tensor의 indexing과 slicing
- 1-D tensor : 어려운것 없이 기존의 numpy,list에서의 인덱싱, 슬라이싱과 같다.
- 2-D tensor : d[행,열]로 지정해준다.(numpy 와 동일)
또한 슬라이싱도 numpy와 유사한데 1번째 행을 찾고 싶을 때 텐서는 d[1,:] or d[1,...]으로 표시 할수 있다.
** 여기서 꿀팁 2차원 행렬에 젤 오른쪽 구석에 있는 것을 인덱싱 할때 차원의 크기를 잘 모를때 그냥 d[-1,-1]해주면 된다는 것을 잊지 말자!
tensor의 기초연산
- 더하기연산
크기가 같은 두 텐서의 더하기는 torch.add(a,b) 이때 추가적인 메모리를 할당하기 때문에 메모리주소는 a,b와 다르다.
in-place 방식(a.add_(b))을 활용하여 더하기 연산을 할 수도 있다. 이 방식은 추가적인 메모리 할당하지 않아 절약할 순 있지만 autograd와의 호환성 문제가 생길 수 있다. 자주 사용되지만 신중하게 써야함
** 크기가 다르면 아래와 같이 연산한다.
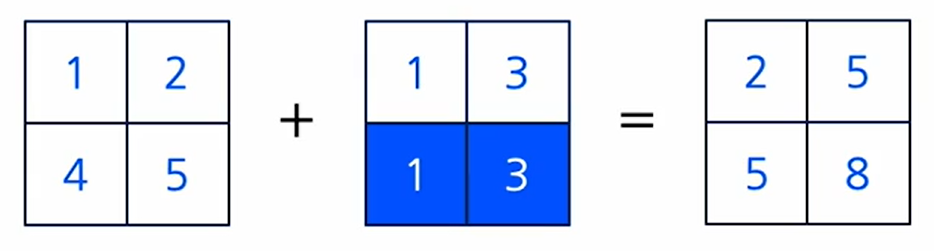
-
빼기 연산
torch.sub(a,b) or in-place방식인 a.sub_(b)으로 뺄셈을 할 수 있다.
크기가 다른 두 tensor의 빼기도 덧셈과 마찬가지로 수행한다. -
스칼라 곱 연산
스칼라 i와 2차원 텐서 j를 곱할 때 torch.mul(i,j)로 수행하며 각각의 텐서 요소에 스칼라가 곱해진다. -
요소별 곱 연산
크기가 같은 두 텐서의 곱 연산은 torch.mul(k,l) or k.mul_(l) (in-place 방식)으로 진행 할 수 있고, 넘파이 곱 연산과 동일하게 작동된다.
크기가 다르다면 덧셈처럼 그 빈공간을 확장한 후에 진행된다. -
요소별 나누기 연산
크기가 같다면 torch.div(a,b) or a.div_(b) (in-place 방식)로 진행
크기가 다르면 위의 연산들과 동일 -
요소별 거듭제곱 연산
tensor s의 요소들을 n제곱 해주고 싶다면 torch.pow(s,n)!
tensor a에 대응되는 tensor b의 요소만큼 각각 거듭제곱을 시켜줄 수도 있다. torch.pow(a,b) or a.pow_(b) (in-place 방식)
거듭제곱근도 마찬가지로 torch.pow(s,1/n)으로 해결할 수 있다.
-
비교연산
tensor v와 tensor w의 대응 요소들이 같은지 확인 하고 싶다면 torch.eq(v,w)
tensor v와 tensor w의 대응 요소들이 다른지 확인 하고 싶다면 torch.ne(v,w)
tensor v이 tensor w의 대응 요소들보다 큰지 확인 하고 싶다면 torch.gt(v,w)
tensor v이 tensor w의 대응 요소들보다 크거나 같은지 확인 하고 싶다면 torch.ge(v,w)
tensor v이 tensor w의 대응 요소들보다 작은지 확인 하고 싶다면 torch.lt(v,w)
결과값은 boolen type tensor로 출력된다. -
논리연산
x=torch.tensor([True,False])
y=torch.tensor([True,False])
1) and(논리곱) 연산
torch.logical_and(a,b)
2) or(논리합) 연산
torch.logical_or(a,b)
3) xor(베타적 논리합) 연산
둘다 참이어도 거짓이어도 안됨 하나만 참이어야됨
torch.logical_xor(x,y)
