
'타이타닉 생존 여부'에 관한 데이터를 시각화해보고 간단히 분석한다.
- 데이터분석의 바이블과 같은 사례로, 데이콘의 입문 영상을 참고하여 진행했다.
1. 라이브러리 및 데이터 준비
pandas,LogisticRegression,DecisionTreeClassifier불러오기

drive.mount로, 드라이브에 올려둔 파일에 접근 후, 데이터 불러오기
(경로를 드라이브로 설정하니까 알아서 마운트 설정하는 셀 뜨긴 했음,,)

2. 탐색적 자료 분석 (EDA)
데이터를 분석하기 전에 기본적인 정보와 특징을 탐색하자.
다양한 통계값을 통한 탐색
.head()로 훈련 세트 앞부분 미리보기
- 테스트 세트와 제출용 파일도 확인
.tail()로 훈련 세트 뒷부분도 확인 가능
.shape로 데이터들의 크기(형태) 확인

.info()로 데이터셋의 기본적인 정보 확인 (⭐결측치 체크가 주 목적!!)

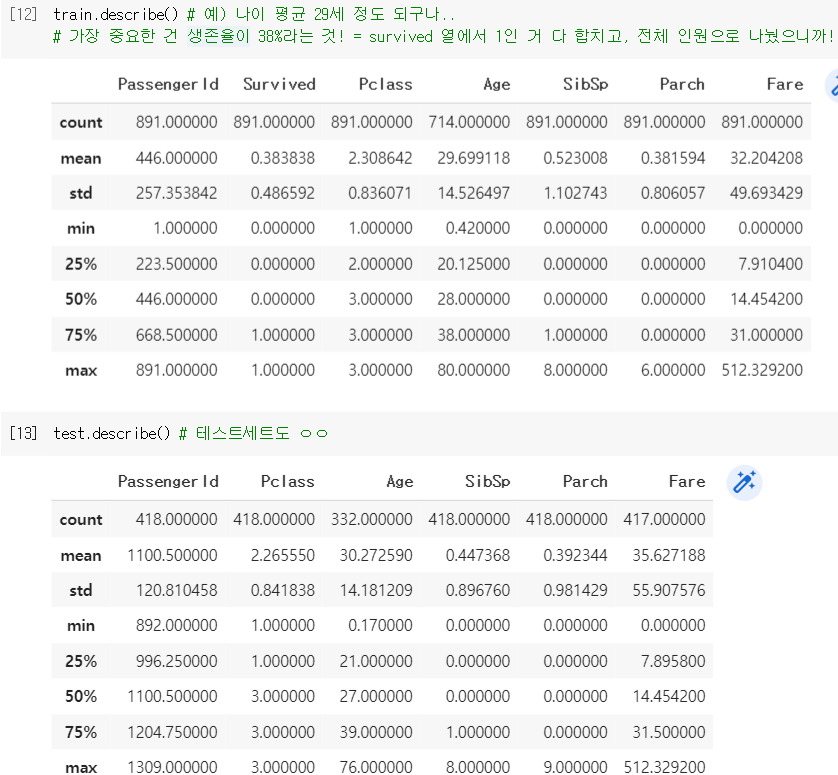
.describe()로 데이터의 기술통계량(각 column을 대표할 수 있는 통계값) 확인
❗'survived' 열의 'mean' 값 = 생존율
.value_counts()로 범주형 자료의 빈도 확인
('embarked' 열은 수치형이 아니라서 기술통계량 없었음!)
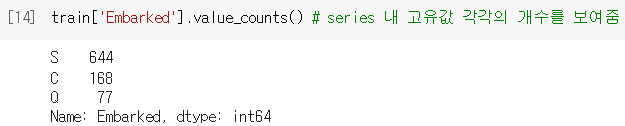
.unique()로 (고유값별 개수 없이) 고유값 종류만 확인할 수도 있음.

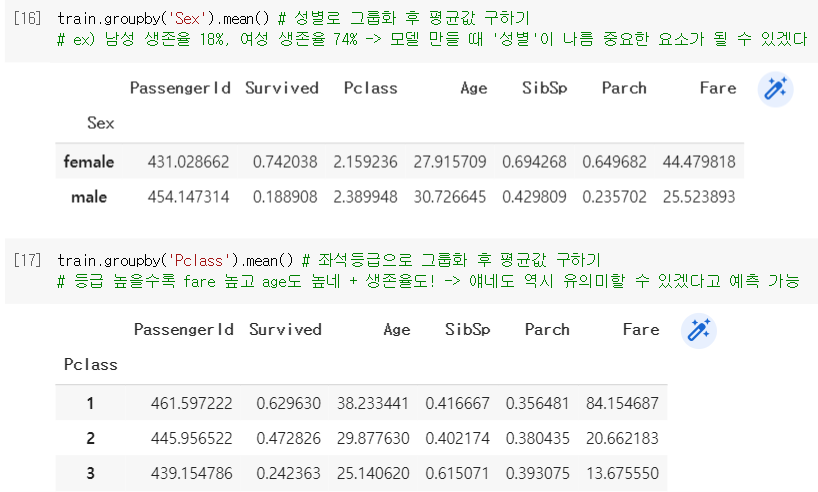
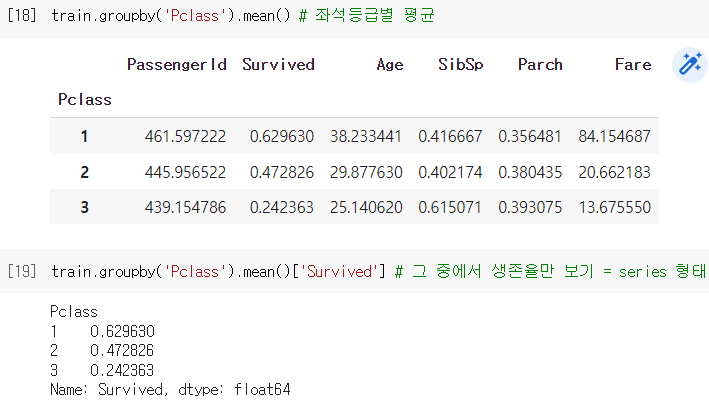
.groupby()로 원하는 그룹별 통계량을 구해볼 수 있음.
❗특정 변수들 간의 상관성이나 데이터가 가진 경향성을 어느정도 파악하게 해줌.
시각화를 통한 탐색
시각화를 통해 데이터를 좀 더 다각도로 살펴보자.
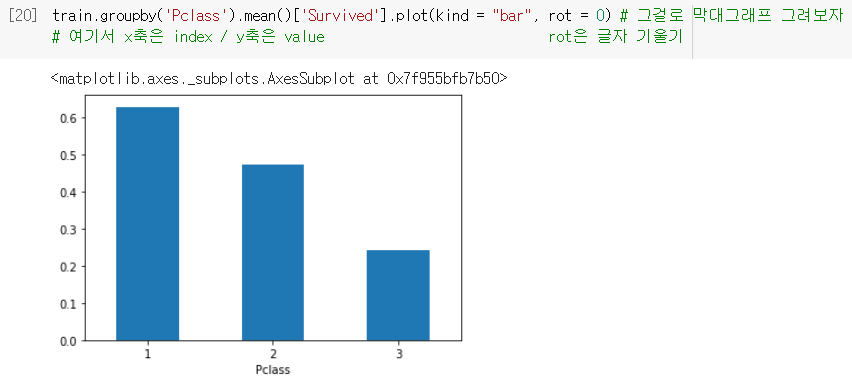
막대그래프
- 주로
groupby의 결과물을 보여줄 때 좋음 (ex. 좌석 등급별로 생존율이 어떠한가)
- Series에
.plot(kind = "bar")을 붙이면 막대그래프를 그려줌. (DataFrame 말고)
↪ x축에는 index, y축에는 value가 들어감!
히스토그램
- 구간별로 속한 샘플(row)의 개수를 보여줄 때 사용함. (수치형 자료만 가능!!)
- Series에
.plot(kind = 'hist')을 붙이면 막대그래프를 그려줌.
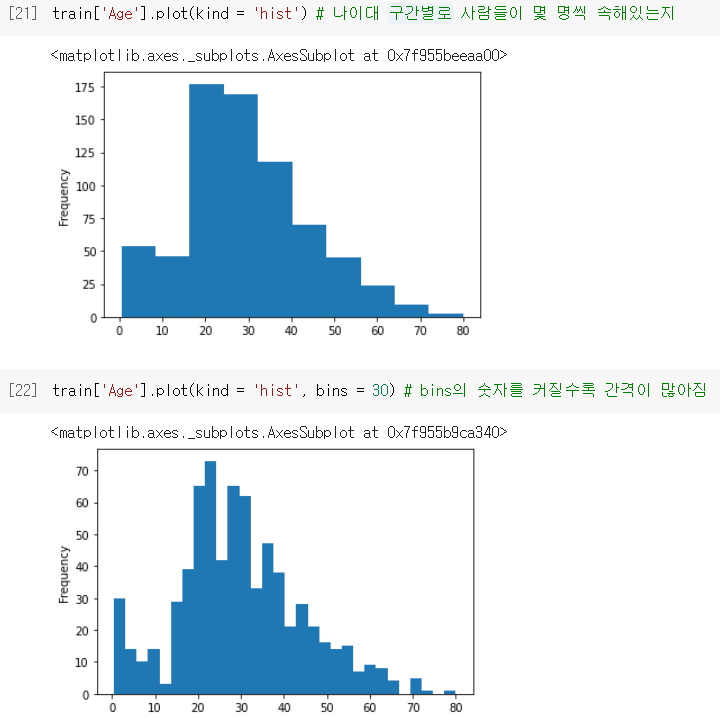
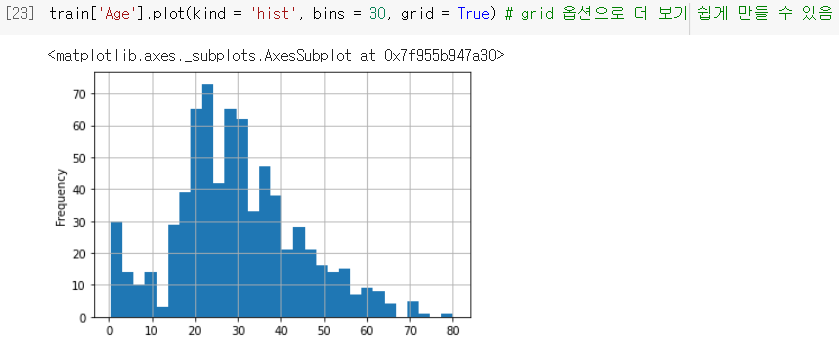
bins,grid등의 매개변수로 세부 설정 가능함.
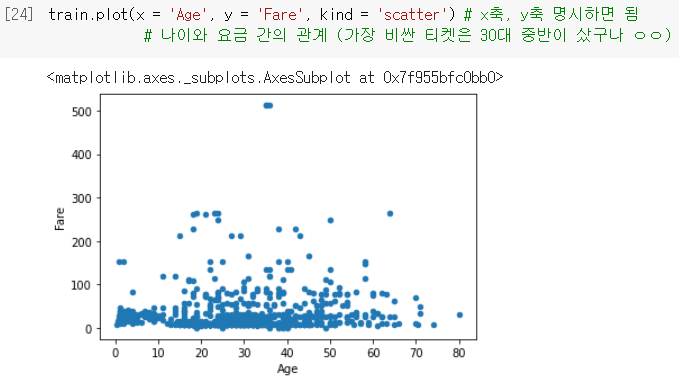
산점도
- 두 변수간의 관계를 보여줄 때 사용함. (🆚위 두 개는 다 변수 1개였음)
- DataFrame에
.plot(x, y, kind = 'scatter')을 붙이면 그려줌.
3. 데이터 전처리
데이터를 살펴봤으니, 이제 지저분한 부분을 깔끔하게 다듬어주자.
결측치 처리
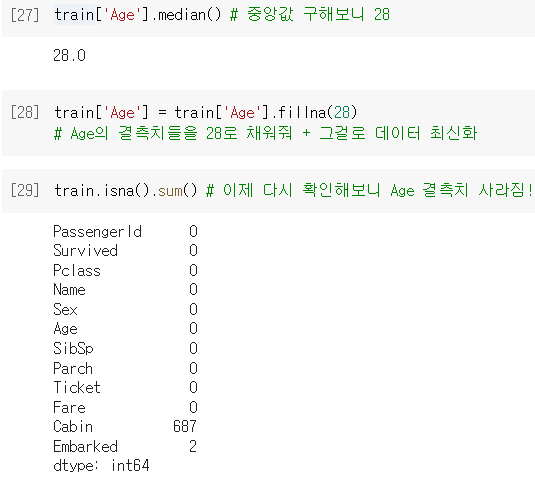
.isna()로 결측치 여부를 확인 가능 (결측이면 T, 아니면 F)

.sum()을 활용해, column별 결측치 개수를 파악할 수 있음!

- 결측치를 처리하는 가장 쉬운 방법은
.fillna()써서 하나의 값으로 모두 채워넣기!
↪ 주로 평균.mean()혹은 중앙값.median()을 사용함.
- 'Embarked'처럼 범주형 변수일 경우, 최빈값으로 대체할 수 있음.

데이터 타입 처리
- 어떤 예측모델들은 문자형(str) 데이터를 받으면 오류가 생김.
→ 문자형을 수치형으로 변환하기 위해서 해당 Series에.map()함수를 사용함.

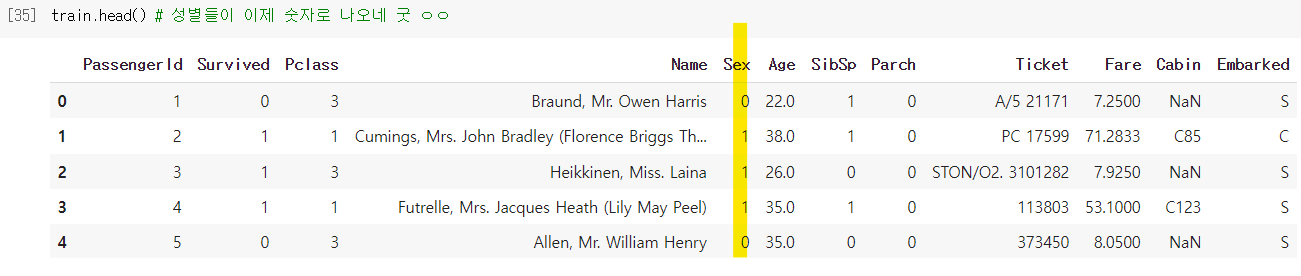
- 테스트 세트도 마찬가지로 해주는 거 잊지 말기!!!
4. 특성공학 및 모델구축
이제 데이터를 집어넣으면 생존여부를 예측해주는 모델을 만들어 보자.
- 원하는 컬럼을 인덱싱하여, 입력과 타깃(정답)을 설정해줌.

- 로지스틱회귀모델과 결정트리모델의 객체를 만들어줌.

5. 모델 학습 및 검증
모든 것이 준비되었다. 모델 객체에 우리가 가진 데이터를 학습시키고 그 성능을 보자.
모델 학습 & 새 데이터 예측
.fit()으로 각 모델을 학습시킴.

- 우리가 학습시킨 모델로, 테스트세트의 생존여부 예측 by
.predict()

.predict_proba()를 써서, 단순 여부가 아니라 확률로 출력할 수도 있음!

- 우리가 제출할 건 '생존확률'이니까 그것만 뽑음!

데이콘에 제출하여 검증
- 방금 구한 생존확률을, 제출할 답안지에 옮겨적음.

.to_csv()로 제출할 데이터를 파일로 내보냄(저장함).

- 💻content 폴더에 저장된 파일을 로컬 pc로 다운받기 → 데이콘 로그인 → 교육 → 타이타닉 → 제출 → 성능(정확도) 확인
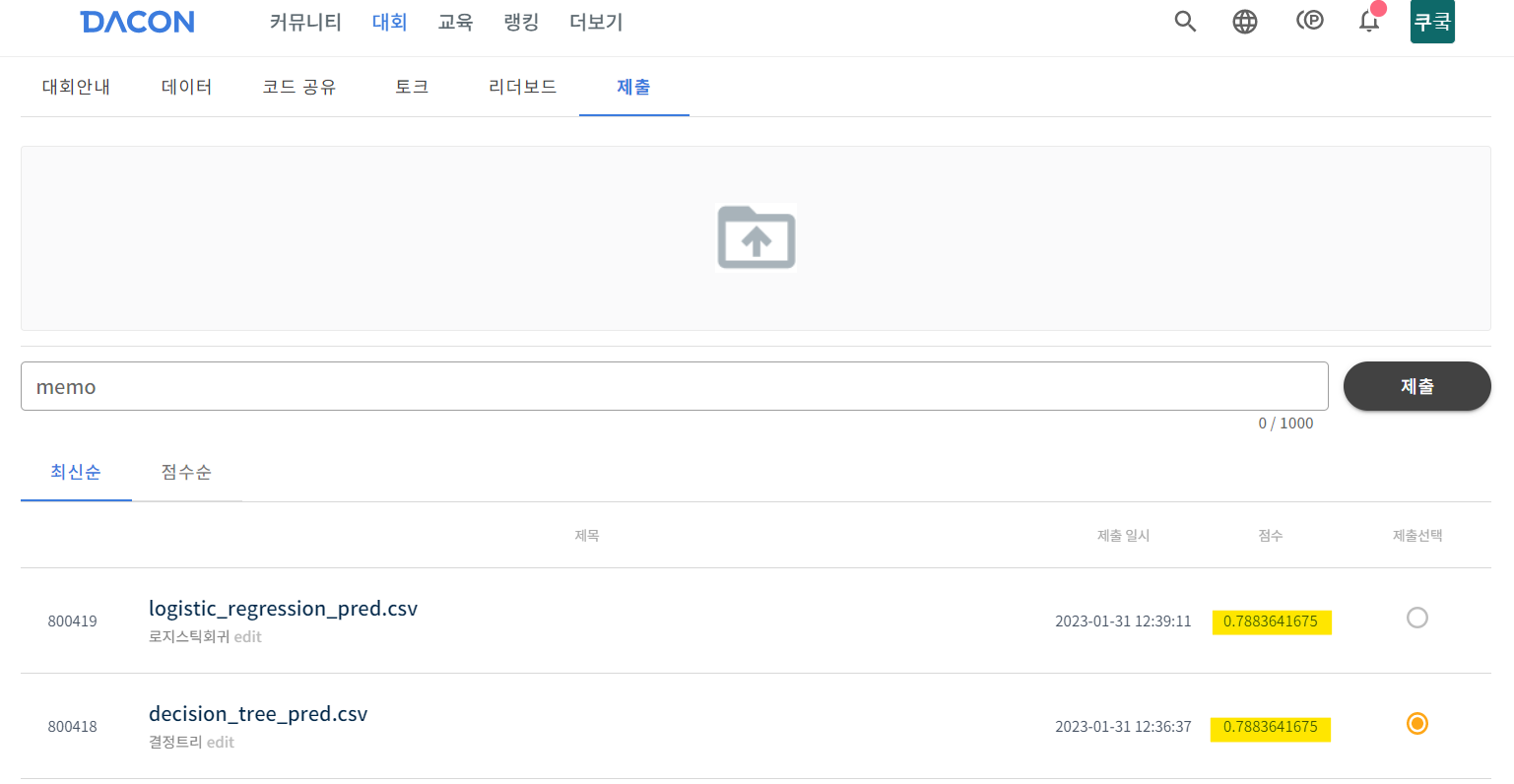
6. 결과 및 결론 도출
- 로지스틱 모델과 결정트리 모델 둘 다 0.78 정도의 정확도가 나왔네!
입력데이터에 다른 변수들도 추가해서 성능을 더 높여봐야겠군!
➕ 또 다른 데이터 전처리 과정

생각은 그만