[혼공머신] 7-3. 신경망 모델 훈련
혼공머신

Intro.
지금까지 인공신경망+심층신경망을 배우고, 이를 케라스 API로 직접 만들어봤다.
이번 시간엔 이렇게 모델을 훈련하면서 필요한 추가 도구들을 배워보자!
1. 신경망 모델 돌아보기
모델 만드는 함수 제작
- 신경망 모델 만드는 과정을 함수화해서 편하게 사용하려고 함.
- 이제는 함수에다가 쌓고 싶은 층만 전달해주면 알아서 신경망 모델 만들어 줌!

fit의 결과값 시각화
- 저번 시간에 심층신경망 훈련했던 코드를 다시 보면, 아래와 같은 메시지가 있음

- 사실 keras의
.fit()메소드는 History 객체를 반환함.
↪ 그 안에는 훈련측정값이 담긴 history 딕셔너리가 들어있음! ('accuracy'는 우리가 따로 metrics 넣어줬기 때문에 있는 거임 ㅇㅇ)

- 이 측정값(결과값)들을 그래프로 그려서 확인해봅시다!
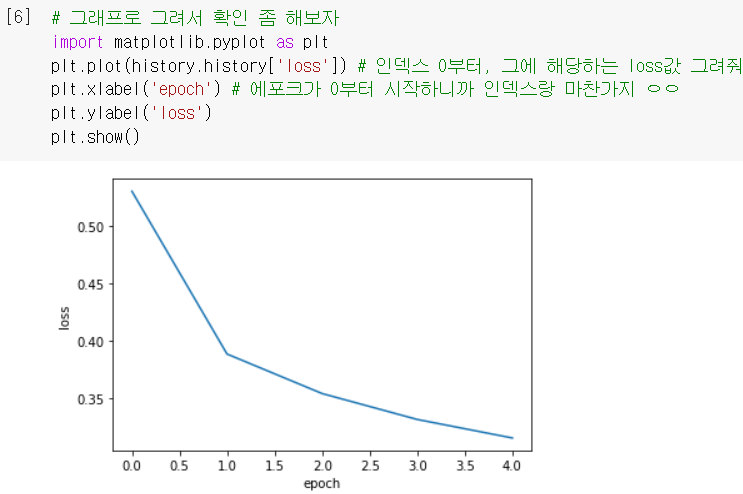
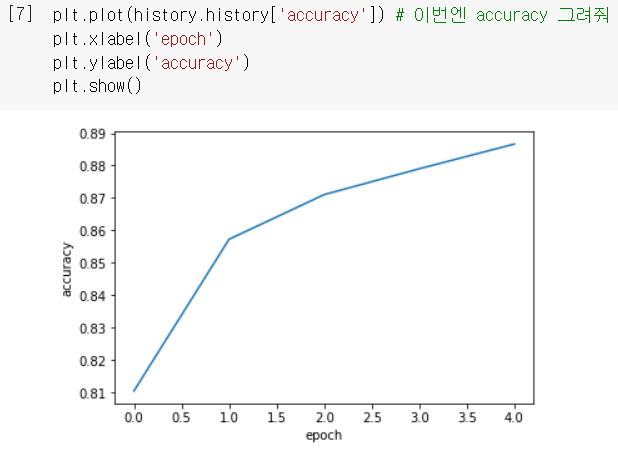
- 확실히 에포크 늘어날수록 loss 감소하고 accuracy 늘어나는 걸 확인 가능!
에포크 늘리기
- 에포크를 더 늘려 볼수록 손실이 더더욱 감소하는 것을 확인할 수 있음.
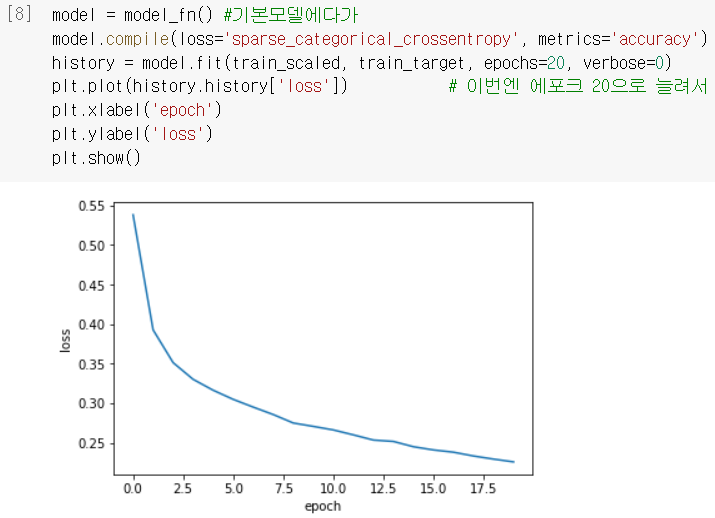
그런데 잠시, 이렇게 훈련세트에 잘 맞게 되면 짚고 넘어갈 게 있을 텐데...?^^
검증손실과 과대적합
- 210p <최적의 에포크 찾기>에서 했듯이, 검증세트의 손실도 확인해야 함.
validation_data: fit의 매개변수로, 검증세트의 결과도 반환하도록 설정 가능함!

- 그렇게 구한 검증세트의 손실도 함께 그래프로 그려보니 ...
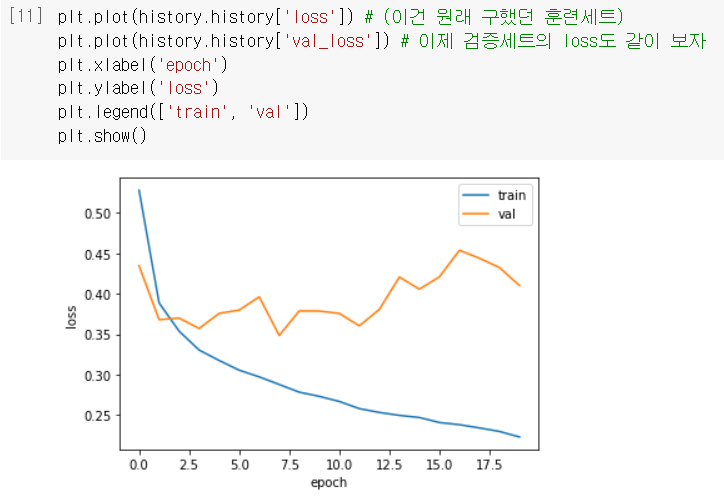 OMG,, 혹시나가 역시나였어,, 훈련세트에만 너무 잘 맞는 과대적합이구나ㅠ
OMG,, 혹시나가 역시나였어,, 훈련세트에만 너무 잘 맞는 과대적합이구나ㅠ
(➕옵티마이저 다른 걸로 바꿔서 완화시키기도 하지만, 지금은 신경망의 대표적인 규제방법을 알아보겠음)
2. 드롭아웃
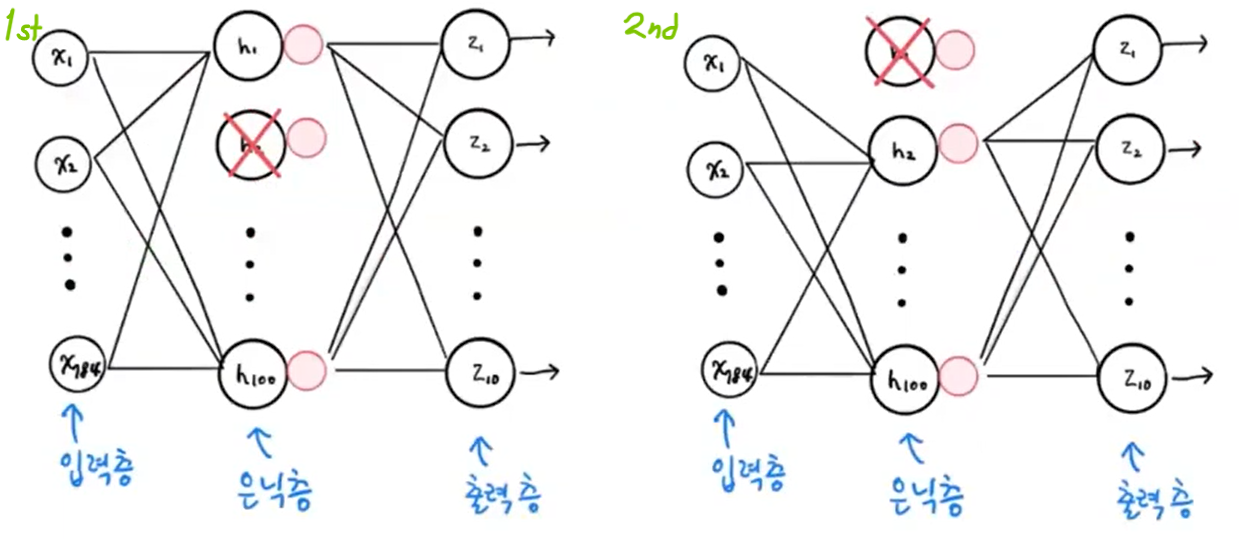
- 신경망 모델에만 있는 규제 방법으로, 딥러닝의 아버지 Geoffrey Hinton이 소개함.
- 층에 있는 유닛을 다 훈련하지 않고 일부를 랜덤하게 OFF해서 훈련 성능을 낮춤.
ex) 1st 샘플에선 두번째 유닛 계산 안 하고, 2nd 샘플에선 첫번째 유닛 계산 안 하고,•••
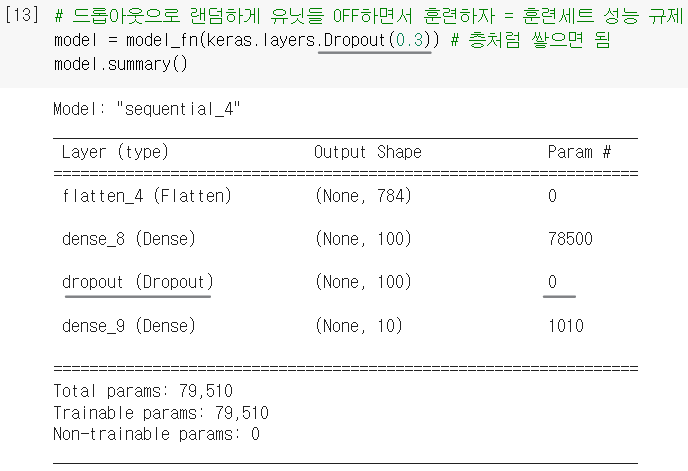
Dropout(): 드롭아웃 기능을 제공하는 클래스. 얼마나 drop할지 비율을 지정해야 함.
(*마치 케라스 층처럼 사용되지만, 학습되는 모델 파라미터는 없음)
- 드롭아웃 처리한 모델의 검증손실을 출력해보니, 확실히 과대적합 완화됨!
(🤓따로 Dropout 층 안 빼줘도 알아서 평가&예측 시에는 드롭아웃 적용 안 함 ~)
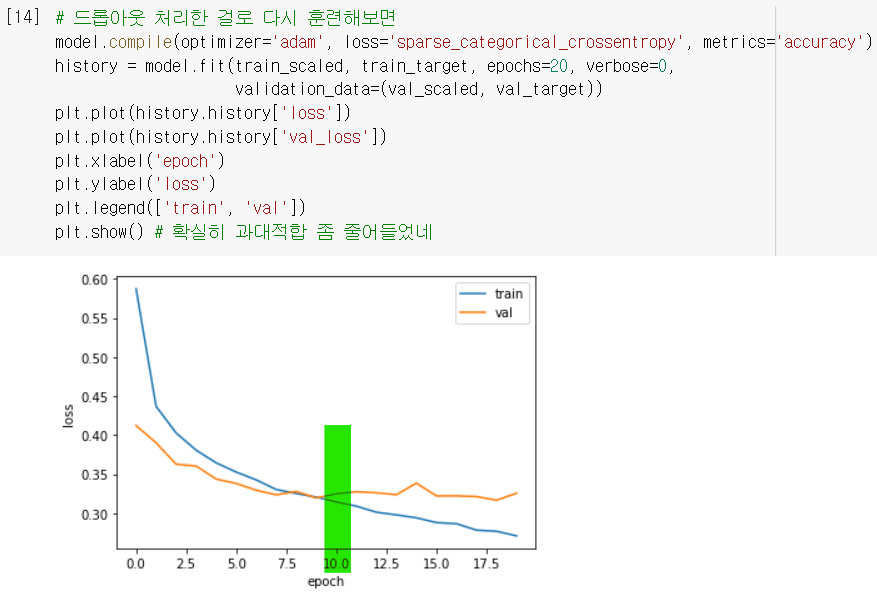
최적의 에포크는 10 정도로 보이니까,epochs=10으로 설정하고 다시 훈련해야겠군..
3. 모델 저장 & 복원
- 일단 최적의 에포크 10으로 설정한 모델을 완성함.

일을 하다보면, 만든 모델을 잠깐 저장해뒀다가 다음에 다시 훈련한다든가, 저장해두고 다른 사람이 그걸 불러와서 쓴다든가 할 일이 생깁니다. 이런 저장과 복원 기능은 웬만한 라이브러리에서 다 제공하고 있지요.
모델 저장
.save_weights(): 훈련된 모델의 가중치를 저장하는 메소드.save(): 훈련된 모델의 구조와 가중치를 통째로 저장하는 메소드

모델 복원
.load_weights(): 이전에 저장했던 모델의 가중치를 적재하는(불러오는) 메소드
(얘는 모델 구조가 정확히 같아야만 적재할 수 있음!).load_model(): 이전에 저장했던 모델 전체를 불러오는 메소드

검증세트의 정확도 계산
복원_1 모델
👨🏻🏫 물론
evaluate()써도 되지만, 그렇게 계산하려면 복원한 모델에 또 다시compile()을 실행해야 합니다. 여기에선 그냥 새로운 데이터에 대해 정확도만 계산하면 되는 상황이라고 가정합시다.
< 계산 방법 : 예측클래스 직접 구하고, 그거랑 타깃이랑 비교해서 맞춘 비율로 구할 것임. >
.predict(): 샘플마다 각 클래스일 확률을 반환해줌. (사이킷런 predict_proba처럼)
🆚 사이킷런(p.181)에서는 예측클래스가 뭔지 바로 갖다줬었는데, 여기선 모든 클래스별 확률을 주니까, 그 중에 제일 높은 걸 다시 선택하는 과정을 수동으로 해줘야 함...

.argmax(): predict가 출력한 확률들 중에 가장 큰 값을 뽑기 위해 넘파이 활용함.
axis=-1: 배열의 마지막 차원(여기서는 axis=1)을 따라 argmax를 수행함.- 그렇게 뽑은 최댓값의 인덱스
val_labels와val_target을 비교해서, 일치하는 비율이 곧 검증세트의 정확도가 됨!
복원_2 모델
👨🏻🏫 이 경우는 모델의 구조와 옵티마이저까지 모두 그대로 복원했기 때문에 바로
evaluate()를 사용할 수 있습니다!
.load_model(): 이전에 저장했던 모델 전체를 불러오는 메소드

자, 그런데 #2의 끝자락으로 다시 가서 생각해보면 •••
매번 이렇게 수동으로 다시 최적의 에포크 설정하고,, 다시 모델 훈련하고,, 그래야만 하나?
4. 콜백
- 위와 같은 번거로움을 해결할 수 있는 도구가 바로 콜백(Callback)이다!
- 훈련 과정 중간에 특정 작업을 수행하게 해주는 객체로,
keras.callbacks패키지 아래에 다양한 클래스들이 있다.
➡️ 콜백 객체를 만들어두고,fit()할 때callbacks매개변수로 전달하면 된다.
ModelCheckpoint 콜백
ModelCheckpoint(): 가장 자주 사용되는 콜백으로, 에포크마다 모델을 저장해줌.
save_best_only=True: 손실이 가장 낮은 모델만 저장하도록 하는 설정.

- 이제 자동으로 저장된 최적의 모델을 load만 해서 쓰면 되니까 편리함^^

EarlyStopping 콜백
- 자, 최적의 에포크 찾는 건 오케이. 그런데, 그 최적의 모델 찾을 때 에포크를 무작정 높게 설정해놓고 찾으면, 불필요하게 오랫동안 훈련을 계속함.
EarlyStopping(): 과대적합이 시작되면 훈련을 알아서 조기종료 해주는 콜백.
patience: 검증세트 성능이 좋아지지 않더라도 참고 기다릴 에포크 횟수 설정.
restore_best_weights=True: 훈련동안 가장 손실 낮았던 최적 가중치로 돌리는 설정.

- 이러면 이제
fit()에서epochs를 마음놓고 크게 설정해도 괜찮음^^ .stopped_epoch: 몇 번째 에포크에서 조기종료 했는지 저장되어 있는 속성.
→patience설정했던 것과 같이 생각해보면 최상의 에포크가 언제인지 나옴!
ex) 2번 참았는데, 11번째 에포크에서 끝났단 건 9번째 에포크가 최상의 모델이란 거네~
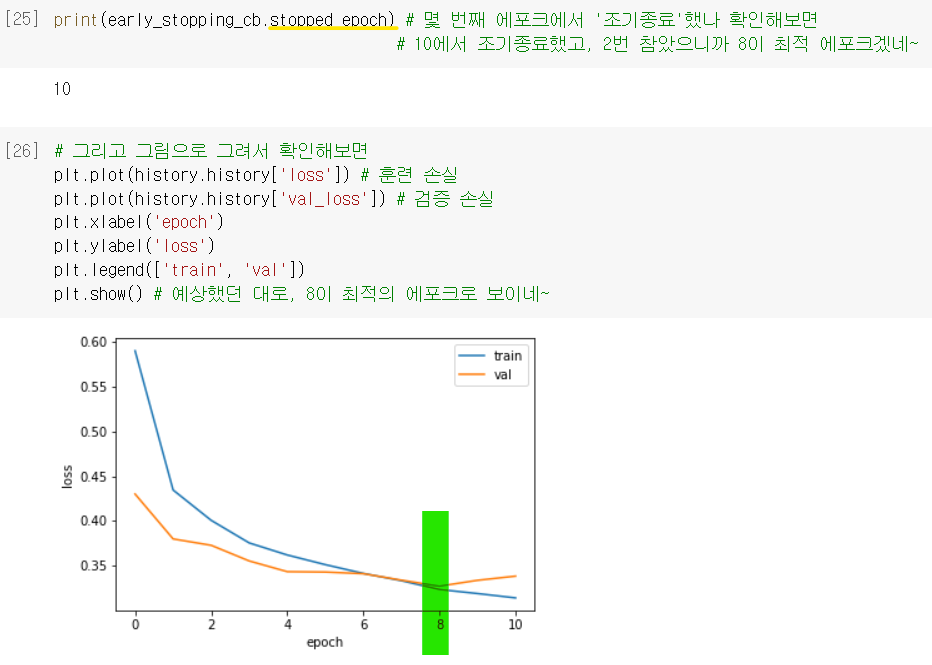
최종 모델
- ModelCheckpoint 콜백이랑 EarlyStopping 콜백을 함께 사용했더니, 자동으로 최상의 모델을 얻을 수 있게 되었음 ~!
→ 이걸 이번 시간의 최종 모델로 하고, 검증세트에 대한 성능을 확인!

➕플러스 알파
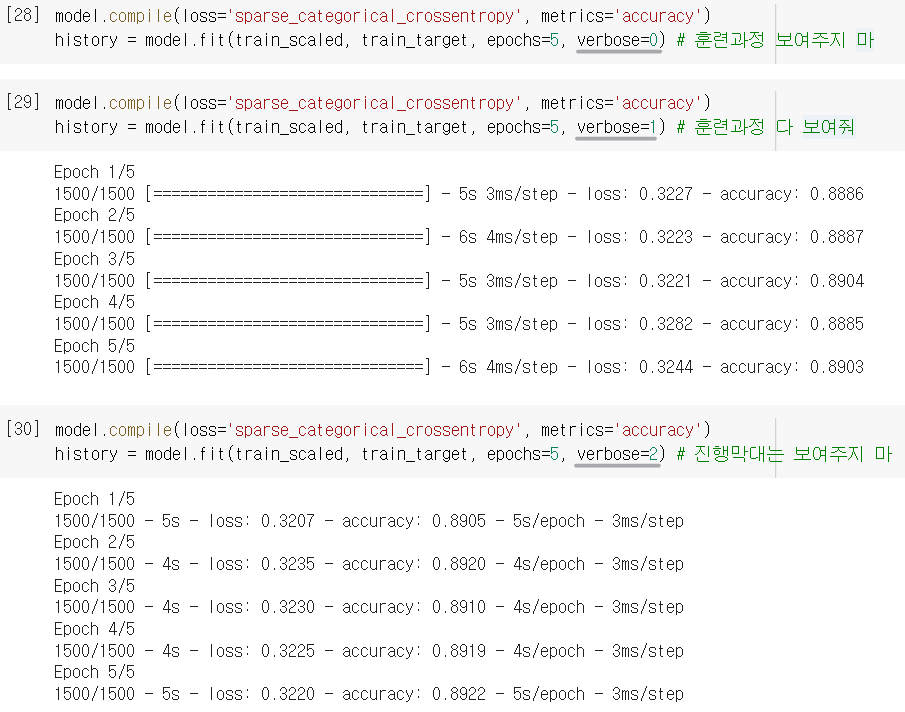
➊ verbose 매개변수
verbose: fit()에서 쓰는 매개변수로, 훈련과정의 출력을 조절해줌.- 1 : 진행 막대와 측정값 출력 (이게 기본값)
- 2 : 진행막대 빼고 출력
- 0 : 훈련과정 아예 출력하지 않음
➋ 옵티마이저로 과대적합 줄이기
- 과대적합 문제가 생기면, 옵티마이저를 적절히 변경해서 완화시키기도 한다.
ex) 적응적 학습률을 사용하는 Adam은 에포크 진행되면서 학습률 조정하니까, 기본 옵티마이저인 RMSprop보다 이 데이터셋에 더 잘 맞는군..
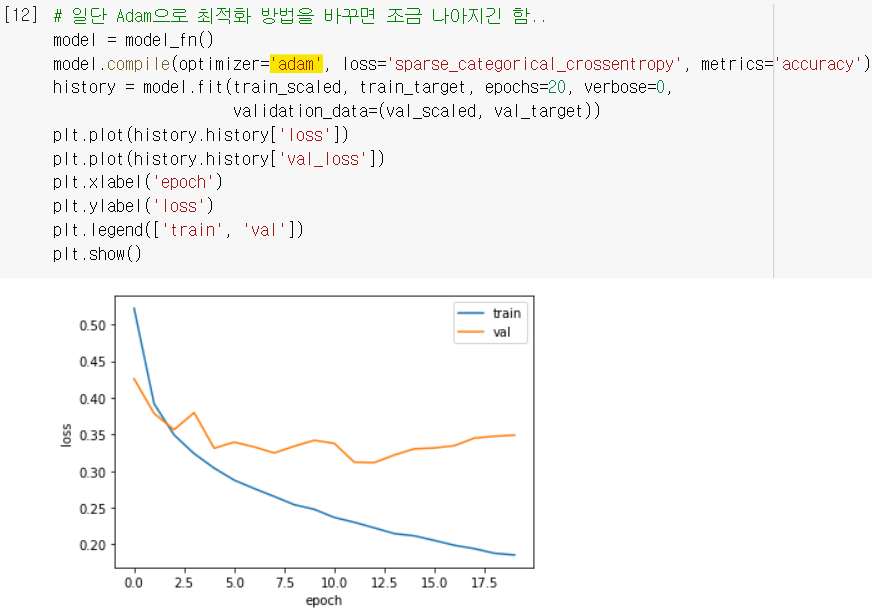
- 여기서 학습률까지 조정하면 더 나은 손실곡선이 나올 수도 있습니다.. 해보시길..!
🤔 Hmmmm...
405p.
predict_classes()메소드도 필요성이 있어보이는데 왜 사라지는 거죠..? 개발하신 분의 깊은 뜻이 있겠죠..?^^
🤓 To wrap up...
이번엔 신경망 모델을 더 잘 만들 수 있도록 도와주는 도구들을 배웠다. 과대/과소적합 문제를 잊고 있었는데,, 신경망도 역시 피해갈 수 없는 문제였구나,,! 사이킷런 때와는 또 다른 방식으로 규제를 할 수 있다는 게 신선했다. 정말 무궁무진한 ML/DL의 세계.. 이 뒤에는 더 자세한 딥러닝 모델들이 나올텐데 기대반 걱정반이😂 다른 것도 할 게 많지만 <혼공머신> 만큼 입문하기 좋은 게 없을테니 시간날 때 강의라도 들어두자..!
fit의 반환값을 사용해서 훈련세트 & 검증세트의 손실을 그래프로 그려봄 → 과대적합 발견 → 신경망의 대표적인 규제방법인 드롭아웃으로 완화시켜봄! → 만든 모델(가중치 or 모델 전체)을 저장하고 복원하는 기능도 새롭게 배움 → 근데 생각해보니 매번 최적의 에포크로 다시 모델 만들기 귀찮음 ㅠ → 콜백 기능을 사용하니 그 과정을 자동화해서 편리하게 최상의 모델을 만들 수 있게 됨! = ModelCheckpoint로 최상의 모델만 저장하고, EarlyStopping으로 불필요하게 훈련 길어지는 것도 막음
➕ 드디어... (?) 혼공학습단 6주 과정의 모든 미션이 끝났다!!! 시원섭섭한 이 소감은 회고록에 끄적여둬야지 ,,✍🏻
