라는 정의 보다는 OpenAPI Generator 어
떻게 효과적으로 사용할 수 있는지데 대해 다루었다.
 |
 |
OpenAPI Generator는 Swagger에서 제공하는 여러 가지 자동화 도구들 중 하나로, OAS(OpenAPI Specification)에 따라 개발된 RESTful API 스펙을 기반으로 클라이언트에서 사용 가능한 타입들을 자동으로 생성해 주는 도구이다. OpenAPI Generator를 통해 개발자는 반복적인 작업을 줄이고, 코드의 일관성을 유지하며, 개발 효율성을 높일 수 있다.
첫 단계로, 생성기 선택의 중요성을 강조했다.
예를 들어, TypeScript와 관련된 생성기만 해도 11가지가 있는데, 프로젝트에 적합한 생성기를 선택하는 것이 중요하다.
이어서 생성기 커스터마이징에 대한 내용을 다루었는데, OpenAPI Generator는 기본적으로 제공되는 코드를 수정하고, 템플릿을 커스터마이징할 수 있다. 이를 통해 코드의 품질과 일관성을 높일 수 있다. 예를 들어, OAS 코드에서는 한글 스키마를 사용하는 것이 정책적으로 제한되는데, 이를 해결하기 위해 유니코드 옵션을 추가하는 방법이 설명되었다. 또한, 쿼리 파라미터 인코딩을 지원하는 기능도 다루어졌다.
템플릿 엔진으로는 Mustache가 사용되었으며, 이 엔진을 통해 생성된 코드를 원하는 대로 수정할 수 있다. 그러나 문서화가 친절하지 않다는 점에서 처음 사용하는 개발자들에게는 다소 어려울 수 있다. 특히 TypeScript를 사용하는 플다팀에서는 템플릿 코드를 많이 수정하여 자신들의 요구에 맞게 커스터마이징한 사례를 소개했다.
마지막으로 생성기 옵션에 대해서도 다루었는데, 일부 기능은 피해야 할 필요가 있음을 강조하며, 숫자 1이 올바른 JSON 형식인지에 대한 예시를 통해 신중한 사용을 권장했다.
이번 강의를 통해 OpenAPI Generator에 대해 처음으로 알게 되었으며, 이를 실무에 적용해보고 싶다는 생각이 들었다. 특히, 코드 자동 생성을 통해 반복적인 작업을 줄이고, 효율성을 높일 수 있다는 점이 매력적이었다. 다만, 러닝커브가 상당히 클 수 있다는 우려도 함께 느꼈으며, 이를 극복하기 위해 지속적인 학습과 실습이 필요할 것이라는 생각이 들었다.
마지막, 나의 느낀점
이번 인프콘 컨퍼런스를 통해 다양한 주제와 깊이 있는 강의를 접하며, 여러 가지 인사이트를 얻을 수 있었다 🤗 각 세션마다 새로운 시각을 제공해주었고, 실무에 활용할 수 있는 실질적인 조언과 경험을 들을 수 있어 매우 유익하고 흥미로운 시간이었다.
개발자로서, 기술에 대한 깊은 이해와 더불어 빠르게 변화하는 기술에 유연하게 대응하는 것이 중요하다는 것을 다시금 느꼈다. 최신 기술을 단순히 따라가는 것이 아니라, 그 기술이 우리 조직이나 프로젝트에 어떻게 적용될 수 있는지 고민하고, 이를 통해 더 나은 결과를 이끌어낼 수 있는 방향으로 나아가야 한다고 생각한다. 또한 끊임없이 배우고 성장하려는 자세로 임해야겠다는 다짐을 하게 되었다.💪

그리고 개발자로서의 새로운 목표가 생겼다. 언젠가 나도 이 무대에 서서 내가 경험한 것들을 공유하고, 다른 개발자들에게 영감을 줄 수 있는 발표를 해보고 싶다는 생각이 들었다. 앞으로도 지속적으로 성장하는 개발자가 되기 위해 노력할 것이다.👩💻
