우리가 neural network를 돌릴때 데이터가 많이 없거나, 데이터가 깨끗하지 않을 때 어떻게 해야 되는지 알아보자!!
Data Preprocessing
데이터 전처리의 중요성과 다양한 기법에 대해 설명할 것이다.
1. zero-centering & Normalization
예를 들어 지도 학습에서 train data를 모아서 neural network를 학습시킬 때 data의 distribution이 skewed되어 있고, 잘 정리 되지 않은 경우가 있다.
이런 경우 model train하면 모델이 굉장히 noise하게 학습된다. 전처리는 정말 필수이다.(전처리를 하고 train을 하면 정말 많이 좋아진다.)
모든 입력값이 양수이면 sigmoid와 마찬가지로 gradient들이 다 같은 부호가 됨으로써 학습이 잘 안될 수 있다.
그래서 데이터에서 평균을 빼줌으로써 데이터의 분포를 zero-centering해주고, normalize하기 위해 표준편차로 나누어 준다.
(기본적으로 nn은 데이터 분포를 정규분포로 가정하기 때문에 데이터가 들어오면 꼭 데이터 정규화를 해줘야 한다. 컴퓨터 비전도 마찬가지!!!)
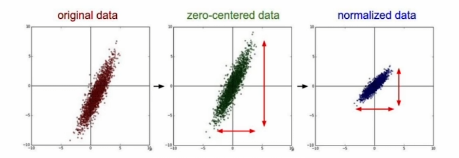
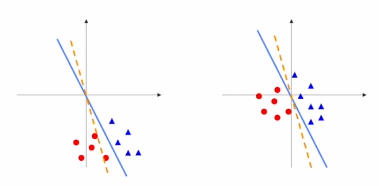
왜 굳이 zero를 중심으로 할까?
아래의 그림처럼
weight의 작은 변화에 덜 민감해진다.
optimize하기 쉬워진다.
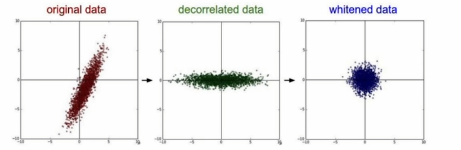
2. PCA & Whitening
분산이 큰 데이터의 경우에 분산 파라미터를 없애주고 데이터의 키가 되는 본질적인 특징만 표현할수 있도록 압축 시켜주는 기법이다.
PCA?
데이터의 차원이 클때 중요한(제일 데이터를 잘 설명하는) 차원만을 남기고 나머지는 날리려서 데이터를 압축하는 기법이다. neural network가 나오기 전에 엄청 자주 사용되던 기법이다.
pca는 데이터 분포 에서 가장 분산이 큰 축으로 rotate를 시켜 데이터가 0을 중심으로 분포하게 만든다.
whitening?
covariance 행렬을 만든다. 즉, 데이터 분포에다가 variance로 나눠줌으로써 정규분포를 따르도록 한다.
Data Augmentation
실제 우리가 이미지 분류 연구할 때 데이터 셋이 적을 때가 많다.
이때 우리는 데이터의 의미에 영향을 주지 않고, classifier의 task를 변형하지 않고 데이터를 변형시켜 늘리고 싶을 것이다. 큰 데이터 셋은 너무 비싸니깐 기존의 데이터를 최대한 활용하자에서 시작되었다.
컴퓨터 비전 분야에서 많이 사용된다.
데이터를 증강하는 법
이미지를 늘리는 방법은 다양하다
사진을 이동시키거나 아니면
원래 이미지를 조금 가리거나,
색깔을 바꾸기 등등 이 있다.
좀 노가다스럽지만 자주 사용된다.
NLP에서도 사용된다. 한 문장에서 한곳에 들어가는 단어를 바꿔가면서 학습하는것이다.

노이즈를 더하는 증강기법
Horizontal Flips
좌우반전, 상하반전을 주었을때도 모델이 같은 class로 분류하게 하기 위해 나온 기법이다.
우리가 데이터를 여러 방향을 뒤집어서 학습시키는 것이다.
but 하지만 수직으로 뒤집는 경우 의미가 왜곡될 수 있으니 조심해야한다.

Random Crops
이건 진짜 노가다스러운 기법이다 ㅋㅋㅋ
이 기법은 모델이 사진의 일부분만 보더라도 클래스를 잘 맞추게 하는 기법이다.
그래서 사진을 랜덤하게 크롭하여 train data를 늘리는 것이다.(즉 모델이 translation invariance하기를 원한다.)
translation invariance : 몇개의 픽셀만 이동하더라도 두개의 이미지를 비슷하다고 인식하는 것
사진 이외에도 다양한 유형의 데이터에도 적용된다.(audio,text,video,sequence..)

Scaling
이미지의 크기에 관계 없이 물체가 잘 인식되어야 한다.
그래서 다양한 크기의 이미지를 넣어 무작위로 크롭한 이미지를 훈련 이미지로 사용할 수 있다.

scaling과 random crops 사용예시
- train
이미지가 256x480이라면
짧은 길이인 256보다 좀더 작은 사이즈의 정사각형 패치를 무작위로 샘플링한다. - test
이미지의 크기를 5개의 사이즈로 조정후 224*224이미지 10개를 크롭하여 분류 진행
scaling과 random crops를 사용하면 이미지를 정말 많이 늘릴 수 있다.
Color Jitter
빛이나 다른 요인들에 의해 색깔은 다르게 보일 수 있다. 요인들의 변화를 주고 학습시키는 것이다.
포토샵을 한다고 생각하면 된다.
이렇게 학습 시키면 빛에 의해 바뀐 사진들도 잘 골라내는 견고함을 보여준다.

그외의 증강기법
문제와 데이터의 영역에 따라 사용하는 방법이 정말 다양하다.
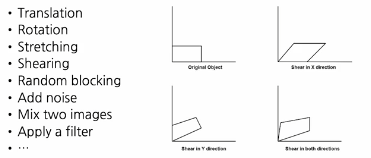
이런 다양한 증강을 사용하면 모델이 더 견고해진다.
