조회 -SELECT 문
기본 형식
SELECT [DISTINCT | DISTINCTROW] 필드이름 [AS 별칭] // 검색하고자 하는 열 이름 기술
FROM 테이블이름 // 어느 테이블에서 필드 가져올 것인지 결정
[WHERE 조건식]; // 조건문 기술 (없는 경우 기술x)- 마지막에 ';' 을 입력해 SQL 문의 끝임을 알림.
- DISTINCT SELECT 문에 'DISTINCT'를 입력하면, 검색 결과 중복되는 레코드는 한번만 표시됨.
- 테이블의 모든 필드를 검색할 경우, 필드 이름 대신 '*'입력하고, 특정 필드들만 검색할 경우 필드와 필드는 쉼표로 구분
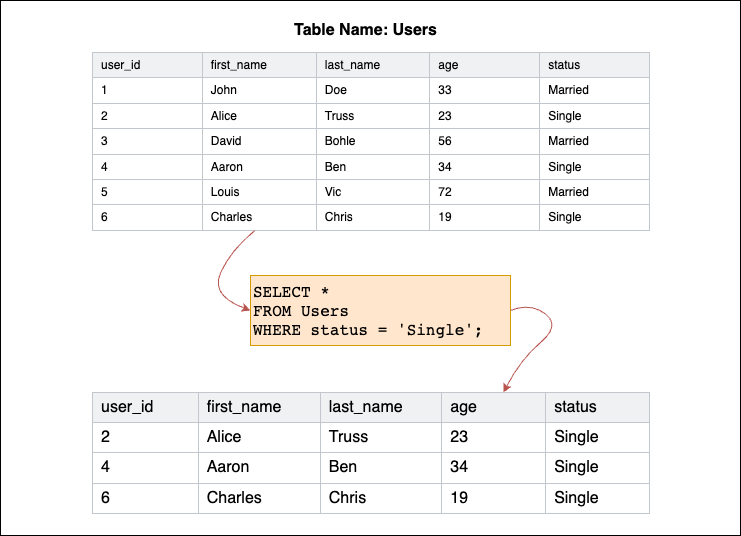
- WHERE 조건을 입력하여 특정 조건에 맞는 레코드만 검색할 때 사용
SELECT column1, column2, ...
FROM table_name
WHERE condition;-- employees 테이블에서 모든 열 선택
SELECT * FROM employees;
-- employees 테이블에서 first_name과 last_name 열을 선택
SELECT first_name, last_name FROM employees;
-- employees 테이블에서 salary가 50000 이상인 행을 선택
SELECT * FROM employees WHERE salary >= 50000;정렬 작업 (ORDER BY)
SELECT 문을 사용할 때 출력되는 결과물은, 테이블에 입력된 순서대로 출력된다.
내림차순(DESC) 혹 오름차순(ASC) 으로 정렬된 데이터들이 필요할 때는 ORDER BY 절을 사용한다.
ORDER BY 절은 항상 SELECT 문의 맨 마지막에 위치한다.
-- employees 테이블에서 salary를 오름차순으로 정렬합니다.
SELECT * FROM employees
ORDER BY salary ASC;
-- employees 테이블에서 hire_date를 내림차순으로 정렬합니다.
SELECT * FROM employees
ORDER BY hire_date DESC;
그룹지정 (GROUP BY) 및 조건 (HAVING)
GROUP BY : 특정 필드를 기준으로 그룹화하여 검색할 때 사용한다.
HAVING : 그룹에 대한 조건을 지정할 때 사용 (항상 GROUP BY 와 함께 기술해야 함)
-- employees 테이블에서 department_id별로 직원 수를 그룹화하고, 직원 수가 5명 이상인 부서만 선택
SELECT department_id, COUNT(*) AS employee_count
FROM employees
GROUP BY department_id
HAVING COUNT(*) >= 5;
함수이용한 집계
집계 함수는 여러 행의 값을 하나의 결과로 집계하는 데 사용된다.
COUNT(), SUM(), AVG(), MIN(), MAX() 등이 있다.
-- employees 테이블에서 직원 수를 구함
SELECT COUNT(*) AS employee_count FROM employees;
-- employees 테이블에서 전체 급여 합계를 구함
SELECT SUM(salary) AS total_salary FROM employees;
-- employees 테이블에서 평균 급여를 구함
SELECT AVG(salary) AS average_salary FROM employees;
-- employees 테이블에서 가장 높은 급여를 구함
SELECT MAX(salary) AS max_salary FROM employees;
-- employees 테이블에서 가장 낮은 급여를 구함
SELECT MIN(salary) AS min_salary FROM employees;
종합
-- employees 테이블에서 각 부서별 평균 급여를 구하고, 평균 급여가 50000 이상인 부서만 선택하며, 결과를 평균 급여의 내림차순으로 정렬합니다.
SELECT department_id, AVG(salary) AS average_salary
FROM employees
GROUP BY department_id
HAVING AVG(salary) >= 50000
ORDER BY average_salary DESC;
