.png)
Array
배열로 변환
from()
이터러블 오브젝트 혹은 Array-like 오브젝트를 Array 오브젝트로 변환하는 함수입니다.

-
Array-like 오브젝트 변환
const ArrayLikeObj = {0: "test1", 1:"test2", length:2} const result1 = Array.from(ArrayLikeObj); console.log(result1); // ["test1", "test2"] -
이터러블 오브젝트 변환
/* <li class="sports">축구</li> <li class="sports">농구</li> */ const nodes = document.querySelectorAll(".sports"); const show = (node) => console.log(node.textContent); Array.from(nodes).forEach(show); // 축구 // 농구 -
두 번째 파라미터에 함수를 작성
const like = {0:"zero", 1:"one", length:2}; const change = (value) => value+"변경적용"; console.log(Array.from(like, change)); // [zero변경적용, one변경적용]⇒ Array 오브젝트에 추가 될 각각의 요소가 추가되기 전 두 번째 파라미터로 받은 로직을 수행 후 값을 배열로 반환합니다.
-
세 번째 파라미터에 this로 참조할 오브젝트 작성
const like = {0:"zero", 1:"one", length:2}; const change = function(value) { return value+"변경적용 " + this.book; }; const obj = {book: "책"}; console.log(Array.from(like, change, obj)); // [zero변경적용 책, one변경적용 책]
of()
파라미터 값을 배열로 변환하여 반환하는 함수로 파라미터에 변환 대상 값을 작성합니다. 콤마로 구분해 다수 작성도 가능합니다.

const result = Array.of(1, 2, 3); console.log(result); console.log(Array.of()); // [1, 2, 3] // []
배열 엘리먼트 복사
copyWithin()
오브젝트 내의 범위 값을 복사하여 설정하는 함수입니다.
두 번째 파라미터 인덱스부터 시작하는 배열을 복사하여 첫 번째 파라미터 인덱스부터 순서대로 설정합니다. 원본의 값을 대체(변경)합니다.
세 번째 파라미터가 없다면 2번째 파라미터 인덱스부터 끝까지를 의미하고, 파라미터가 있다면 해당 인덱스 앞까지 복사합니다.
const list = ["A","B","C","D","E"]; const copy = list.copyWithin(1, 3); console.log(list); console.log(copy); // [A,D,E,D,E] // [A,D,E,D,E]
-
세 번째 인덱스를 작성했을 경우
const list = ["A","B","C","D","E"]; const copy = list.copyWithin(0, 2, 4); console.log(list); console.log(copy); // [C,D,C,D,E] // [C,D,C,D,E]⇒ 2번째부터 4번째까지([C,D])를 0번째 인덱스부터 대체한다는 의미로 아래 이미지와 같이 대체됩니다.
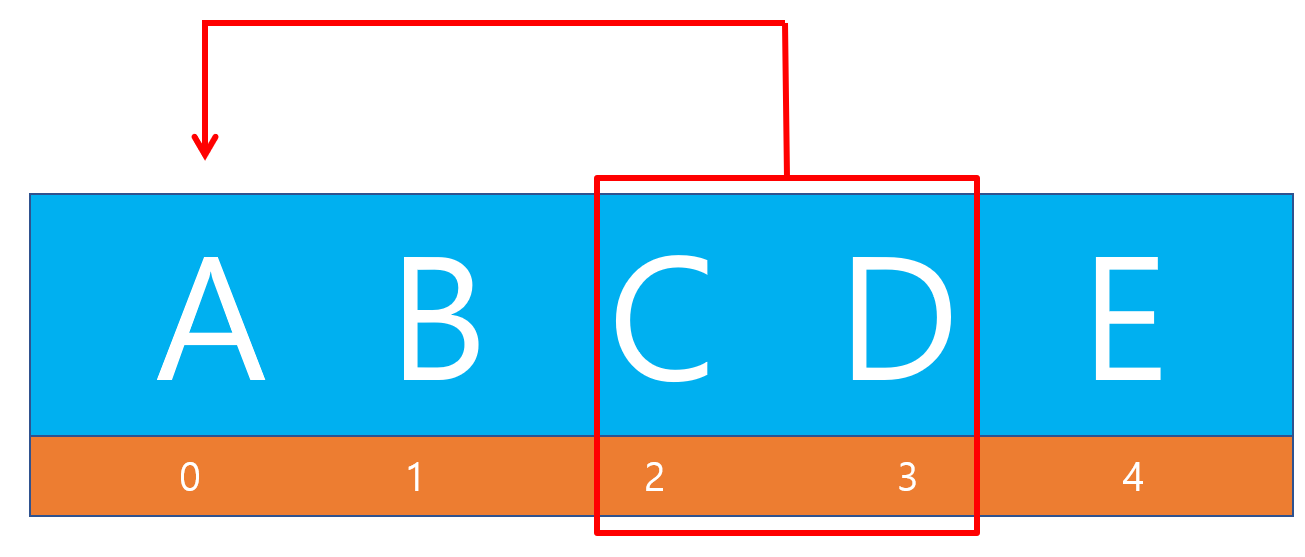
-
첫 번째 인덱스만 작성했을 경우
const list2 = ["A","B","C","D","E"]; const copy2 = list2.copyWithin(2); console.log(list2); console.log(copy2); // [A,B,A,B,C] // [A,B,A,B,C]⇒ 배열 전체를 복사한다는 의미가되어 1번째 파라미터 인덱스부터 대체를 한다는 의미가 됩니다. 이때 복사할 엘리먼트 수가 대체할 엘리먼트 수보다 많을 경우 매치되는 인덱스만 값을 대체하고 남는 것 ([D,E])는 대체하지 않습니다.
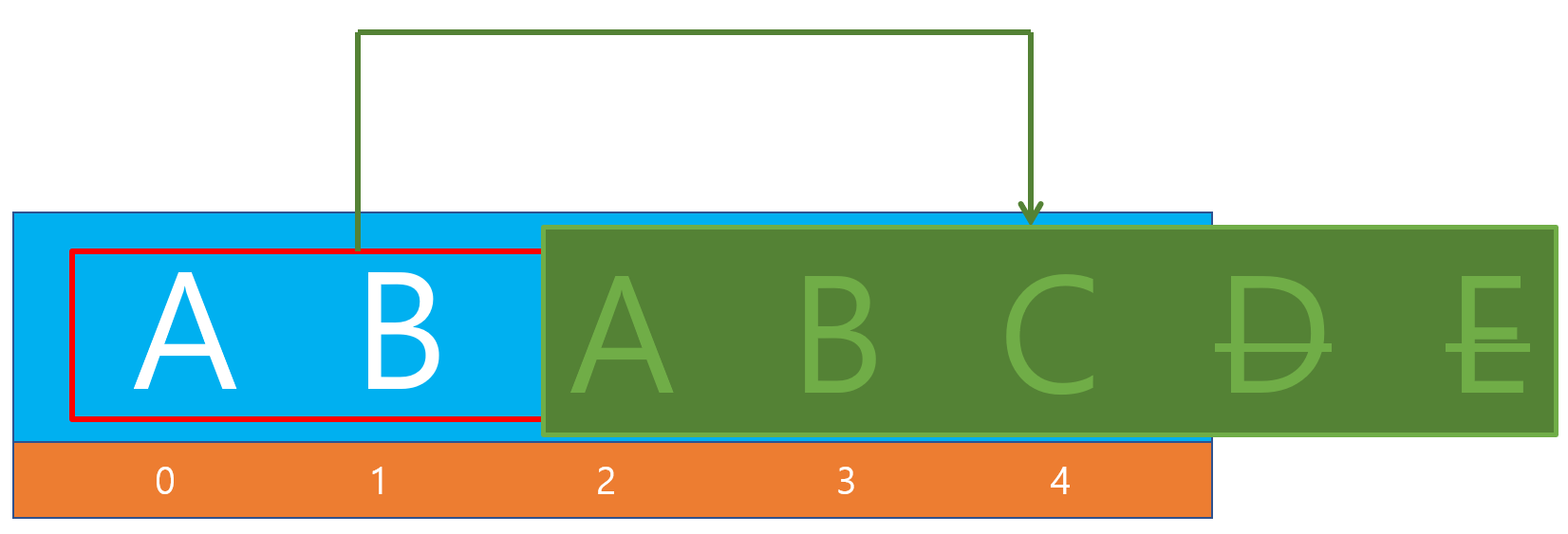
copyWithin() 함수는 얕은 복사(shallow copy)로써 같은 배열 안에서 이동하는 개념입니다. 새로운 내용을 만들어 할당하는 것이 아닌 현재의 메모리 주소를 복사해 참조를 넣어주는 개념입니다. 만약, 값이 연동되지 않게 하기위해서는 깊은 복사(Deep Copy)를 해야 합니다.
또한, 배열의 엘리먼트 수는 더 늘어나거 나 줄어들지 않으며, 동작 시 배열 안에서 엘리먼트 이동은 좌측에서 우측으로 이동하며 처리속도가 빠르다는 특징이 있습니다.
Generic
Javascript spec을 살펴보면 'copyWithin function is intentionally generic'이라는 문구가 있습니다. copyWithin 함수는 제네릭 함수로, this 값이 Array 오브젝트일 필요는 없다는 뜻입니다.
이는 다른 오브젝트에서도 쓸 수 있다는 의미가 됩니다. Array-like 오브젝트이거나 이터러블 오브젝트에서는 copyWithin 함수가 동작하도록 개발을 해야한다는 의미입니다.
const like = {0: 10, 1:20, 2:30, length: 3}; console.log(Array.prototype.copyWithin.call(like, 1, 0)); // {0: 10, 1: 10, 2: 20, length: 3}
- call()에서 this에 바인딩 될 오브젝트로 like를 작성했는데 이는 Array-like 오브젝트이며 제네릭 함수인 copyWithin에서는 동작할 수 있어야 합니다.
- 결과값은 배열 형태가 아닌 대상 오브젝트 형태로 반환됩니다.
- generic 의미
copyWithin()는 Array.prototype에 연결된 메소드입니다. Array 오브젝트가 기본 처리 대상이지만, Array-like, 이터러블 오브젝트를 처리할 수 있다는 것을 의미합니다.
같은 값, 인덱스 검색
find()

개발을 하다보면 많은 배열정보들을 마주하게되고 그 중 원하는 값을 찾아야 하는 경우가 있습니다. 예를 들어 학생들의 성적정보가 배열로 담겨져 있다고 할 때, 여기서 특정 이름의 학생을 찾으려 합니다. 보통은 배열 내부를 순회하며 이름을 비교해 찾는 방법이 있습니다.
이러한 방법을 정리해놓은 메소드가 find()입니다. 배열의 엘리먼트를 하나씩 읽어가며 파라미터로 받은 콜백 함수를 호출하여 함수가 true를 반환할 경우 검색 완료로 판단해 메소드를 종료합니다. 이 때, 가장 마지막으로 비교한 엘리먼트 값을 반환합니다
const students = [ {name:"이한솔", eng:90, math:85}, {name:"김철수", eng:76, math:80}, {name:"김영희", eng:95, math:55} ]; // 반복 순회 비교 로직 function find(name, list) { for(const item of list) { if(item.name === name) { return item; } } return null; } console.log(find("김철수", students)); // {name:"김철수", eng:76, math:80} // find() 사용 const findConditionWithArrow = (value, index, all) => value.name === "김철수"; const result = students.find(findConditionWithArrow); console.log(result); // {name:"김철수", eng:76, math:80}
둘 다 같은 값을 반환합니다. 하지만, 로직 직접 구현은 반복순회에 대한 로직과 순회의 대상인 배열도 직접 넘겨줘야 하는 반면, find() 메소드는 조건검사로직(callback)만 만들어주면 되기에 한결 더 편하게 사용가능합니다.
또한. 세 번째 파라미터에 this로 참조할 오브젝트를 넣어주면 this를 통해 해당 오브젝트를 사용할 수 있습니다.
const students = [ {name:"이한솔", eng:90, math:85}, {name:"김철수", eng:76, math:80}, {name:"김영희", eng:95, math:55} ]; const findCondition= function(value, index, all) { return value.name === "김철수" && value.name === this.name; } const result = students.find(findCondition, {name: "김철수"}); console.log(result); // {name: "김철수", eng: 76, math: 80}
find()에서 this로 참조할 오브젝트({name: "김철수"})를 작성해주니 콜백 함수에서 this.name 프로퍼티를 찾으면 "김철수"를 참조합니다.
주의할 점은 콜백 함수는 선언식 함수로 표현을 해야한다는 것인데 그 이유는 Arrow Function으로 작성 시 this가 window를 참조하기 때문에 두 번째 파라미터로 참조한 오브젝트를 참조하지 못합니다.
findIndex()

findIndex() 메소드는 기존 find() 메소드와 동일한 파라미터를 전달받고 수행되는 로직도 동일합니다. 하지만 차이점은 find()에서는 콜백함수를 통해 매칭된 엘리먼트의 요소를 반환하는 반면, findIndex()는 매칭된 엘리먼트의 인덱스를 반환합니다.
const students = [ {name:"이한솔", eng:90, math:85}, {name:"김철수", eng:76, math:80}, {name:"김영희", eng:95, math:55} ]; const findConditionWithArrow = (value, index, all) => value.name === "김철수"; console.log(students.findIndex(findConditionWithArrow)); // 1
students를 순회하며 각각의 엘리먼트 요소(오브젝트)의 name 프로퍼티가 "김철수"인 엘리먼트를 찾을 경우 해당 엘리먼트의 위치 인덱스를 반환하며 findIndex()를 종료합니다.
여기서 만일 해당 요소를 찾지 못한다면 -1을 반환합니다.
그 외에 세 번째 파라미터로 this참조에 사용할 오브젝트를 전달하는 것 역시 find()와 동일합니다.
대체, 포함 여부
fill()
Array 오브젝트 내부의 값들을 파라미터 값들로 설정해주는 메소드입니다. 첫 번째 파라미터는 오브젝트 내부를 채워줄 값이며, 두 번째 파라미터와 세 번째 파라미터로 범위를 지정할 수도 있습니다.
주의할 점은 해당 메소드는 값을 대체하는 것이지 새로운 Array 오브젝트로 복사하는 것이 아니기에 원본 오브젝트가 유지되어야할 때는 복사한 뒤에 사용해야 합니다.
또한, fill()메소드는 Generic 함수이기 때문에 Array-like 오브젝트나 이터러블 오브젝트에서도 사용이 가능합니다. 반환값 역시 대상 오브젝트와 동일한 타입으로 반환됩니다.
const list = ["A", "B", "C"]; const like = {0:"A", 1:"B", 2:"C", length:3}; console.log(list.fill("범위X")); // 대체할 값 파라미터만 작성 console.log(list.fill("범위1", 1)); // 시작 인덱스 파라미터 작성 console.log(list.fill("범위2", 0, 2)); // 끝 인덱스 작성 console.log(Array.prototype.fill.call(like, "대체값", 1)); // Array-like 사용 // ["범위X", "범위X", "범위X"] // ["범위X", "범위1", "범위1"] // ["범위2", "범위2", "범위1"] // {0: "A", 1: "대체값", 2: "대체값", length: 3}
includes()
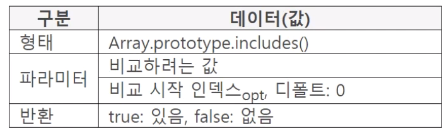
배열의 엘리먼트 사이에서 하나, 혹은 여러 값이 존재하는지 확인하고 싶을 때 사용하는 메소드입니다. 첫 번째 파라미터는 비교하려는 값을, 두 번째 파라미터는 비교 시작 인덱스지정할 수도 있습니다. 작성하지 않을 경우 0번째 인덱스를 default로 설정합니다.
또한, 제네릭 함수이기 때문에 Array-like나 이터러블 오브젝트도 사용 가능합니다.
const list = [10, 20, 30, 40, 50]; console.log(list.includes(10)); console.log(list.includes(70)); console.log(list.includes(10, 1)); const like = {0:"A", 1:"B", 2:"C", length:3}; console.log(Array.prototype.includes.call(like, "C")); console.log(Array.prototype.includes.call(like, "A", 1)); // true // false // false // true // false
배열 차원 전환
✔ ES2019 부터 사용이 가능합니다.
flat()

배열의 차원을 변환 후 새로운 배열로 설정하여 반환을 하는 메소드로 파라미터는 변환할 배열의 깊이(depth)를 작성하나 필수 파라미터는 아니며 작성하지 않을 경우 default는 1로 설정됩니다.
학생들 성적 배열이 있다고 할 때, 한 차원 더나가 학생들을 반으로 구분하여 학년의 그룹 혹은 학년도 그룹핑해서 학교 학생들의 성적으로 구분할수도 있죠. 이렇게 다양한 차원의 배열을 학년 구분, 혹은 반 구분없이 하나의 배열로 종합하여 순위를 매겨야 할 수도 있습니다.
const studentAvgs = [{name:"s1", avg:76}, [{name:"s2", avg:78}], [[{name:"s3", avg:96}]]]; const studentAvgByClass = [ [{name:"a1", avg:76, class:"one"}, {name:"a2", avg:86, class:"one"}, {name:"a3", avg:96, class:"one"}], [{name:"b1", avg:76, class:"two"}, {name:"b2", avg:88, class:"two"}, {name:"b3", avg:98, class:"two"}], [{name:"c1", avg:74, class:"three"}, {name:"c2", avg:84, class:"three"}, {name:"c3", avg:94, class:"three"}], ]; console.log(studentAvgs.flat()); //---(1) console.log(studentAvgs.flat(0)); //---(2) console.log(studentAvgs.flat(2)); //---(3) const list = [1, 2, 3, , , , , [4, 5]]; console.log(list.flat()); //---(4)
- console.log(studentAvgs.flat())
⇒ flat에 파라미터를 작성하지 않은 경우 기본값인 1로 설정되며 2차원 배열까지는 평탄화 한다는 의미로 요소 중에 [{name:"s2", avg:78}] 는 {name:"s2", avg:78} 이 되고 [[{name:"s3", avg:96}]]는 [{name:"s3", avg:96}]이 되어 [{name:"s1", avg:76}, {name:"s2", avg:78}, [{name:"s3", avg:96}]] 이 됩니다. - console.log(studentAvgs.flat(0))
⇒ 파라미터로 0을 넣게되면 1차원 배열까지 평탄화를 한다는 것인데, 차원을 변환하지만 반환할 때 배열에 설정되므로 결국 차원 변환없이 그대로 반환됩니다. - console.log(studentAvgs.flat(2))
⇒ 파라미터로 2를 넣으면 3차원 배열까지 평탄화를 하게 됩니다. 그렇기에 [[{name:"s3", avg:96}]] 도 {name:"s3", avg:96}로 평탄화되고 반환되는 값은 [{name:"s1", avg:76}, {name:"s2", avg:78}, {name:"s3", avg:96}]입니다. - console.log(list.flat())
⇒ 빈 엘리먼트는 삭제되어 유효한 엘리먼트만 설정되기 때문에 해당 인덱스가 비어있는 값일경우 무시되어 [1,2,3,4,5]가 반환됩니다.
flatMap()

flat()과 기본적인 목적은 같습니다. 다차원 배열을 차원변환으로 평탄화하는 것인데, 차이점이 있다면, flat()이 차원 변환만 한다면 flatMap()은 map()의 기능이 추가되어 map처럼 콜백함수를 실행하는 것입니다.
const list = [10, 20]; const change = (element, index, all) => element + 5; console.log(list.flatMap(change)); console.log(list.map(change)); // [15, 25] // [15, 25]
list의 각 값들을 순회하며 change 로직을 수행 후 반환되는 값으로 배열을 설정해 반환합니다. 여기까지만 보면 기존에 map() 메소드와 차이가 없습니다. 두 메소드간의 차이는 flatMap은 반환값이 배열일 경우 차원 변환(차원 감소)을 해서 반환합니다.
const list = [10, 20]; const change = (element, index, all) => [element + 5]; console.log(list.flatMap(change)); console.log(list.map(change)); // [[15],[25]] // [15, 25]
Array 이터레이터 오브젝트 생성
entries()

Array 오브젝트는 Array 이터레이터 오브젝트로 생성 및 반환이 가능합니다. 이는 Array 오브젝트가 이터레이터 프로토콜(Symbol.iterator 프로퍼티 포함)을 따르기 때문입니다.
entries()를 사용하면 배열의 엘리먼트를 [key, value] 형태로 반환하는데 여기서 key는 인덱스가되고, value는 값이 됩니다.
- 이터레이터 오브젝트 생성(next() 호출)
const iter = ["A", "B"].entries(); console.log(iter.next()); console.log(iter.next()); console.log(iter.next()); // {value: [0, "A"], done: false} // {value: [1, "B"], done: false} // {value: undefined, done: true}
- ["A", "B"].entries()
⇒ Array Iterator Object를 생성합니다. 여기서 오브젝트는 [key, value] 형태입니다. - iter.next()
⇒ next()를 호출하면 {value: [0, "A"], done: false} 이런식으로 출력되는걸 확인하실 수 있는데, 여기서 value에는 [key, value]형태의 값이 설정되어 있으며 done은 전개 완료 여부입니다.
⇒ false일 경우 아직 전개할 수 있다는 것이고, true이면 전개가 완료되어 더이상 next()를 호출할 수 없다는 의미입니다. done이 true일 때는 value도 undefined입니다.
- for-of 문으로 전개
const iter = ["A", "B"].entries(); for(const prop of iter) { console.log(prop); } // [0, "A"] // [1, "B"] const iter2 = ["C", "D"].entries(); for(const [key, value] of iter2) { console.log(`${key}: ${value}`); } // 0: C // 1: D
전개만 할 때는 next()를 사용하면서 값을 value에서 꺼내고 done으로 전개 여부를 검사하는 것은 불편합니다. 따라서, 연속해서 전개를 할 경우에는 for-of문을 사용하는 것이 편리합니다.
- for(const prop of iter){...}
- porp에 할당되는 값은 iterator 오브젝트인 iter의 value([key, value])가 할당됩니다.
- 값을 더 편하게 사용하기 위해 분할 할당을 사용할 수도 있습니다.
- for(const [key, value] of iter2){...}
- iter2이 순회하며 할당되는 값을 분해 할당하여 조금 더 편하게 사용할 수 있습니다.
-
이터레이터는 다시 반복할 수 없습니다.
const iter = ["C", "D"].entries(); for(const [key, value] of iter) { console.log(`${key}: ${value}`); } // 0: C // 1: D for(const [key, value] of iter) { console.log(`${key}: ${value}`); } // undefinedentries()와 iterator 오브젝트를 사용할때의 주의사항이기도 한데, 이터레이터 오브젝트는 끝까지 순회를 한 다음 다시 순회를 할 수 없습니다.
이터레이터 순회가 끝나면 그 뒤로는 next()를 아무리 호출해도 {value: undefined, done: true} 만 반환합니다.
keys()

keys() 메소드는 entries()와 로직은 동일하게 Array오브젝트를 Array 이터레이터 오브젝트로 생성 및 반환하는데 [key, value]형태가 아닌 key만 반환된다는 차이점이 있습니다. key 즉, 인덱스의 배열이 됩니다.
const iter = ["A", "B"].keys(); console.log(iter.next()); console.log(iter.next()); console.log(iter.next()); // {value: 0, done: false} // {value: 1, done: false} // {value: undefined, done: true}
생성한 Array Iterator 오브젝트는 [key]형태로 value에 인덱스가 설정됩니다. for-of를 사용하면 더 편하게 사용 가능하고 key만 할당되기에 따로 분할 할당을 할 필요가 없습니다.
values()

keys()와 동일하지만 value만 반환한다는 차이점이 있습니다. value의 배열이 됩니다.
const iter = ["A", "B"].values(); console.log(iter.next()); console.log(iter.next()); console.log(iter.next()); // {value: A, done: false} // {value: B, done: false} // {value: undefined, done: true}
역시 for-of로 전개가 가능하며 value만 할당되기에 분할할당을 할 필요가 없습니다.
- [Symbol.iterator]()를 사용하는 것과 동일
console.log(Array.prototype.values === Array.prototype[Symbol.iterator]); const iter = ["A", "B"][Symbol.iterator](); for(const prop of iter) { console.log(prop); } // true // A // B
Array.prototype.values 와 Array.prototype[Symbol.iterator]는 동일합니다. 그렇기 때문에 values()대신 [Symbol.iterator]()를 사용해도 결과는 동일 합니다.
값 연동
Array Iterator 오브젝트에서는 배열의 메모리 주소를 참조하기 때문에 값이 연동됩니다.
entries(), keys() 두 메소드 둘 다 값이 연동되어 값을 변경하면 연동되어 변경됩니다.
let list = ["A", "B"]; let iter = list.entries(); list[0] = "연동"; console.log(iter.next()); console.log(iter.next()); console.log(iter.next()); // {value: [1: 연동], done: false} // {value: [2: B], done: false} // {value: undefined, done: true}
