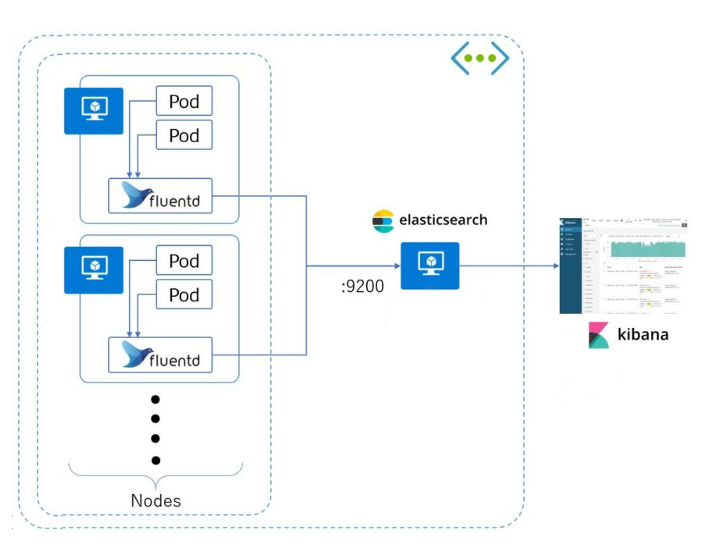
1. EFK stack이 무엇인가
- Elasticsearch, Fluentd, Kibana의 조합.
- 지속적으로 유입되는 로그 데이터를 수신하고 이 데이터를 차트와 그래프로 시각화 하는 시스템

- EFK Stack에서 Elasticsearch, Fluentd, Kibana는 다음과 같은 역할을 수행한다.
- Fluentd : 데이터(로그)를 수집해서 Elasticsearch로 전달
- Elasticsearch : Fluentd로부터 받은 데이터를 검색 및 집계하여 필요한 정보 획득
- Kibana : Elasticsearch의 빠른 검색능력을 통해 데이터 시각화 및 모니터링
2. Elasticsearch, Fluentd, Kibana란?
-
Elasticsearch
- Elasticsearch는 아파치 루씬(정보 검색 라이브러리 자유-오픈 소스 소프트웨어) 기반의 확장성이 좋은 JAVA 오픈소스 분산 검색엔진
- 많은 양의 데이터를 보관하고 실시간으로 저장, 검색, 분석할 수 있게 해줌
- Elasticsearch 아키텍쳐
- Cluster
- Elasticsearch에서 가장 큰 시스템 단위, 최소 하나 이상의 노드로 이루어진 노드들의 집합
- Node
- 하나의 단위 프로세스(Master-eligible, Data, Ingest, Tribe 노드로 구분 가능)
- Master-eligible node
- 클러스터를 제어하는 마스터로 선택할 수 있는 노드
- 역할 : 인덱스 생성, 삭제/클러스터 노드들의 추적, 관리/데이터 입력 시 어느 샤드에 할당할 것인지
- Data node
- 데이터와 관련된 CRUD 작업
- CPU/ 메모리 등 자원 많이 소모
- Ingest node
- 데이터 변환 등 사전 처리 파이프라인 실행 역할
- Coordination only node
- 로드밸런서와 비슷한 역할
- Master-eligible node
- 하나의 단위 프로세스(Master-eligible, Data, Ingest, Tribe 노드로 구분 가능)
- Cluster
- 특징
- 테이블과 스키마 대신에 문서 형식(JSON)으로 저장한다.
- 쿼리 속도가 매우 빠르며 확장성이 뛰어나다
- 에러에 대한 높은 탄성을 가지고 있으며 데이터 타입에 유연하다
- 빅데이터를 처리할 때 매우 유리하다.
-
Fluentd
- 오픈소스 데이터(로그) 수집기
- 보통 로그를 수집하는데 사용하지만, 다양한 데이터 소스(HTTP, TCP)로부터 데이터를 받아올 수 있다
- Fluentd로 전달된 데이터는 tag, time, record(JSON) 로 구성된 이벤트로 처리되며, 원하는 형태로 가공되어 다양한 목적지(ElasticSearch, S3 등)로 전달될 수 있음.
- C와 Ruby로 개발되었으며, 더 적은 메모리를 사용하는 경량버전인 Fluent-Bit와 함께 사용할 수 있다
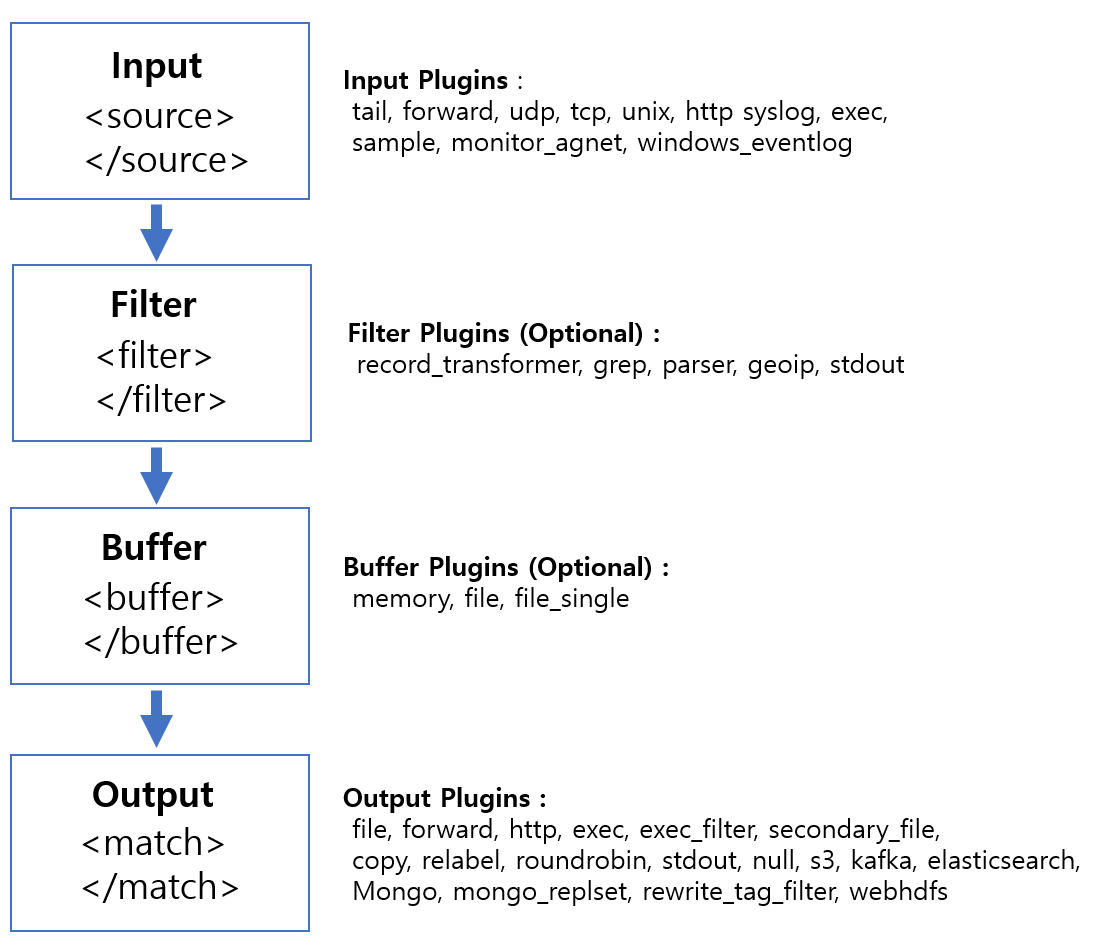
- Input, Parser, Engine, Filter, Buffer, Ouput, Formatter 7개의 컴포넌트로 구성(주로 Input → Output 의 흐름으로 이루어 지고, Parser, Buffer, Filter, Formatter 등은 Optional)
-
Input Plugins
@tail
- path 에 지정한 log를 읽어서 사용. 리눅스 tail 명령어와 같이, 파일의 끝부분을 지속적으로 읽음.
<source> type tail format json path /fluentd/log/CrmApp-out.log tag elasticsearch.crmapp_log </source>@forward
- 데이터를 전달받기 위해 사용하며, 서버간에 TCP로 로그 데이터를 수신
- forward로 전달되는 데이터는 json 이나 messagepack 형식.
<source> @type forward port 24224 bind 0.0.0.0 </source>@http
- curl 같은 명령어로 로그데이터를 http 요청으로 받을 수 있음.
<source> @type http port 9880 bind 0.0.0.0 </source> -
Output Plugins
@file
- log를 지정한 path 에 gzip 으로 압축하여 출력
<match pattern> @type file path /var/log/fluent/myapp compress gzip </match>@stdout
- Fluentd 에서 표준출력(stdout)으로 출력
<match **> @type stdout </match>@forward
- 다른 Fluentd 노드로 로그를 전달할 때 사용되며, 반드시 1개 이상을 포함해야 함
<match **> @type forward <server> name another.fluentd1 host 127.0.0.1 port 24224 weight 60 </server> <server> name another.fluentd2 host 127.0.0.1 port 24225 weight 40 </server> </match>@elasticsearch
- elasticsearch와 통신하기 위한 plugin
- bulk api를 사용하여 records 만들고 보냄
- bulk api란?
- 한 번의 api call을 통해 여러 번의 indexing과 delete 작업을 하는 api
- 이를 통해 indexing speed를 올리고 overhead를 줄임.
- bulk api란?
<match my.logs> @type elasticsearch host localhost port 9200 logstash_format true </match>
-
Kibana
- Kibana는 Elasticsearch에서 색인된 데이터를 검색하고 시각화하는 오픈소스 도구
- Elasticsearch의 데이터(로그)를 차트와 그래프 등을 활용하여 대쉬보드 형태로 시각화
3. ELK stack과의 비교
- ELK 스택은 Elasticsearch, Logstash, Kibana의 조합.
- EFK와 같이 로그를 수집하여 시각화하는 시스템
- EFK와의 차이점 = Logstash
- Logstash란?
- Logstash는 다양한 소스로부터 데이터를 수집하고 곧바로 전환하여 원하는 대상에 전송할 수 있도록 하는 경량의 오픈 소스 서버측 데이터 처리 파이프라인
- 오픈소스 분석 및 검색 엔진인 Elasticsearch의 데이터 파이프라인으로 자주 사용
- Elasticsearch와의 긴밀한 통합, 강력한 로그 처리 능력, 사전 구축된 200개 이상의 오픈 소스 플러그인을 통해 데이터 인덱싱을 돕는 Logstash는 Elasticsearch에 데이터를 로드할 때 가장 많이 사용
- Logstash란?
- Fluentd vs Logstash
- 코드 언어
- Logstash는 호스트에 자바 런타임이 필요한 JRuby
- Fluentd는 자바 런타임이 필요하지 않은 CRuby
- Fluentd는 자바 런타임이 필요하지 않다는 이점이 존재
- 이벤트 라우팅
- Logstash는 if-else 조건에 기반에 이벤트가 라우팅
- Fluentd는 태그에 기반해 이벤트가 라우팅
- 이벤트에 태그를 지정하고 각 이벤트 유형에 대해 if-else를 사용하는 것이 더 쉽기 때문에 Fluentd가 더 나은 라우팅 접근 방식을 제공
- 플러그인
- Logstash는 200개 이상의 플러그인이 존재하며 Fluentd는 500개 이상의 플러그인이 존재
- Logstash는 공식 git 저장소에 모든 플러그인을 가지고 있지만 Fluentd에는 아직 플러그인에 대한 중앙 git 저장소가 없음.
- 성능
- LogStash는 Fluentd보다 상대적으로 좀 더 많은 메모리를 사용
- 하지만 두 로그 수집기 모두 가벼운 수준이며 성능 측면에서 두 로그 수집기 모두 우수
- 지원
- LogStash와 Fluentd 모두 지원합지만 LogStash가 공식적인 Elastic 스택의 일부이므로 LogStash의 지원이 더 우수.
- 코드 언어
4. Fluent Bit이란?
- 마찬가지로 오픈 소스 및 다중 플랫폼 로그 처리자 및 전달자로서, 다양한 원본의 데이터 및 로그를 수집하고, 이를 통합하여 여러 대상에 전송할 수 있게 해줌.
- vs fluentd

- 왜 Fluent bit을 사용할까?

- 한 개의 서버가 아니라 여러 대의 서버를 사용할 경우, CPU와 메모리 사용량의 차이는 상당해짐.
- 그렇기에 fluent bit은 경량화하여 각 서버마다 설치되어 사용되는 것을 목적으로 만들어짐.
참고
https://m.blog.naver.com/jhsjsd/221875108872
https://twofootdog.tistory.com/50
https://minimilab.tistory.com/61
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html
https://aws.amazon.com/ko/opensearch-service/the-elk-stack/logstash/
https://logz.io/blog/fluentd-vs-fluent-bit/
https://docs.fluentbit.io/manual/about/fluentd-and-fluent-bit

백엔드 개발자