
Intro.
김 팀장🗣️ "직원이 물고기 종류 구분을 못 하네... '무게'와 '길이' 데이터를 바탕으로, 도미와 빙어를 구분하는 모델을 만들어줘!"
1. 데이터 준비
도미 데이터 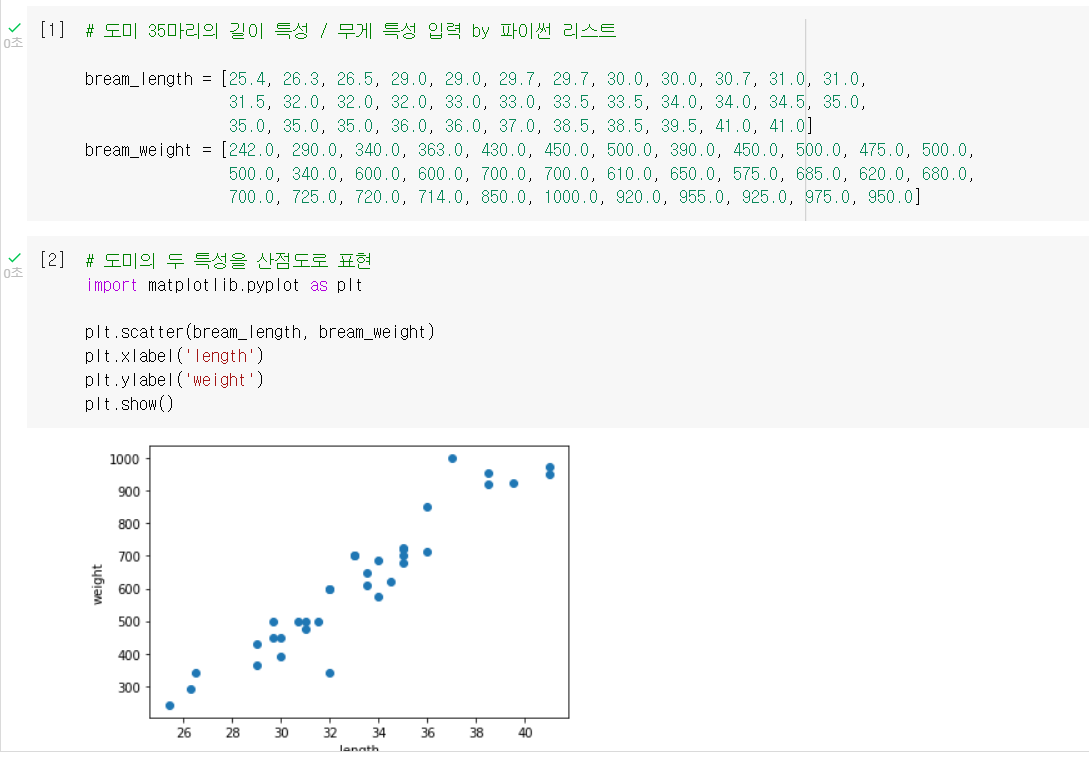
빙어 데이터 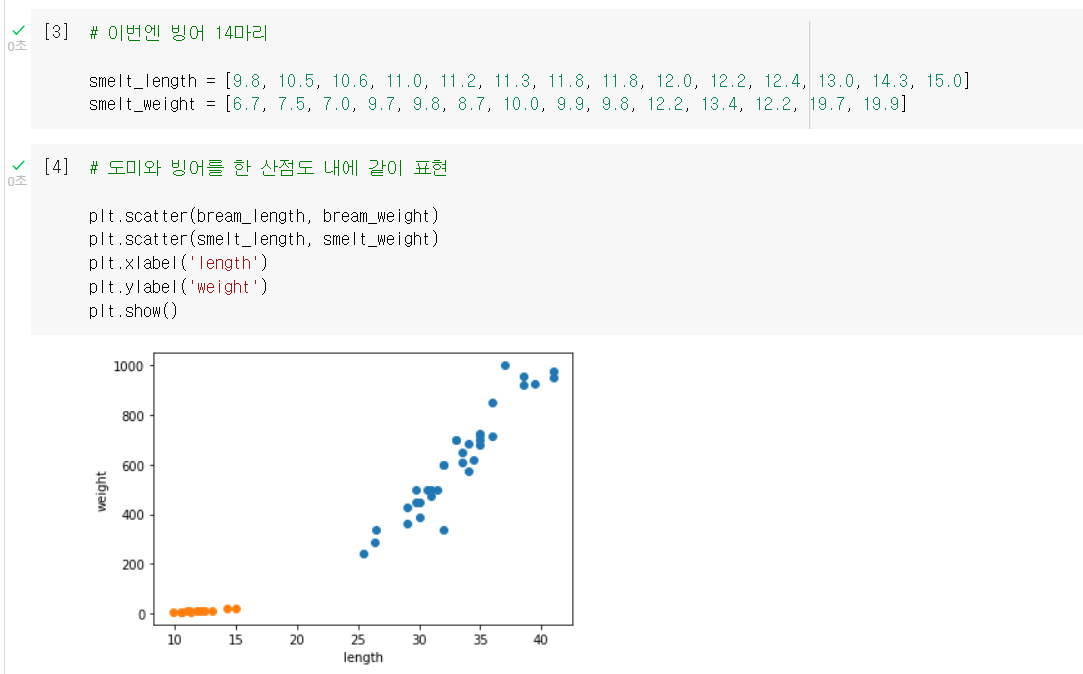
사이킷런에 맞게 데이터 구성 다듬기
❗사이킷런이 기대하는 데이터 형태 = 리스트 속 리스트 (2차원 리스트)
zip(): 전달받은 리스트에서 원소를 하나씩 꺼내주는 함수

정답 데이터 설정
- 입력 데이터는 위에서 설정한 도미와 빙어.
- 뭐가 정답인지는 알아야 알고리즘도 학습이란 걸 할 수 있겠죠! (정답=1)

2. 머신러닝 프로그램 개발
알고리즘 준비
KNeighborsClassifier: '사이킷런' 패키지의 'k-최근접 이웃 알고리즘'으로, 주위의 다른 데이터를 보고 다수를 차지하는 것으로 새 데이터를 판단함

모델 훈련 및 평가
.fit(): 주어진 데이터로 알고리즘을 훈련시키는 함수..score(): 훈련한 모델을 평가하는 함수. 0.0~1.0의 값을 반환함.

도미와 빙어 구분할 수 있는 머신러닝 모델 완성!
3. 새로운 데이터에 적용 가능
.predict(): 새로운 데이터의 정답을 예측하는 함수⭐이 때, 전달값은 역시 [[리스트 속 리스트]]여야 함!! (sklearn 패키지니까)

➕플러스 알파
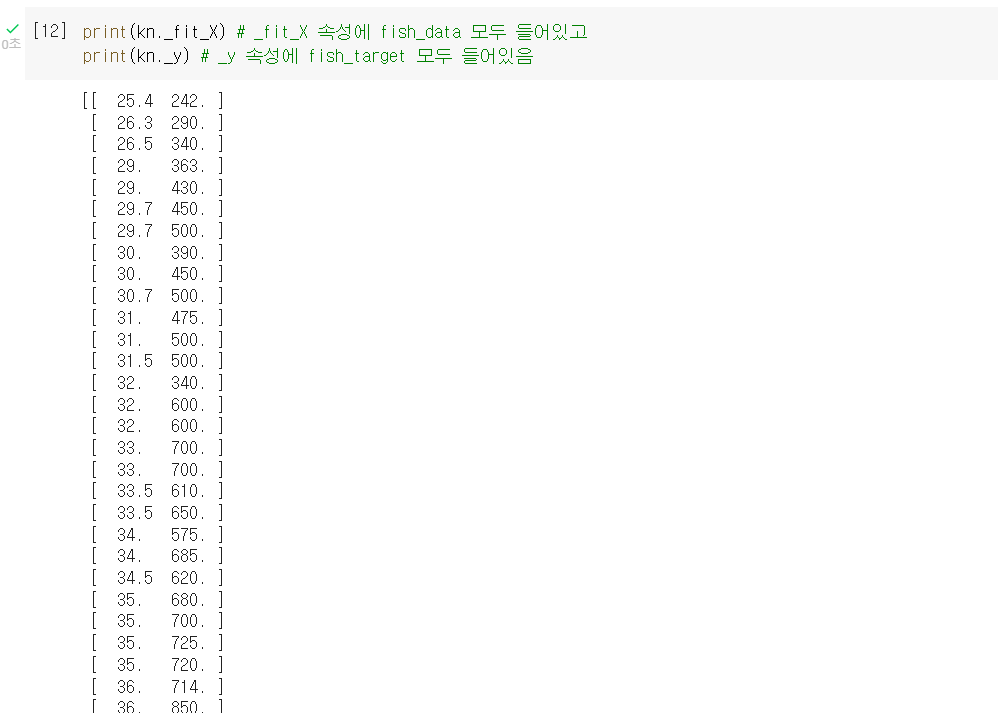
➊ 'k-최근접 이웃 알고리즘'은 사실상 훈련이라기보다, 데이터를 그대로 쌓아두고 판단만 하는 셈이다.
._fit_X,._y매개변수로 클래스의 속성들 보면, 데이터가 다 그대로 있음

➋ 가까운 몇 개의 데이터를 참고할 것인지 임의로 설정할 수 있다.
n_neighbors: 최근접 이웃의 개수를 설정하는 매개변수 (기본값=5)

🤔 Hmmmm...
51p. '세로로 늘어뜨린 2차원 리스트가 필요'하댔는데 왜 print해보면 가로로(1행으로) 쭉 나오는 거죠?
👨🏻🏫51p와 52p 배열은 동일한 내용입니다. 다만 보기 편하게 정렬이 된 차이가 있을 뿐이에요. 🆗 (리스트 속 리스트이기만 하면 되는듯..!)
54p.
.fit()의 구체적인 내부 과정은 알 수 없는 건가요? 타깃에는 그저 정답이 몇 개인지 개수만 알려줬을 뿐인데 어떻게...👨🏻🏫fit 메서드는 모델을 훈련하는 역할을 합니다. 알고리즘마다 모델을 훈련하는 방법은 매우 다르며 이를 알고 싶다면 사이킷런 소스코드를 직접 보시는 것이 제일 좋은 방법입니다. 🆗 (fit은 그냥 모델마다 내부에서 정해놓은 작동원리가 있는 듯?)
56p. 속성 확인할 때, 왜 y는
_fit_Y로 하지 않는 거죠..?👨🏻🏫그건 개발자 마음이랍니다 ...^^ 🆗
🤓 To wrap up...
도미와 빙어를 알아서 구분하는 모델이 필요 → 도미 데이터와 빙어 데이터를 직접 리스트로 만들어서 준비 → 간단한 k-최근접 이웃 알고리즘을 훈련시켜 봄 → 준비한 데이터에 대해서 다 맞춤! (정확도 100%)
도미와 빙어를 구분할 수 있는 간단한 머신러닝 프로그램을 만들어보았다.
'k-최근접 이웃' 모델의 작동원리와 실제 사용법을 익힐 수 있었다. 교수님 말씀대로 아직 규칙을 찾아낸 느낌은 아니라서, 다른 알고리즘 기법들을 얼른 배워보고 싶다.
