상황
- API 요청 시 502 Bad Gateway 발생
서버 구조
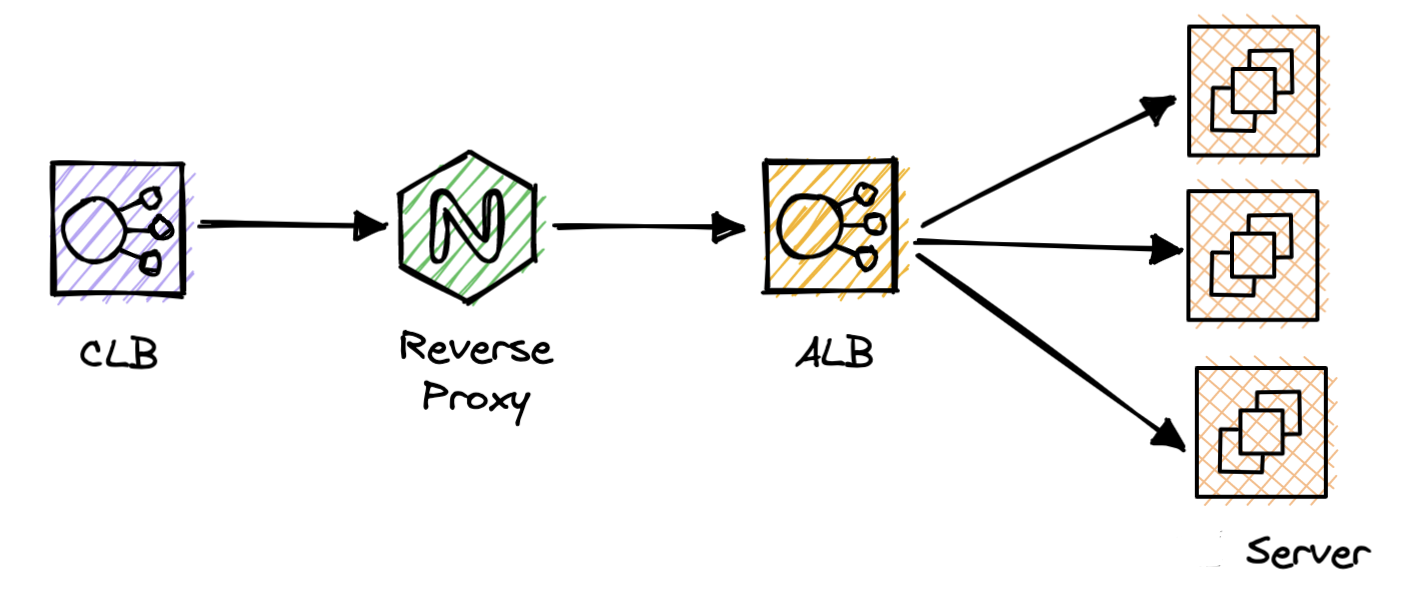
- CLB : 오래된 Classic Load Balancer , SSL 인증을 위해 생성해 놓았음.
- Reverse Proxy 서버 : 라우팅 편하게 관리 하기 위해서 고정 IP 로 서버를 만들었음.
- ALB : ECS를 위해 만든 다짐앱 로드밸런서CLB : 오래된 Classic Load Balancer , SSL 인증을 위해 생성해 놓았음.
문제인 이유
- 실제 결제와 맞물려있는 서버이므로, 결제 후 데이터를 받는 과정에서 해당 오류가 일어날 경우 실제 결제가 됐음에도 불구하고 결제 된것을 인식하지 못할 수 있음.
- 결제 이외에도 502는 유저의 서비스 경험을 저하시킴.
- 그렇기 때문에 해당 오류는 서비스 개선을 위한 꼭 필요한 작업.
해결과정 1
AWS 공식문서(https://docs.aws.amazon.com/ko_kr/elasticloadbalancing/latest/application/load-balancer-troubleshooting.html#http-502-issues)
HTTP 502: 잘못된 게이트웨이
가능한 원인:
- 연결 설정을 시도하는 동안 로드 밸런서가 대상에서 TCP RST를 수신했습니다.
- 연결을 설정하려고 했을 때 로드 밸런서가 "ICMP 대상에 연결할 수 없음(호스트에 연결할 수 없음"과 같이 대상으로부터 예기치 않은 응답을 받았습니다. 로드 밸런서 서브넷부터 대상 포트의 대상에 이르기까지 트래픽 허용 여부를 점검하십시오.
- 로드 밸런서가 대상에 대해 대기 중인 요청을 가지고 있는 상태에서 대상이 TCP RST 또는 TCP FIN과의 연결을 종료했습니다. 대상의 연결 유지 기간이 로드 밸런서의 유휴 제한 시간 값보다 짧은지 확인합니다.
- 대상 응답이 잘못된 형식이거나 유효하지 않은 HTTP를 포함하고 있습니다.
- 전체 응답 헤더의 대상 응답 헤더가 32K를 초과했습니다.
- 로드 밸런서가 대상에 연결할 때 SSL 핸드섀이크 오류 또는 SSL 핸드섀이크 제한 시간(10초)가 발생했습니다.
- 등록 취소된 대상에 의해 처리 중인 요청에 대해 경과된 등록 취소 지연 시간 오래 걸리는 작업이 완료될 수 있도록 지연 기간을 늘립니다.
- 대상이 Lambda 함수이고 응답 본문이 1MB를 초과합니다.
- 대상이 구성된 제한 시간에 도달하기 전에 응답하지 않은 Lambda 함수입니다.
- 대상이 오류를 반환하는 Lambda 함수이거나 Lambda 서비스에 의해 스로틀된 함수입니다.- 일단 AWS 공식 문서에 나와있는 502 오류의 원인은 위와 같다.
- 조금 더 자세하게 알아보기 위해 502 오류 문제를 해결하는 방법을 확인하니
HTTP 502: bad gateway 오류에는 여러 가지 원인이 있을 수 있으며,
그 원인은 대상 또는 Application Load Balancer일 수 있습니다.
오류의 원인을 확인하려면 Amazon CloudWatch 지표 및 액세스 로그를 사용하세요.
Application Load Balancer에서 오류 문제를 해결하기 전에 액세스 로그를 활성화했는지 확인하세요.
액세스 로그에서 각 필드의 의미를 이해하려면 액세스 로그 항목을 참조하세요.
데이터 포인트가 HTTPCode_ELB_502_Count 지표 아래에 나타나면 로드 밸런서가 HTTP 502 오류의 원인입니다.
HTTPCode_Target_5XX_Count 지표 아래에 나타나면 대상이 원인입니다.- 위를 통해 1번으로 오류의 원인을 찾기로 했다. Aws CloudWatch에서 해당 오류가 Target(server)의 원인인지 ELB(로드밸런서)의 문제인지 확인할 수 있다.
- CloudWatch에서 확인하기
- CloudWatch에서 모든지표 항목을 클릭한다.
- 해당 지표 목록 중 ApplicationELB 네임 스페이스를 선택한다.

- AppELB별 지표를 클릭한다.
- 위와 같이 지표 목록이 있는데 이 중 HTTPCode_ELB_502_Count와 HTTPCode_Target_5XX_Count의 값을 확인한다.
- CloudWatch에서 확인한 결과
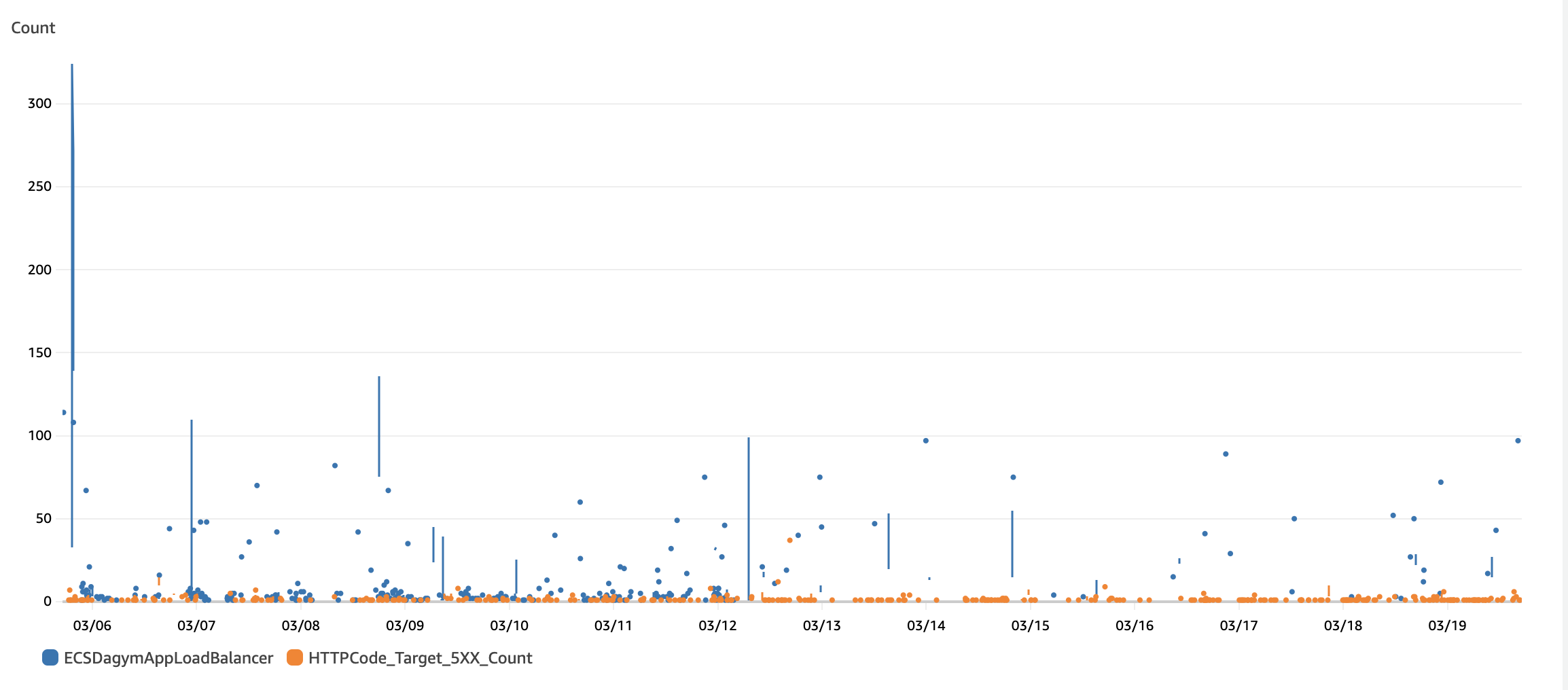
- 파란색 지표가 HTTPCode_ELB_502_Count이며, 주황색 로그가 HTTPCode_Target_5XX_Count이다. 즉, 대 다수로 많이 일어나는 지표는 HTTPCode_ELB_502_Count였고, 이는 즉 ELB가 오류의 원인을 의미했다.
HTTP 502 오류 문제 해결
**참고:**elb_status_code = "502" 및 target_status_code로
액세스 로그를 필터링하면 원인을 파악하는 데 도움이 됩니다.
그런 다음 사용 사례에 맞는 관련 단계를 완료합니다.- ELB 오류의 원인도 다양하게 존재할 수 있었고, 어떤 원인이 있을지 조금 더 명확히 하기 위해 Access Log를 활성화 시켜 확인하는 과정을 거치기로 했다.
- Access Log 활성화하기

-
EC2 항목에서 로드밸런서 메뉴를 클릭해 내가 설정하고 싶은 로드밸런서를 선택.

-
위 항목들 중 Attributes 항목을 클릭.
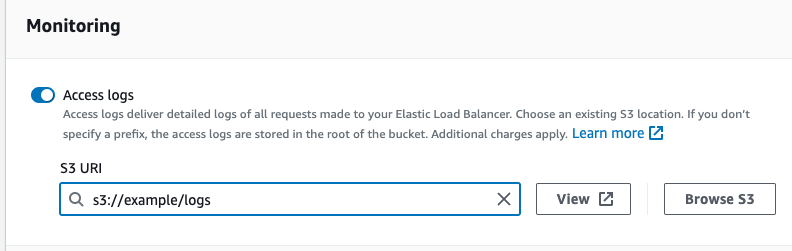
- Monitoring 항목에서 Access logs 부분을 활성화 시키고 해당 로그들은 저장하고 싶은 S3 Bucket을 활성화시켜 저장
- Access Log를 활성화한 뒤, 이를 AWS Athena를 활용하여 쿼리해보니, 502일 때 많은 경우가
request_processing_time은 0.001,
target_processing_time은 4.205,
response_processing_time은 -1- 위와 같은 경우임을 확인했다.
대상은 TCP RST 또는 TCP FIN과의 연결을 닫았지만 로드 밸런서에는 대상에 대해 처리되지 않은 요청이 있음
로드 밸런서가 요청을 수신하여 대상에 전달합니다.
대상은 요청을 수신하고 처리를 시작하지만, 로드 밸런서에 대한 연결이 너무 일찍 닫혔습니다.
이는 일반적으로 대상의 연결 유지 제한 시간이 로드 밸런서의 유휴 제한 시간 값보다 짧을 때 발생합니다.
연결 유지 제한 시간이 유휴 제한 시간 값보다 큰지 확인합니다.- 위와 같은 이유였기에, 로드밸런서의 idle timeout(유휴 제한 시간 / default = 60s)인 60초보다 서버의 keepAliveTimeout을 늘려준다.
- Express를 사용한 서버에서는 이를
/app.js
server.keepAliveTimeout = 80 * 1000;
server.headersTimeout = 100 * 1000;
(단위 = ms)
headersTimeout은 꼭 keepAliveTimeout보다 크게 설정- 위와 같이 설정할 수 있다.
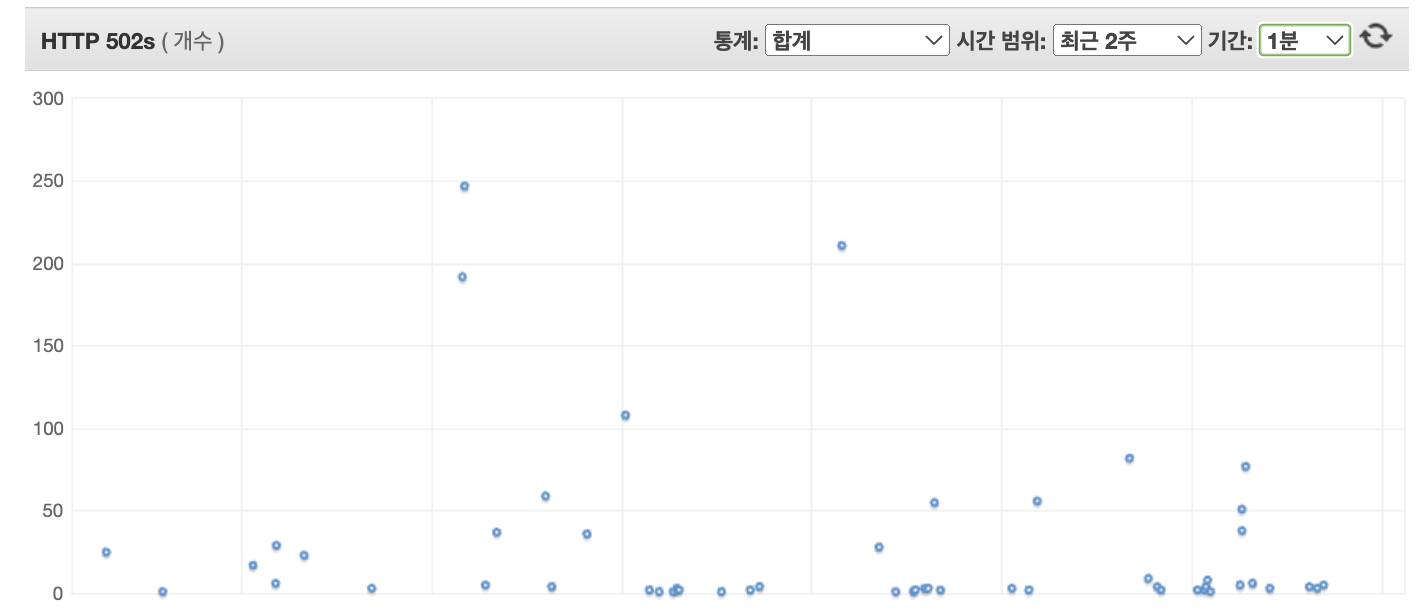
- 이후 결과값은
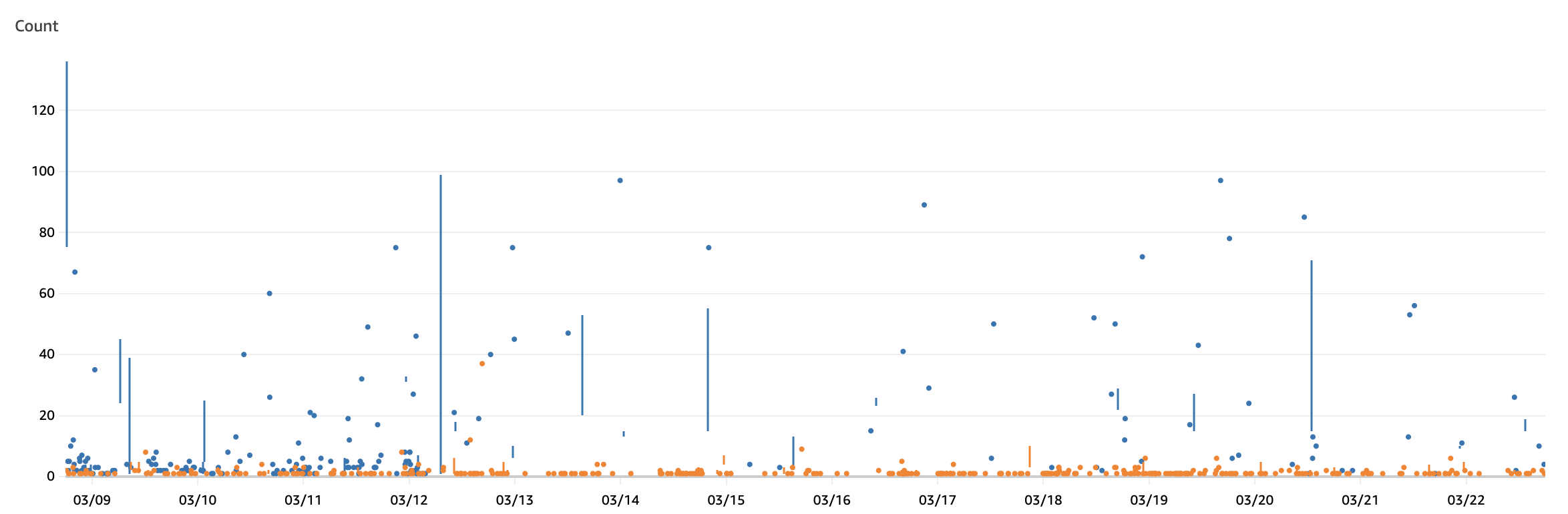
위와 같이 기존에 최대 300건 까지 발생하던 HTTPCode_ELB_502_Count가 줄어들게 된다.
해결과정 2
- 하지만 위와 같은 결과에도 아직도 꽤나 많은 건의 502 오류가 발생하고 있었다.
- 이는 아직 생각하지 못한 이외에 곳에서 오류가 발생하고 있다는 의미.
- 이후 AWS Athena를 통해 Access log를 좀 더 확인한 결과 502 오류 이전/이후 과정에 HTTP 460 에러가 발생하고 있음을 확인했다.
HTTP 460
로드 밸런서가 클라이언트에서 요청을 수신했지만, 유휴 제한 시간이 종료되기 전에 클라이언트가 로드 밸런서와의 연결을 종료했습니다.
클라이언트 제한 시간이 로드 밸런서의 유휴 제한 시간보다 큰지 확인합니다.
클라이언트 제한 시간이 끝나기 전에 대상이 클라이언트에 응답을 제공하는지 확인하거나,
클라이언트가 제한 시간을 지원할 경우 로드 밸런서의 유휴 제한 시간에 맞게 클라이언트 제한 시간을 늘립니다.- 여기서 클라이언트는 ELB에 요청을 전송하는 나의 경우 Nginx 서버가 된다.
- 이를 통해, Ngnix 설정을 수정한다.
upstream backend {
// 로드밸런서 주소
server test-12345131.ap-northeast-2.elb.amazonaws.com;
// keep alive 추가 = 연결 유지할 연결 최대 수
keepalive 64
}
server {
listen 80;
server_name example.com;
client_max_body_size 50M;
keepalive_timeout 65;
location / {
proxy_pass http://backend;
proxy_pass_header Server;
proxy_redirect off;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Scheme $scheme;
proxy_set_header REMOTE_ADDR $remote_addr;
// keepalive 설정 시 필요한 값
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}- 위와 같이 keepalive_timeout을 로드밸런서의 유휴 제한 시간(idle timeout = 60s)보다 크게 설정하고, 연결을 유지할 연결 수를 최대 64까지 연결하여, 연결이 끊기지 않게 설정하였다.
- 위와 같이 설정 후에 460 에러가 줄었음에도 502에러는 크게 줄지 않았고, 460 에러가 502에러의 직접적인 원인이 아니라는 것을 확인 할 수 있었다.
해결과정 3
- 위와 같이 확인하는 도중 AWS CloudWatch 지표 중 TargetResponseTime과 RequestCount 지표를 같이 확인하는 과정 중, 해당 값들이 502 오류가 많이 발생하는 시점과 시기가 동일한 것을 확인할 수 있었다.
TargetResponseTime이 증가하는 원인은 다음과 같습니다.
호스트의 상태가 좋지 않습니다.
백엔드 인스턴스가 너무 많은 요청에 과부하되었습니다.
백엔드 인스턴스의 CPU 사용률이 높습니다.
하나 이상의 대상에 결함이 있습니다.
백엔드 인스턴스에서 실행되는 웹 애플리케이션 종속성에 문제가 있습니다.- 위와 같은 AWS Document를 확인했고, ECS(클라이언트)의 지표를 확인하니, 해당 502오류가 있던 시점에 모두 CPU 사용량과 Memory 사용량이 급격하게 상승한 것을 확인할 수 있었다.
- 이를 통해, 서버의 요청이 많은 시기에 해당 Request를 다 받아들이지 못하고, 서버가 다운되거나 요청을 받지 못하는 경우에 오류가 생기는 것이 502 오류의 원인이라고 판단.
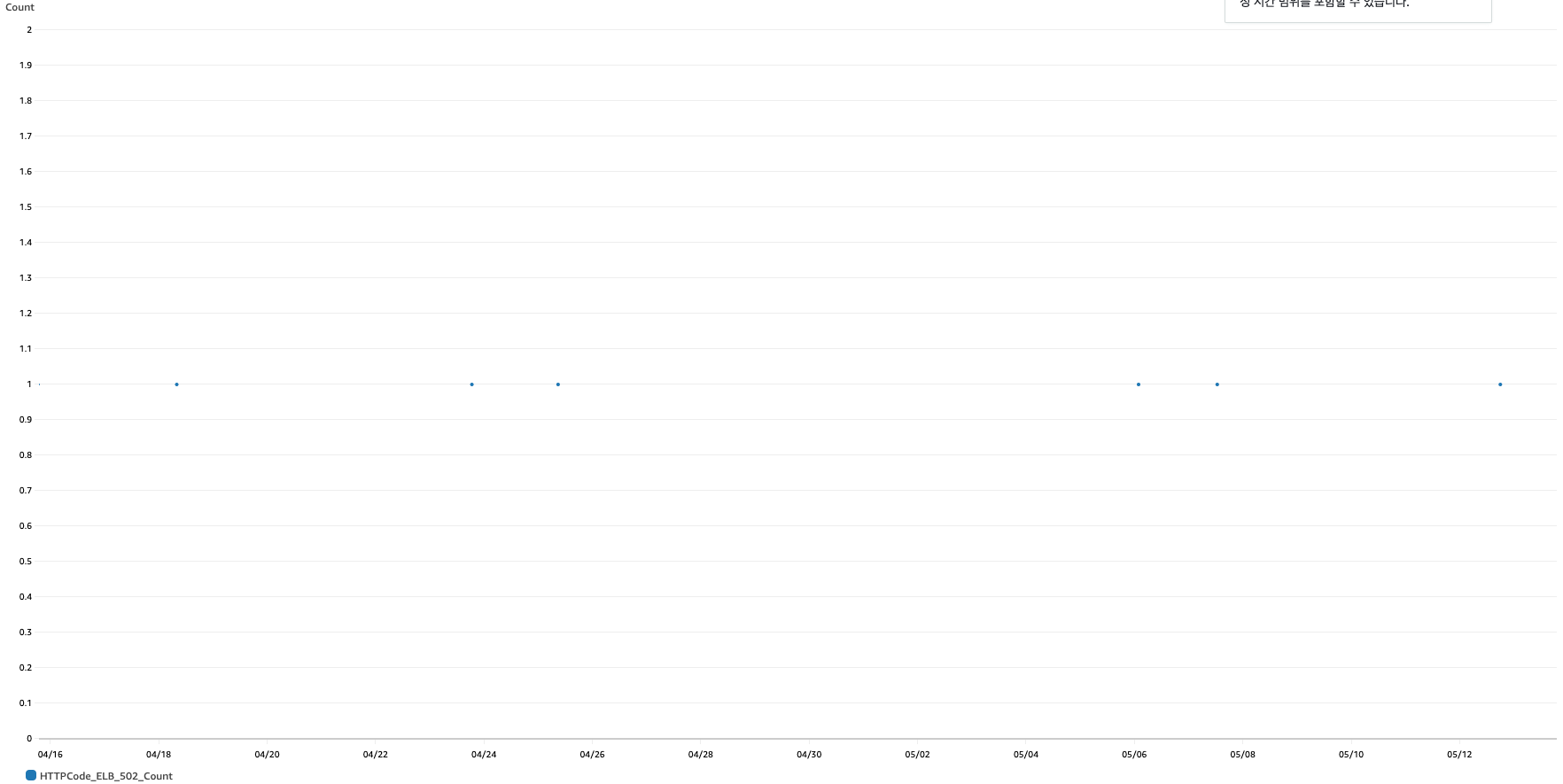
- 위와 같이 하루에 최대 1개의 502오류만 발생하는 것을 확인.
결론
- 502 Bad Gateway는 서버의 연결 상태 뿐 아니라 서버의 사용량이 증가하여 서버가 요청을 받지 못하거나 요청을 해결하지 못할때도 생길 수 있음.

백엔드 개발자