Serving이란?
- Production(Real World) 환경에 모델을 사용할 수 있도록 배포하는 것
- ‘머신러닝 모델의 서비스화’
- 모델을 연구하는 환경 이후에 진행되는 작업
- Input을 Model에게 주입하면 모델이 Output을 반환
- Model은 머신러닝 모델, 딥러닝 모델, LLM 등 다양할 수 있음
예시
- 유튜브 개인화 추천 알고리즘
- DeepL 번역기(input -> output)
- 기업에서 ai기반으로 작동하는 시스템
Serving의 종류
Serving의 종류는 크게 2가지 방식을 많이 활용
1) Batch Serving
실시간 응답이 중요하지 않고 대량의 데이터를 처리하거나 정기적인 일정으로 수행하고 싶을 때 사용하는 방식이다.
- Batch : 일괄, 묶음
- 데이터를 일정 묶음 단위로 서빙(예 : 14시~15시 사이에 생성된 데이터)
예시) 정기배송, 매년 단위로 바뀌는 미슐랭?
2) Online(Real Time) Serving
실시간 응답이 중요하고 개별 요청에 맞춤 처리 및 동적인 데이터에 대응할 상황일 때 사용하는 방식이다.
- Online : 연결, 실시간
- 클라이언트가 요청할 때 서빙(예 : API Request)
- 요청할 때 데이터를 같이 제공
예시) 번역, 유튜브 추천 시스템, 은행 사기 탐지(실시간으로 바로 탐지)
머신러닝 디자인 패턴(serving 패턴)
소프트웨어 개발 분야에도 패턴이 존재 => 디자인 패턴
소프트웨어의 구조, 구성 요소의 관계, 시스템의 전반적인 행동 방식
- 과거부터 문제를 해결한 사람들이 반복된 내용을 패턴으로 정리
- 코드의 재사용성, 가독성, 확장성 등을 향상시키기 위한 목적으로 도입
- 주로 객체 지향 프로그래밍에서 사용되지만 다른 프로그래밍 패러다임에서도 유용
- 개발 과정의 커뮤니케이션에서 이런 패턴을 사용하기도 함
제일 간단한 Serving 4가지 패턴
Batch Serving
- 1) Batch 패턴
Online Serving
- 2) Web Single 패턴
- 3) Synchronous 패턴
- 4) Asynchronous 패턴
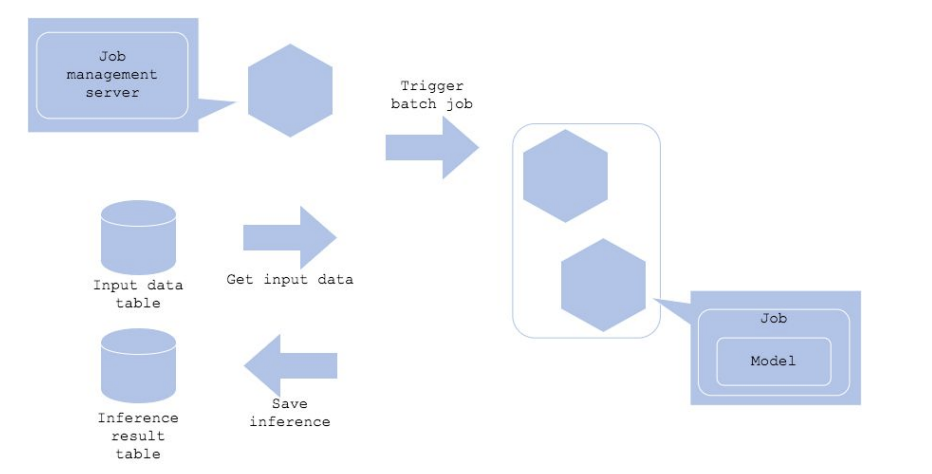
batch pattern
가장 간단하고 최대한 적은 비용으로 운영 환경에 배포하고 싶은 상황일 때 사용
-
job management server
작업을 실행하는 서버(Apache Airflow 등을 주로 사용)
특정 시간에 주기적으로 Batch Job을 실행시키는 주체 -
장단점
기존에 사용하던 코드를 재사용 가능하고 API 서버를 개발하지 않아도 되는 단순하다.
별도의 스케줄러(예 : Apache Airflow) 필요하다는 단점이 있다.
[참고사이트] https://mercari.github.io/ml-system-design-pattern/
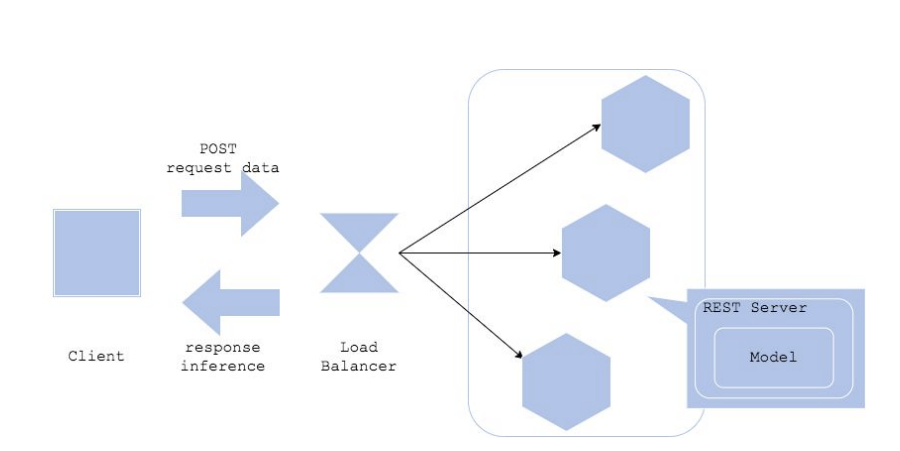
Web single pattern
Batch 패턴으로 서빙하면, 결과 반영에 시간 텀이 존재
모델이 항상 Load 된 상태에서 예측을 해주는 API 서버를 만들고,
추천 결과가 필요한 경우 서비스 서버에서 이 예측 서버에 직접 요청하는 패턴
- 과정
client가 요청하면 앱이 서비스 서버에 요청하고 서비스 서버가 예측하여 client에 전달한다. - load balancer
트래픽을 분산시켜서 서버에 과부하를 걸리지 않도록 해줌 - 장단점
보통 하나의 프로그래밍 언어로 진행하며 아키텍처의 단순하다.
그러나
구성 요소 하나(모델, 전처리 코드 등)가 바뀌면 전체 업데이트가 필요하고
요청 처리가 오래 걸리는 경우, 서버에 부하가 걸릴 수 있다.
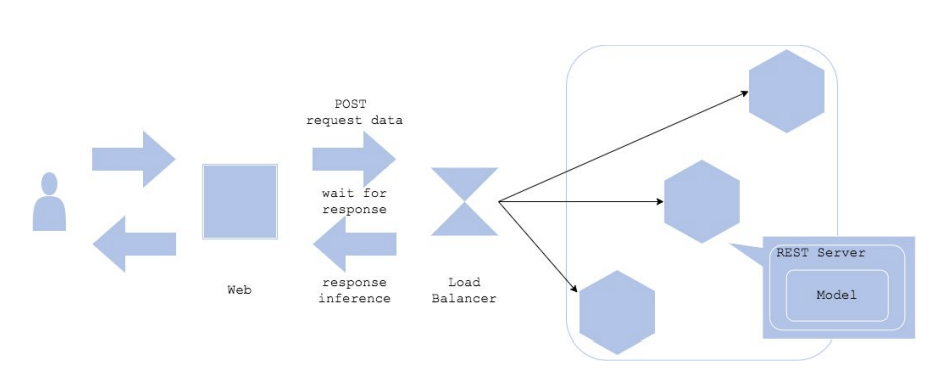
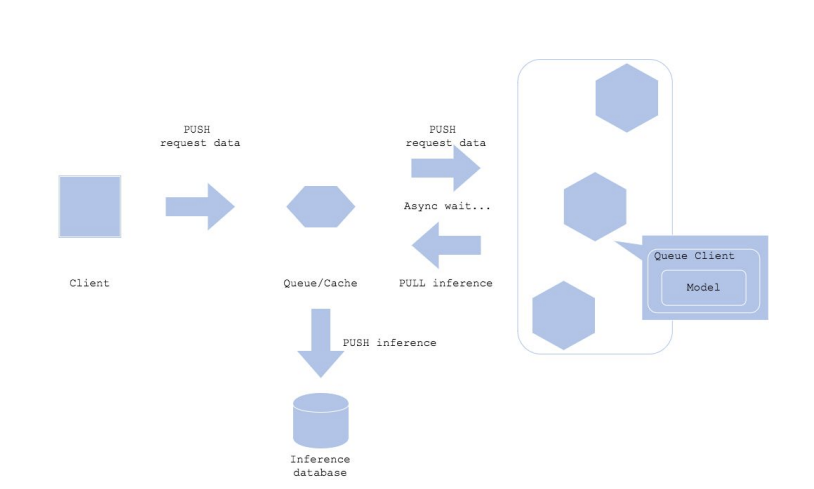
Synchronous 패턴/ Asynchronous 패턴
-
Synchronous 패턴
앞에서 설명한 Web Single 패턴을 동기적(Synchronous)으로 서빙
기본적으로 대부분의 REST API 서버는 동기적으로 서빙클라이언트는 API 서버로 요청을 한 뒤 이 요청이 끝날 때까지 기다려야 한다.
그래서 요청이 몰리면 병목현상이 될 수 있다.
-
Asynchronous 패턴
하나의 작업을 시작하고, 결과를 기다리는 동안 다른 작업을 할 수 있음
작업이 완료되면 시스템에서 결과를 알려줌예측을 기다릴 필요가 없다.
Queue
클라이언트와 예측 서버 사이에 메시지 시스템(Queue)을 추가
대표적인 메시지 프레임워크 : Apache Kafka
지하철 물품 보관소와 유사한 역할
Anti pattern
이렇게 짜면 좋지 않다는 패턴들의 예시이다.
-
Online Bigsize 패턴
실시간 대응이 필요한 온라인 서비스에 예측에 오래 걸리는 모델을 사용하는 경우
예) 서버가 실행되는데 몇 분씩 소요되고, 요청에 대해 응답이 몇 초씩 걸릴 경우문제
일반적으로 Bigsize 모델은 배포할 때 서버 실행과 서빙이 느림
속도와 비용 Tradeoff를 조절해 모델 경량화하는 작업이 필요대안
실시간이 아닌 배치로 변경하는 것도 가능한지 검토
중간에 캐시 서버를 추가하고, 전처리를 분리하는 것도 Bigsize를 탈피하는 방법 -
All-in-one 패턴
하나의 서버에 여러 예측 모델을 띄우는 경우라이브러리 선택 제한이 존재함
