모델을 학습시키기 위해서는 data가 필수적이다.
실제로 pytorch로 모델 구성 및 학습하는 과정에서 가장 큰 비중을 차지하는 것은 모델에 데이터를 공급해주는 일이다.
(딥러닝에서 가장 중요한 것을 신경망 모델링이 아닌 데이터를 준비하는 단계라고 해도 과언이 아니다.)
가독성, 모듈성을 위해 학습코드와 데이터셋 코드를 분리하는 것이 좋다.
즉, 모델링과 별도로 유지해야 한다. 데이터를 쉽게 불러와주고, 코드의 가독성도 좋은 도구가 있다면 얼마나 편리하겠는가
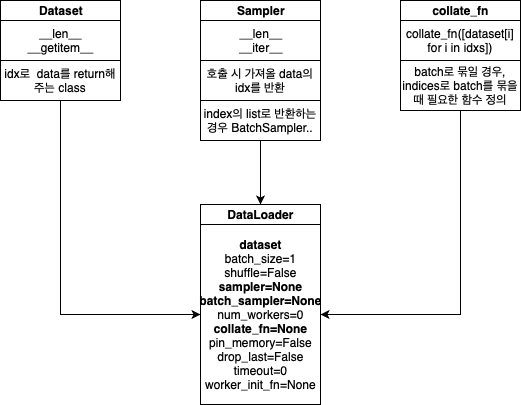
그래서 pytorch에서는 데이터 처리를 위한 2가지 클래스를 제공한다.
Dataset
대부분의 머신러닝, 딥러닝 학습에서는 방대한 데이터를 이용하여 분석하기 때문에 데이터를 한번에 잘 불러오지 않는다. 따라서 데이터를 하나씩 불러오는 방식을 이용해야 한다.
그러기 위해서는 전체 data를 tensor로 구성하는 dataset(dataloader를 통해 data를 받아오는 역할)을 상속받아 나만의 dataset을 만들어야 한다.
사용자 정의 Dataset 클래스는 반드시 3개 함수를 구현해야 한다.
- init
- len
- getitem
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self):
super (CustomDataset,self).__init__()
def __len__(self): ## x와y의 개수가 같으니깐 아무거나로 return해주면 된다.
def __getitem__():DataLoader
Dataloder는 배치 관리 담당으로써 batch기반의 딥러닝모델 학습을 위해서 mini batch를 만들어주는 역할을 한다. 앞서 만들었던 dataset을 input으로 넣으면 여러 옵션을 통해 mini-batch를 만든다.
iterator 형식이고 우리가 batch_size나 shuffle 유뮤를 설정할 수 있다.
train일때 셔플을 하고 test를 할 때는 shuffle하지 않는다.
from torch.utils.data import Dataloader
dataloader = Dataloader(
dataset,
batch_size = 2,
shuffle = True,
)
dataloader에 있는 자주 쓰이는 옵션들을 알아보자
-
batch_size : 각 배치 때마다 그 배치 안에 샘플의 사이즈
-
shuffle : epoch마다 데이터를 섞을지 말지 정하는 것
-
num_workers : 동시에 처리하는 프로세서의 수, 서버에서 돌릴 때는 num_worker를 조절해서 load속도를 올릴 수 있지만 pc에서는 default=0으로 설정해야 한다.(기본적으로 num_worker를 하나 추가하면 데이터를 불러오는 속도는 20% 증가한다.
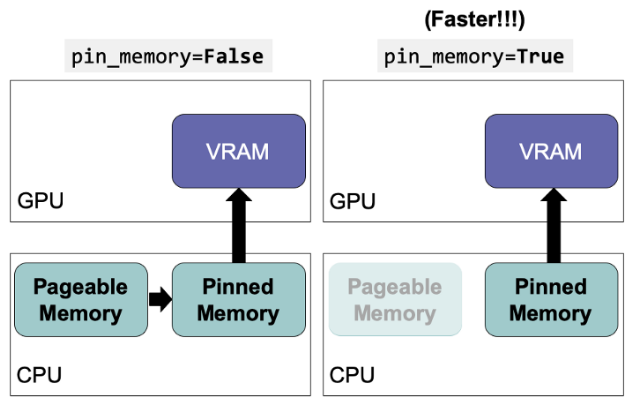
- pin_memory : 우리가 일반적으로 분석하면 CPU+RAM을 이용하여 변수를 DRAM에 할당시킨다. 이때 GPU로 하고자 하면 GPU는 DRAM에 있는 데이터를 사용하지 못해서 GPU 전용 메모리인 VRAM으로 데이터를 옮겨야한다. 그때 pinned memory를 사용하게 된다. 하지만 이러한 과정을 다 거치면 너무 느려지게 된다. 그래서 pin_memory=True를 하면 DRAM을 거치지 않고 바로 VRAM으로 이동한다.
** pin_memory를 사용한다고 해서 .to(device)작업을 생략해서는 안된다. pin_memory는 전송 속도를 올려주는 것 뿐 저장해주지는 않는다.
- collate_fn : 이 파라미터를 사용하면 별도의 데이터 처리 함수를 만들 수 있으며 해당 함수 내의 처리를 데이터가 출력되기 전에 적용된다. 기본적으로 default_collate는 dataset에서 반환하는 데이터를 (x_batch,y_batch)와 같은 배치로 결합하려고 한다. collate_fn을 이용해 사용자 지정 배치 처리를 지정할 수 있다.
