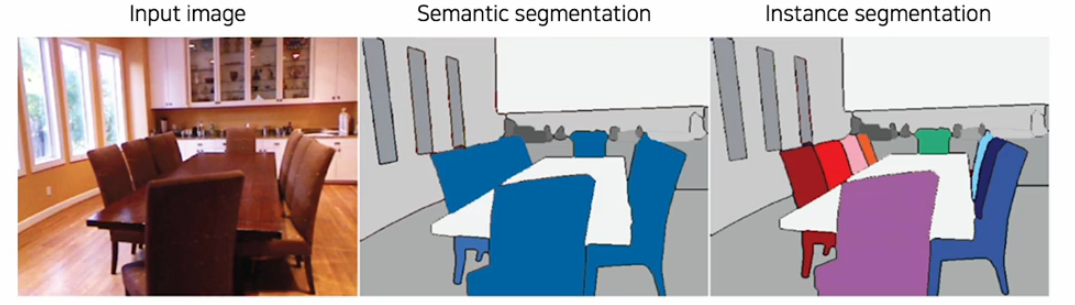
Instance segmentation
sematic segmentation은 각 픽셀이 어떤 category에 속하는지 알 수 있고 분류해준다. 각각의 instace를 구분해 주지 않는다.
그와 달리 instace segmentation은 각각 개별적인 instance들을 모두 분류하고 각 인스턴스 어떤 카테고리에 속하는지도 따로 분류해준다.(좀더 종합적인 segmentation)
각각의 instace들을 segmentation하기 위해서는 개별 물체를 먼저 탐지해서 구분하는 작업이 선행 되어야 한다.
개별 instance를 구분하는 가장 확실한 방법은 object detection이다.
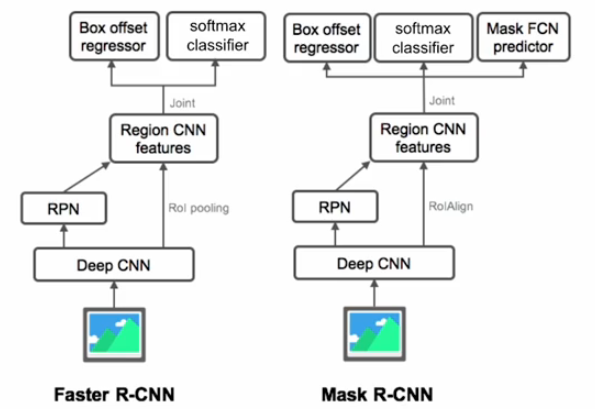
Mask R-CNN
mask r-cnn은 fater r-cnn에서 발전된 모델이다.
차이는 mask r-cnn은 RoI pooling에서 개선된 RoIAlign을 사용한다.
또한 mask FCN predictor가 추가되었다.
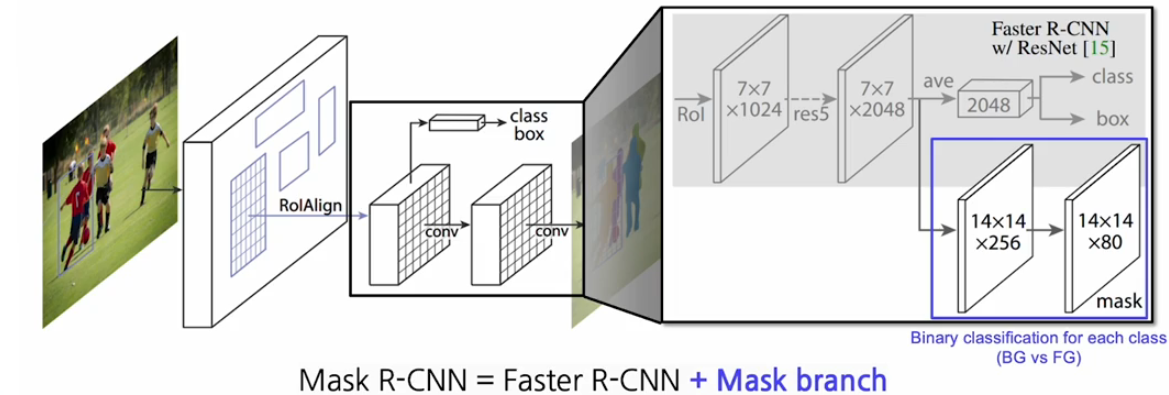
학습 과정
-
faster r-cnn과 유사하게 image network를 통해서 feature를 extraction한다.
-
그 때 RoIAlign을 사용하여 좀더 정교한 형태의 plotting point 위치까지도 고려하여 feature를 추출한다.
-
각각의 RoI마다 feature를 뜯어낸 그 위에서 class와 bounding box에 대한 ruff한 estimation을 하고 그 위에다가 mask를 prediction하는 head를 추가한다.
mask head를 보면 80개의 채널로 이루어져 있다. 그 의미는 80개의 클래스를 다루고 있는데 각각의 channel마다 각 클래스에 해당하는 binary mask가 들어 있다고 생각하면 된다.
그래서 각 채널은 background와 foward ground를 클래스별로 구분하는 mask map이다!!
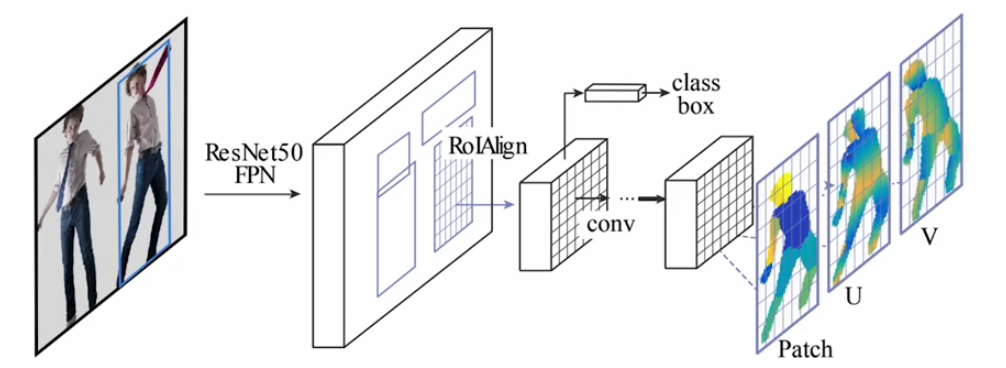
DensePose R-CNN
Mask R-CNN은 mask r-cnn 구조로써 instace segmentation을 수행한 의미 뿐만 아니라 일반적인 semi-dense-task에 대해서 쉽게 확장할 수 있다.
사람의 특성화된 3D 포즈 추정하는 그런 형태의 모델로도 확장이 되기도 했다.
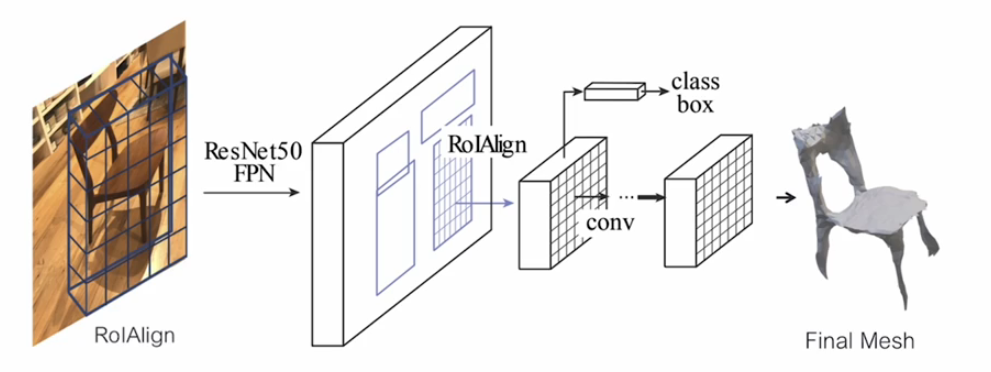
Mesh R-CNN
또다른 확장으로는 instance segmentation뿐만 아니라 3D Mesh까지 바로 prediction하는 Mesh R-CNN구조로도 확장이 되었다.
Mesh R-CNN은 2D 이미지 기반의 3D 메쉬 추정 문제를 해결하는 강력한 모델로, 3D 형상 복원 및 재구성에 매우 유용한 도구입니다.
이처럼 Mask R-CNN이라는 굉장히 유용한 디자인 패턴에 의해서 head만 디자인 해주면 여러가지 application으로 확장하기 굉장히 용이하다
Transformer-based method
최근에 transformer기반의 발전된 디자인들도 나오기 시작했다.
transformer의 성공에 힘입어서 vision task에서도 많이 적용되기 시작했다.
이전에 배운 VIT 외에도, DeiT,MaskFormer,DETR 등 detection,segmentation transformer도 등장하기 시작했다.
DETR
end-to-end object detection with transformer로 처음으로 detection부분에 트랜스포머를 적용한 구조이다.
이 구조는 object detection문제를 direct한 set prediction문제로 바꾼 것이 핵심이다.
기존의 region proposal network를 사용하는 방법들은 region proposal이 중복적으로 많이 나오기 때문에 non-maximum suppresion이라는 알고리즘을 통해 dominent하지 않은 bounding box들은 제거해주고 merge해주는 별도의 process가 필요했다.
object detection을 transformer로 하게 되면서 non-maxiumum suppresion도 모델 내로 들어오게 되었다.
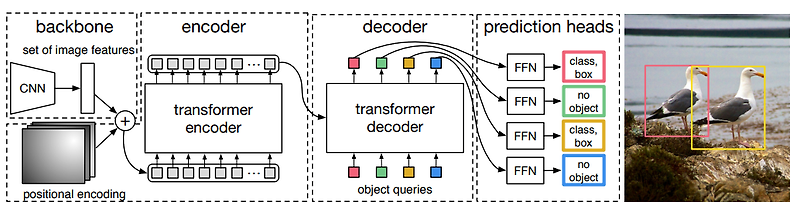
DETR은 trnasformer의 encoder,decoder를 사용했다.
일단 앞단에 CNN을 통해 feature를 encoding하면 transformer가 좀더 processing하고 decoder를 통해 object detection을 하는 과정이다.

DERT 학습과정
-
backbone 구조는 기본적으로 convoluntion neural network를 이용해서 feature extraction을 한다.
(extraction을 하면 공간 축의 정보도 남아 있는 형태(CxHxW)의 feature map이 생성되게 된다.) -
이렇게 주어진 feature map에 positional encoding을 더해준고 transformer로 전달한다.
(이전에 VIT에서도 더해줬던거 기억하지??) -
positional encoding이 더해진 feature map을 transformer encoder가 입력으로 받는다.(dxHW 토큰 형태로 구성해서 넣어준다.)
-
encoder에서는 self-attention을 통해 이 feature들의 관계성을 종합적으로 다 살핀다. dense한 관계를 모두 고려하여 feature를 더 강화하한다.
-
decoder에서는 feature가 주어졌을 때 그 feature에서 어떤 object가 어디에 있는지를 물어보는 형태로 구현되어 있다.
object query를 물어보면 feature를 참고를 해서 prediction을 만들게 된다.특징으로는 이 모델은 "auto regressive한 형태로 출력이 그 다음 입력으로 들어가는 형태"가 아니라 각각의 n개의 object쿼리를 설정을 해놓고 이 쿼리들이 동시에 parrel하게 들어가서 feature를 참고해 각각의 쿼리에 대한 결론을 도출한다.
-
그렇게 답변된 것을 갖고 와 Feed Foward network를 통해서 최종적으로 class와 bounding box형태로 decoding한다. 그때 object 개수보다 많은 object query개수로 학습을 하여 object가 아닌 것은 no object로 표현하게 된다.
DETR LOSS
DETR은 object detection문제를 set prediction 문제로 다시 해석한 연구인데, 그래서 출력결과가 한번에 순서없이 예측되어 나온다.
각각의 object query가 어떤 것인지 해석가능하지 않고 자동으로 학습되는 것이기 때문에 어떤 출력의 순서를 정하거나 출력을 유도하기가 어렵다.
그래서 굳이 유도하지 않고 set prediction형태로 출력하고 loss를 추정할때 각각의 label과 매칭을 그때마다 하면서 loss를 적용한다.
이때는 매칭하는 방법이 Bipartite matching이다. 결국에 2개의 set이 있을 때 각각의 matching을 찾는 방법중에 하나이다. bounding box prediction에 대한 set과 ground truth label에 대한 set이 있으면 그것을 각각 매칭을 하는 것이다.
그냥 하나하나 개별적으로 매칭을 하게 되면 중복이 발생할 수 도 있다. 이런 중복매칭을 방지하면서 개별적으로 하나씩 대응하게 매칭을 찾는 알고리즘이라고 생각하며 된다.
그렇게 매칭된 label데이터와 loss를 계산을 해서 최종적으로 학습하게 된다.

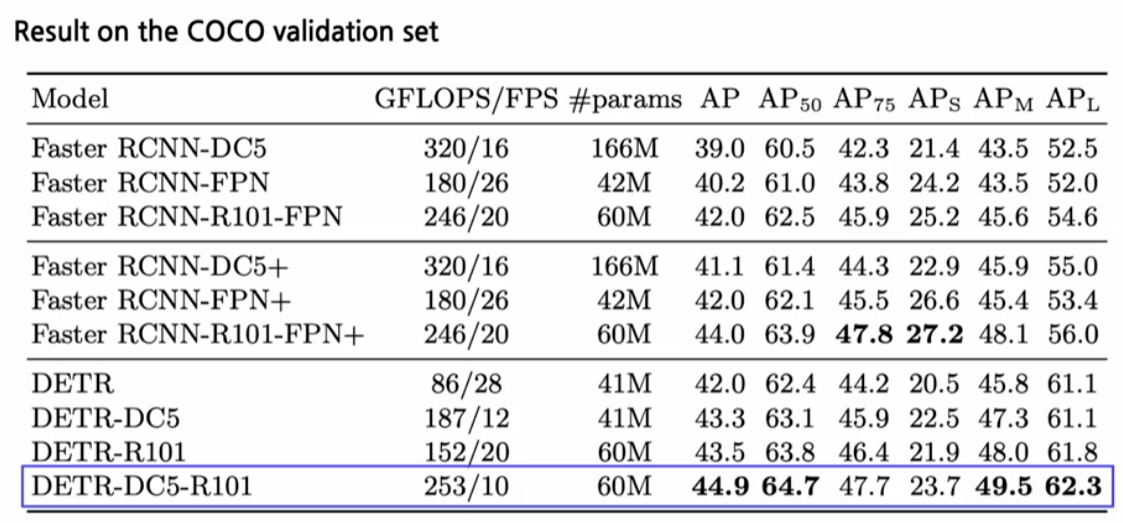
DETR 성능
DETR 결과를 보면 기존과 대비해서 향상된 성능을 볼 수 있다.
특히 큰데이터 일때() 성능개선이 명확하다.
MaskFormer
maskformer는 detection뿐만 아니라 segmentation분야에서도 transformer를 사용하기 시작하면서 나온 모델이다.
maskformer에서도 DETR처럼 binary mask의 set을 prediction하는 과정을 진행한다.
key insight는 sematic이나 instance level segmentation을 개별적으로 보는게 아니라 우리가 mask classification으로 하나로 prediction을 하더라도 충분히 이 2개의 서로 다른 task를 하나의 모델로 구성할 수 있다는 것이다.
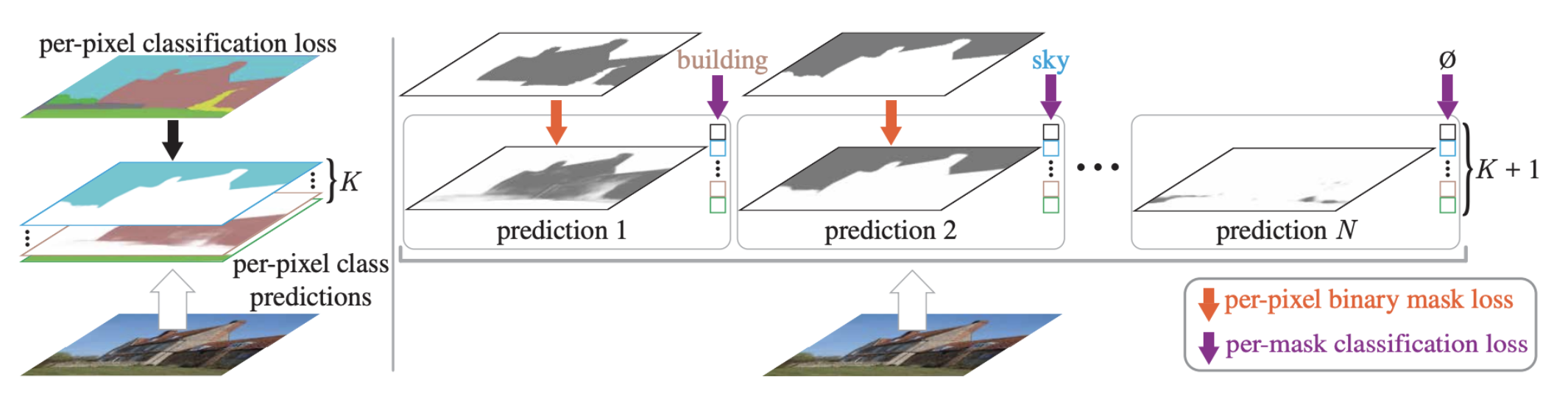
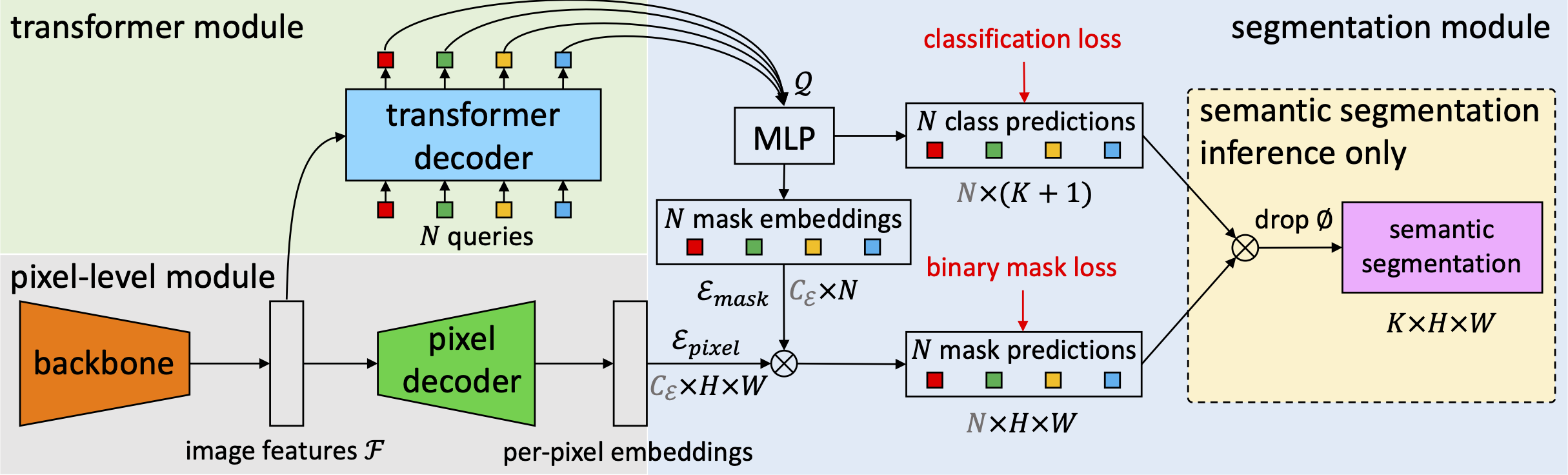
학습 과정
-
maskformer의 학습과정은 backbone network로 구성이 되어서 feature를 extraction한다.
-
이 추출한 feature를 high resolution하게 강화된 feature로 뽑기 위해서 pixel decoder라는 또 다른 모듈을 배치하게 된다. 그것을 통해 per pixel embedding을 하게 된다.
-
backbone에서 나온 feature map이 transformer decoder로 들어가게 된다.(이때 decoder는 DETR과 유사하게 되어 있다.)
이전에 넘어온 feature를 cross attention으로 referring을 해서 최종적인 prediction을 만들게 된다.
이때 prediction은 특정 object가 이 이미지 상에 있는지를 물어보는 형태의 query라고 생각해! -
그 prediction 결과를 MLP를 거쳐서 최종적으로 classificaiton을 수행하는 형태로 decoding이 일어난다.
-
class decoding과 병렬적으로 mask embedding 형태로도 trnasform이 된다.
mask embedding은 어떤 key로써 feature하고 내적을 수행함으로써 각각 binary mask로 decoding 된다.
(mask embedding은 object query로부터 최종적으로 마스킹 embedding 형태로 transform되는데 주어진 이미지 feature에서 영상내의 어떠한 물체가 있는지 그리고 내가 어떤 물체에 focus해야하는지가 embedding되어 있다.) -
이렇게 decoding된 binary mask와 classfication vector를 이용해서 우리가 crossentropy loss,binary mask loss를 측정하게 된다.
이때 binary mask와 classfication loss도 DETR처럼 set-prediction으로 나오기 때문에 서로 잘 매칭되어서 loss를 구한다.

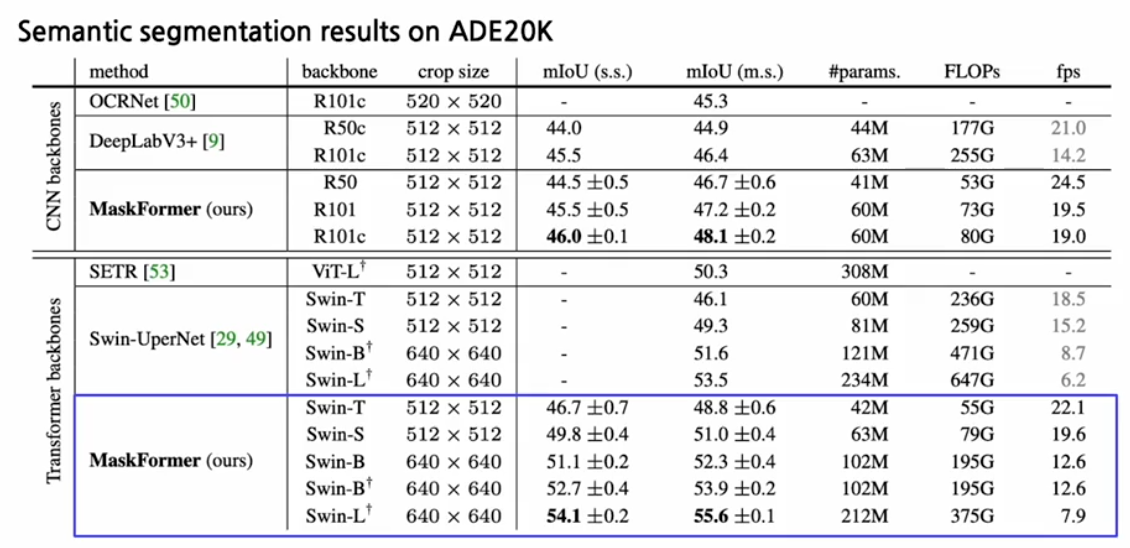
mask former 성능
기존 방법들 대비해서 훨씬 더 적은 flops에서 더 높은 성능을 달성하는 것을 확인할 수 있다.
같은 계열의 모델에서 flops를 더 사용하면 사용할수록 더 높은 성능을 보인다는 게 일반적인 경향이었는데 MaskFormer가 이런 경향을 엎어버렸다!