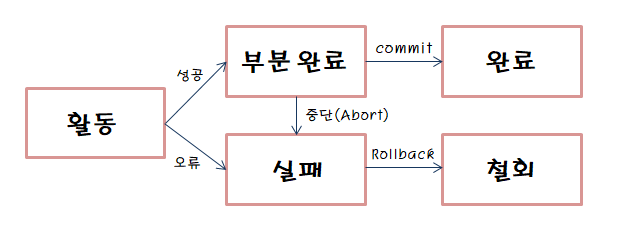
Transaction
- DB 에서 하나의 논리적 기능을 수행하기 위한 일련의 연산 집합
- 사용자가 시스템에 대한 서비스 요구시 시스템이 응답하기 위한 상태 변환 과정의 작업단위
- 하나의 트랜잭션은 Commit 되거나 Rollback 된다.
ACID 특징
원자성(Atomicity)
트랜잭션의 연산은 DB 에 모두 반영 or 전혀 반영되지 않아야 함.
일관성(Consistency)
트랜잭션 수행이 성공적으로 완료되며 언제나 일관성있는 DB 상태로 변환함.
독립성(Isolation)
한 트랜잭션이 데이터를 갱신하는 동안, 갱신작업이 완료되기 전에는 다른 트랜잭현이 접근하지 못하도록 함.
영속성(Durability)
트랜잭션의 실행이 성공적으로 실행 완료된 후에는 시스템에 오류가 발생하더라도, 트랜잭션에 의해 변경된 내용은 계속 보존
CRUD 분석
Create, Read, Update, Delete
DB 테이블에 변화를 주는 트랜잭션을 분석하여, DB 물리적 설계 시 구조를 최적화하는 목적이 있다.
테이블에 발생되는 트랜잭션의 주기별 발생 횟수를 파악하고, 연관된 테이블들을 분석하면, 테이블에 저장된 데이터양을 유추할 수 있다. 많은 트랜잭션이 물리는 테이블을 파악할 수 있어서, 디스크 구성 시 유용하다.
외부 프로세스 트랜잭션의 부하가 집중되는 DB 채널을 파악하고 분산시킴으로써,연결 지연이나 타임아웃오류를 방지할 수 있다.
인덱스(INDEX)
- 데이터 레코드에 빠르게 접근하기 위해 <키, 값, 포인터> 로 구성되는 데이터 구조
- 레코드가 저장된 물리적 구조에 접근하는 방법을 제공
- 레코드의 삽입과 삭제가 수시로 일어나는 경우, 인텍스의 개수를 최소로 하는 것이 바람직
- 기본키를 위한 인덱스 = 기본 인덱스, 그 외의 인덱스= 보조 인덱스
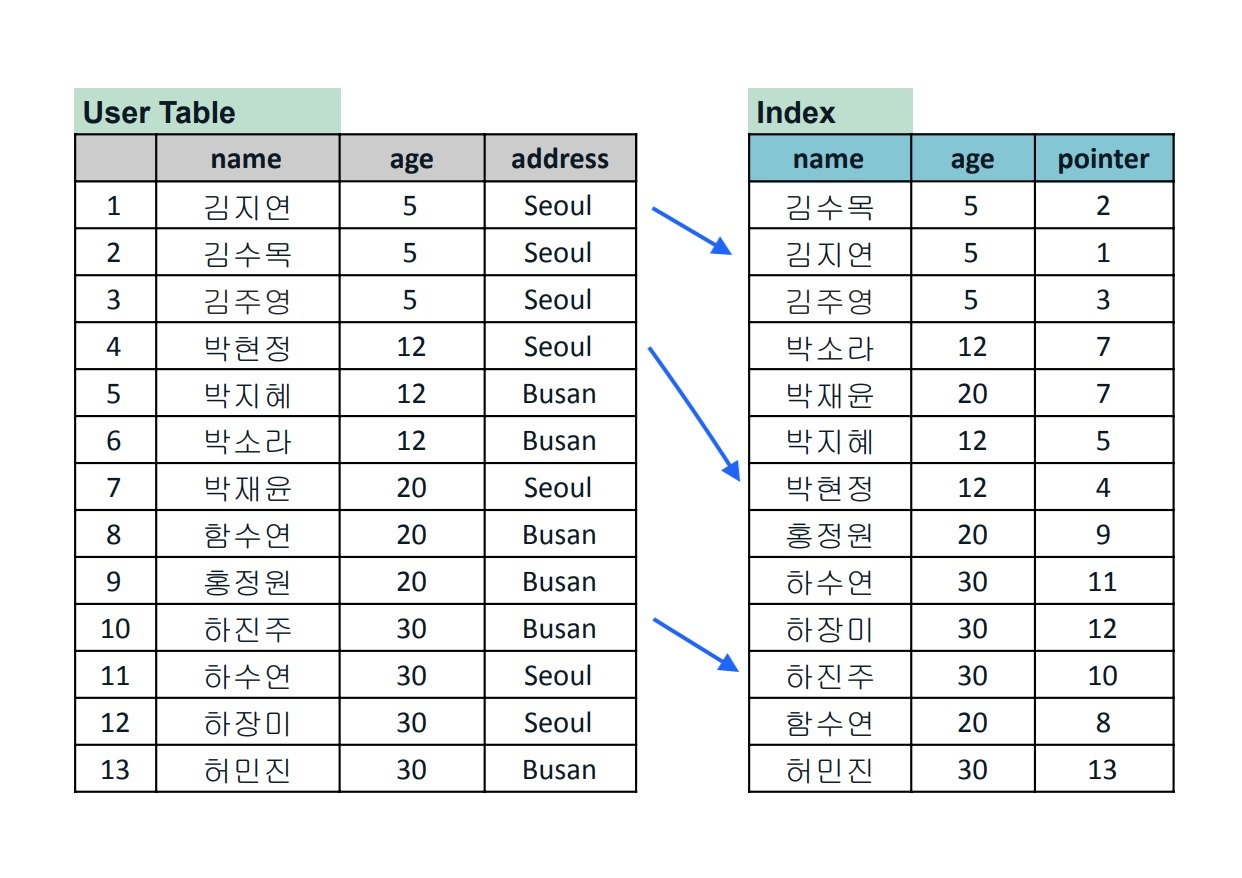
인덱스 순서 일치 여부에 따른 분류
clustered index
- 인덱스 키의 순서에 따라 데이터가 정렬되어 저장
- 실제 데이터가 순서대로 저장되어 있어, 인덱스를 검색하지 않아도 신속한 데이터 검색 가능
- 하나의 릴레이션에 하나의 인덱스만 생성 가능
non-cluster index
- 인덱스 키 값만 정렬되어 있고, 실제 데이터는 정렬x
- 데이터 검색 시 인덱스 먼저 검색한 후 실제 데이터 위치를 확인해야하므로, 검색속도는 clusted 에 비해 떨어짐.
- 하나의 릴레이션에 여러 개 인덱스 생성 가능
인덱스 구조에 따른 분류
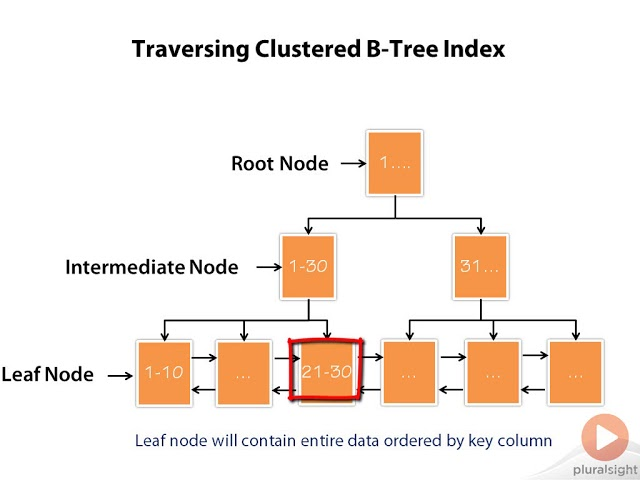
B-tree index
- 루트 노드로부터 하위 노드로 키 값의 크기를 비교해가면서 찾고자 하는 데이터를 검색하는 구조 (일반적인 인덱스 방식)
- 데이터 양에 상관없이 모든 데이터 인덱스 탐색시간은 동일
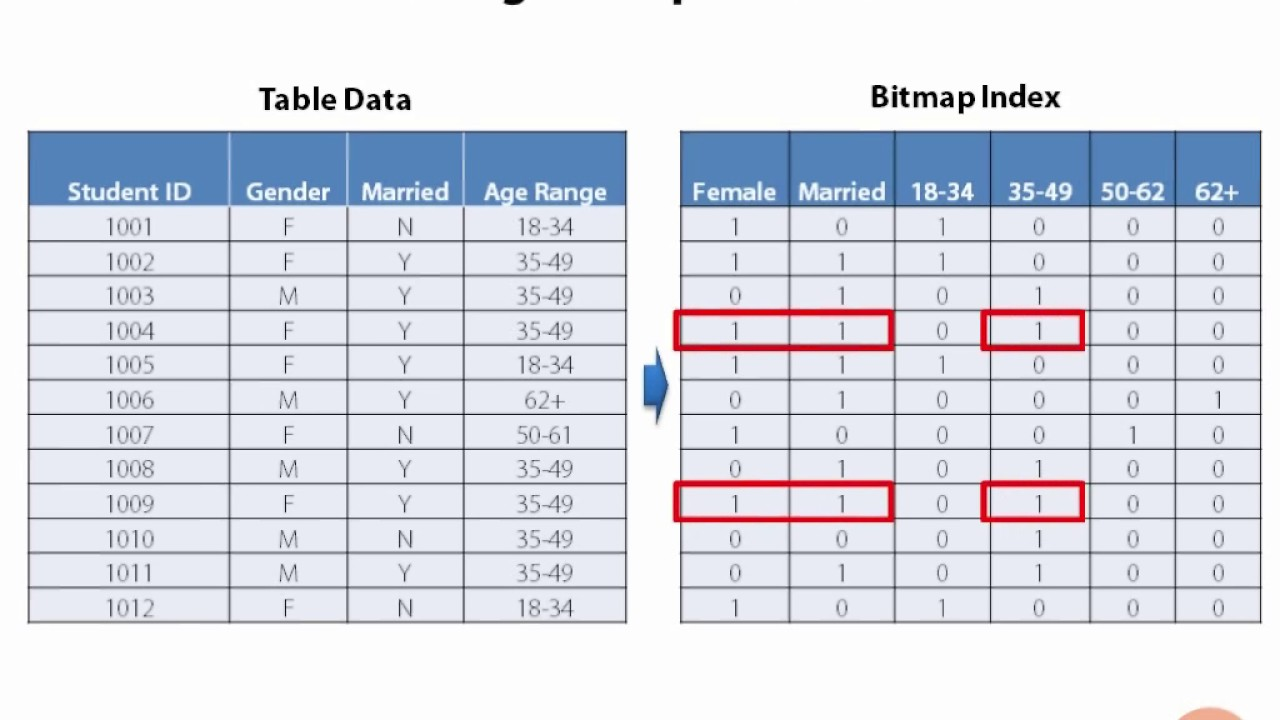
bitmap index
- 인덱스 컬럼의 데이터를 bit 값인 0 또는 1 로 변환하여 인덱스 키로 사용하는 방법
- 데이터가 bit 로 구성되어 있어 효율적인 논리 연산이 가능하고, 저장공간을 적게 차지
- 다중 조건을 만족하는 튜플의 개수 계산에 적합하고, 동일한 값이 반복되는 경우가 많아 압축효율이 좋다
함수 기반 index
- 컬럼의 값 대신 컬럼에 특정 함수나 수식을 적용하여 산출된 값을 사용
- 데이터 입력하거나 수정 시 함수를 적용해야 하므로, 부하가 발생할 수 있다. 특히, 사용자 정의함수 일 경우 부하가 더 심하다.
- 대소문자, 띄어쓰기 등에 관계없이 데이터 조회할 때 유용하게 사용